

通过 CometAPI 开始使用 Gemini 2.5 Flash-Lite,是一次充分利用当下最具成本效益、低延迟生成式 AI 模型的激动人心的机会。本指南结合了来自 Google DeepMind 的最新发布、Vertex AI 文档中的详细规格,以及使用 CometAPI 的实际集成步骤,帮助你快速有效地上手。
什么是 Gemini 2.5 Flash-Lite,为什么值得考虑?
Gemini 2.5 家族概览
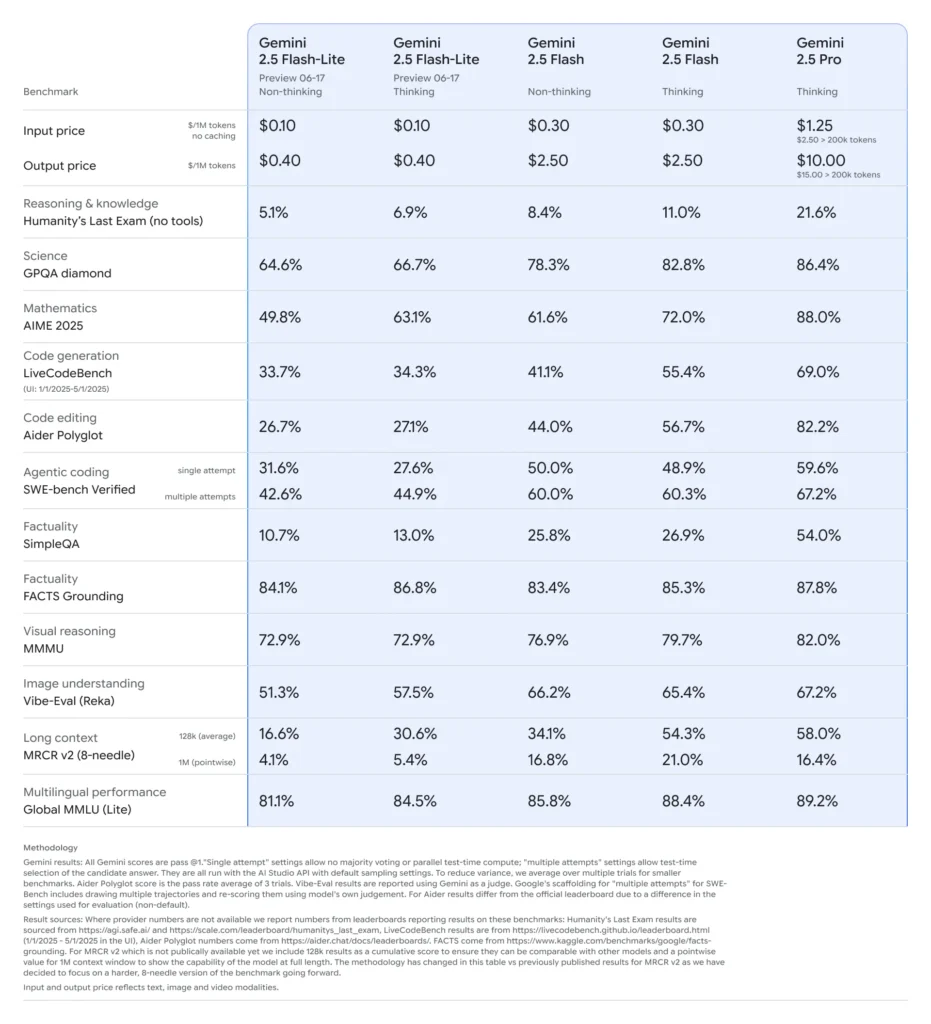
在 2025 年 6 月中旬,Google DeepMind 正式发布了 Gemini 2.5 系列,包括 Gemini 2.5 Pro 和 Gemini 2.5 Flash 的稳定 GA 版本,同时预览了一款全新的轻量级模型:Gemini 2.5 Flash-Lite。该系列旨在在速度、成本与性能之间取得平衡,覆盖从重型研究工作负载到大规模、成本敏感的部署等广泛用例。
Flash-Lite 的关键特性
Flash-Lite 以极低延迟提供多模态能力(文本、图像、音频、视频),上下文窗口可支持最多一百万令牌,并支持包括 Google 搜索、代码执行、函数调用在内的工具集成。关键的是,Flash-Lite 引入了“思维预算”控制,开发者可通过调整内部令牌预算参数,在推理深度与响应时间、成本之间进行权衡。
在模型序列中的定位
与同系列模型相比,Flash-Lite 位于成本效率的帕累托前沿:在预览期间,输入每百万令牌约 $0.10、输出每百万令牌约 $0.40,低于 Flash($0.30/$2.50)和 Pro($1.25/$10),同时保留了它们的大多数多模态能力和函数调用支持。这使得 Flash-Lite 非常适合高容量、低复杂度的任务,如摘要、分类和轻量级对话代理。
为什么开发者应考虑使用 Gemini 2.5 Flash-Lite?
性能基准与真实测试
在正面对比中,Flash-Lite 展现了:
- 在分类任务上,吞吐量比 Gemini 2.5 Flash 快 2×。
- 在企业级摘要流水线中,成本节省达 3×。
- 在逻辑、数学与代码基准