

GLM-5 是 Zhipu AI 推出的新一代开放权重、以智能体为中心的基础模型,面向长时程编码与多步智能体。它可通过多种托管 API(包括 CometAPI 与供应商端点)以及附带代码与权重的研究发布版本获取;你可以使用兼容 OpenAI 的标准 REST 调用、流式传输与 SDK 进行集成。
Z.ai 的 GLM-5 是什么?
GLM-5 是 Z.ai 的第五代旗舰基础模型,面向智能体工程:长时程规划、多步工具使用与大规模代码/系统设计。于 2026 年 2 月公开发布,GLM-5 采用 Mixture-of-Experts(MoE)架构,总参数约 ~744 billion,每次前向传递的活跃参数约 40B;其架构与训练选择优先保证长上下文一致性、工具调用能力与面向生产负载的高性价比推理。这些设计让 GLM-5 能在超长输入下保持上下文,同时运行扩展的智能体工作流(例如:浏览 → 规划 → 编写/测试代码 → 迭代)。
关键技术亮点:
- MoE 架构:总参数 ~744B / 活跃参数 ~40B;扩大预训练规模(报告 ~28.5T tokens)以缩小与前沿闭源模型的差距。
- 长上下文支持与优化(深度稀疏注意力,DSA),相较于朴素的致密扩展降低部署成本。
- 内建智能体特性:工具/函数调用、有状态会话支持与集成输出(可在供应商 UI 的智能体工作流中生成
.docx、.xlsx、.pdf等产物)。 - 开放权重可用(权重发布至模型平台)与托管访问选项(供应商 API、推理微服务)。
GLM-5 的主要优势是什么?
智能体规划与长时程记忆
GLM-5 的架构与调优重视跨工作流的一致多步推理与记忆,适用于:
- 自主智能体(CI 流水线、任务编排器),
- 大型多文件代码生成或重构,和
- 需要保留长历史的文档智能。
超大上下文窗口
GLM-5 支持非常大的上下文长度(根据已发布模型规格约 ~200k tokens),让你在一次请求中保留更多会话内容,减少许多用例中对激进切分或外部记忆的需求。(见下方对比图。)
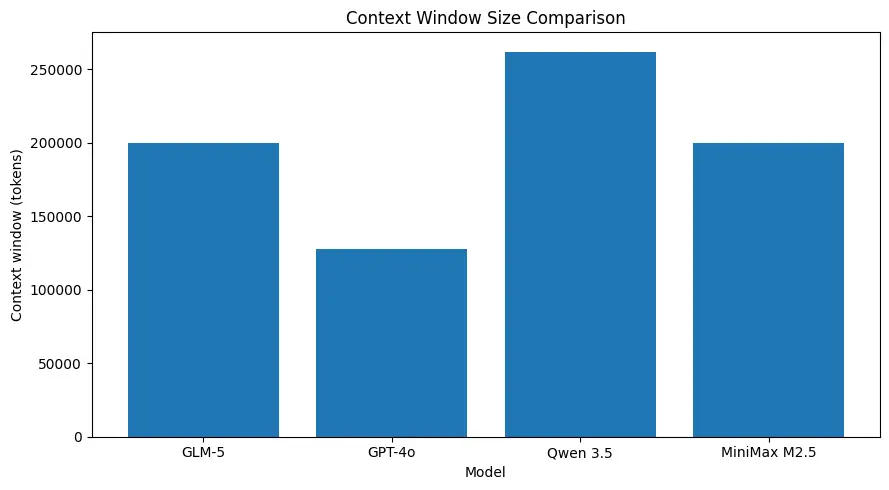
面向系统级任务的强编码能力
GLM-5 在软件工程基准上报告为开源模型中的领先表现(SWE-bench 与应用代码 + 智能体套件)。在 SWE-bench-Verified 上报告约 ~77.8%;在编码/终端式智能体测试(Terminal-Bench 2.0)上得分集中在 50% 中段——显示其实用编码能力接近前沿专有模型。这些指标意味着 GLM-5 适用于代码生成、自动重构、多文件推理与 CI/CD 助手等场景。
成本/效率权衡
由于采用 MoE 与“稀疏”注意力创新,GLM-5 旨在在相同能力下相较于粗暴的致密扩展降低单位推理成本。CometAPI 提供具竞争力的价位,使 GLM-5 对高吞吐的智能体工作负载颇具吸引力。
如何通过 CometAPI 使用 GLM-5 API?
简言之:将 CometAPI 视作兼容 OpenAI 的网关——设置基础 URL 与 API Key,选择 glm-5 作为模型,然后调用 chat/completions 端点。CometAPI 提供 OpenAI 风格的 REST 接口(如 /v1/chat/completions),并提供 SDK 与示例项目,便于无缝迁移。
下面是面向生产的实用手册:认证、基本对话调用、流式、函数/工具调用与成本/响应处理。
访问 GLM-5(通过 CometAPI)的基本步骤:
- 在 CometAPI 注册并获取 API Key。
- 在 CometAPI 的目录中找到 GLM-5 的精确模型 ID(根据列表为
"glm-5")。 - 向 CometAPI 的 chat/completions 端点(OpenAI 风格)发送带认证的 POST 请求。
基础细节(CometAPI 模式): 平台支持 OpenAI 风格路径(如 https://api.cometapi.com/v1/chat/completions)、Bearer 鉴权、model 参数、system/user 消息、流式,以及文档中的 curl/Python 示例。
示例:使用 Python(requests)快速进行 GLM-5 对话补全
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
示例:curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
流式响应(实用模式)
CometAPI 支持 OpenAI 风格的流式(SSE/分块)。在 Python 中最简单的方式是请求 "stream": true 并迭代接收的数据块。这在需要低延迟的部分输出时很重要(构建实时开发助手、流式 UI)。
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
参考:OpenAI 风格的流式协议与 CometAPI 兼容性文档。
函数/工具调用(如何调用外部工具)
GLM-5 支持与 OpenAI/聚合器约定兼容的函数或工具调用模式(网关会在模型响应中传递结构化函数调用)。示例用法:让 GLM-5 调用本地 “run_tests” 工具;模型会返回你可解析与执行的结构化指令。
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
当模型返回 function_call 负载时,请在服务端执行该工具,然后将工具结果以 "tool" 角色的消息回传,并继续会话。此模式支持安全的工具调用与有状态的智能体流程。具体 SDK 助手请参阅 CometAPI 的文档与示例。
实用参数与调优
function_call:用于启用结构化工具调用与更安全的执行流程。
temperature:0–0.3 适合确定性的系统输出(代码、基础设施),更高用于创意发散。
max_tokens:根据预期输出长度设置;GLM-5 在托管环境下支持很长输出(供应商限制各异)。
top_p / 核心采样:用于抑制低概率尾部。
stream:在交互式 UI 中启用。
GLM-5 与 Anthropic 的 Claude Opus 及其他前沿模型对比
简言之:在智能体与编码基准上,GLM-5 缩小了与前沿闭源模型的差距,同时提供开放权重部署,并在聚合托管时常具更好的每 token 成本。细节上:在某些绝对编码基准(SWE-bench、Terminal-Bench 变体)上,Anthropic 的 Claude Opus(4.5/4.6)在多份公开榜单中仍领先数个百分点——但 GLM-5 竞争力很强,并优于许多其他开源模型。
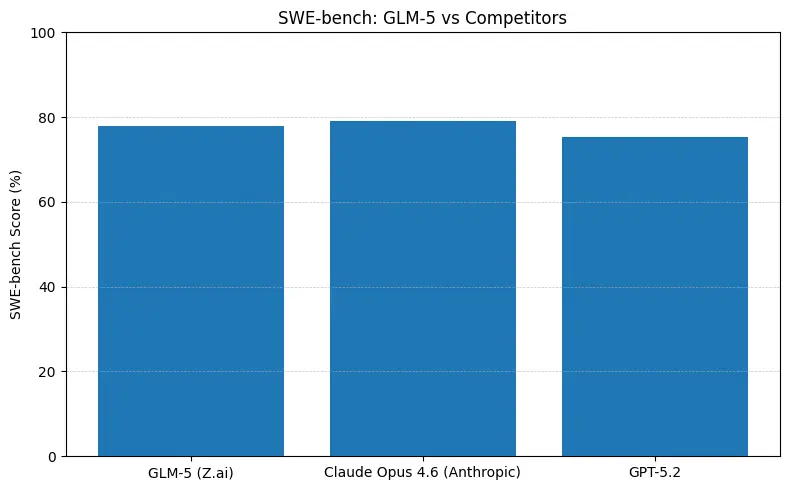
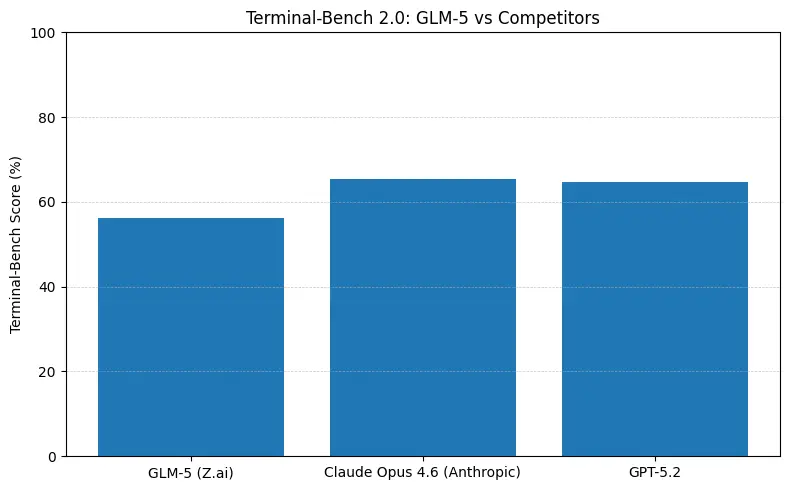
这些数字在实践中的意义
- SWE-bench(~代码正确性/工程):Claude Opus 在公开榜单上略有领先(≈79% vs GLM-5 ≈77.8%);对许多真实任务而言,这会转化为更少的人工修改,但不一定导致原型或规模化智能体工作流在架构选择上的改变。
- Terminal-Bench(命令行智能体任务):Opus 4.6 领先(≈65.4% vs GLM-5 ≈56.2%)——若你需要稳健的终端自动化与对分布外 Shell 操作的最高可靠性,Opus 往往在边际上更好。
- 智能体与长时程:GLM-5 在长时程业务模拟中表现出色(Vending-Bench 2 报告余额 $4,432),并在多步工作流上展现强规划一致性。若你的产品是长时间运行的智能体(金融、运营),GLM-5 具优势。
如何设计提示与系统以获得可靠的 GLM-5 输出?
System 消息与显式约束
为 GLM-5 设定严格角色与约束,尤其针对代码或工具调用任务。例如:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
要求为每个非平凡变更提供测试与简要推理。
分解复杂任务
不要直接要求“写完整产品”,而是先要:
- 设计纲要,
- 接口签名,
- 实现与测试,
- 最终集成脚本。
这种分步分解可降低幻觉,并提供可验证的确定性检查点。
低温度以获得确定性代码
请求代码时,将 temperature 设为 0–0.2,并为 max_tokens 设置安全上限。创作写作或头脑风暴时可提高温度。
集成 GLM-5 的最佳实践(通过 CometAPI 或直接托管)
提示工程与 System 提示
- 使用明确的system指令,定义智能体角色、工具访问策略与安全约束。例如:“你是系统架构师:仅在本地单元测试通过时提出变更;列出要运行的精确 CLI 命令。”
- 针对编码任务,提供仓库上下文(文件列表、关键代码片段),并附上单测输出(如有)。GLM-5 的长上下文会有帮助——但务必将关键信息(角色、任务)放在前面,其次是支持性材料。
会话与状态管理
- 为长对话的智能体使用会话 ID,并维护前序步骤的精简“记忆”(摘要),避免上下文膨胀。CometAPI 与相似网关提供会话/状态辅助——但应用层的状态压缩对长运行智能体至关重要。
工具与函数调用(安全与可靠性)
- 仅暴露窄而可审计的工具集。不要在无人监督下允许任意 Shell 执行。使用结构化函数定义,并在服务端验证其参数。
- 始终记录工具调用与模型响应,便于溯源与事后调试。
成本控制与批处理
- 对高容量智能体,在可接受质量权衡的情况下将后台处理路由到更便宜的模型变体(CometAPI 允许按名称切换模型)。对相似请求进行批处理,并尽可能降低
max_tokens。监控输入与输出 token 比例——输出 token 往往更昂贵。
时延与吞吐工程
- 交互式会话使用流式。对于后台智能体任务,优先采用异步运行时、工作队列与限流。若自托管(开放权重),请针对 MoE 架构调优加速器拓扑——FPGA / Ascend / 专用硅等选项可能带来成本优势。
结语
GLM-5 是迈向智能体工程的务实开放权重一步:大上下文窗口、规划能力与强代码表现,使其在开发者工具、智能体编排与系统级自动化中颇具吸引力。你可以通过 CometAPI 快速集成,或使用云端模型园进行托管;务必在你的工作负载上验证,并对成本与幻觉实施严格监控。
开发者现在即可通过GLM-5与CometAPI获取访问。起步建议在Playground中探索模型能力,并参考API guide获取详细说明。访问前,请确保已登录 CometAPI 并获得 API Key。CometAPI提供远低于官方定价的价格,助你快速集成。
准备好了吗?→ Sign up fo M2.5 today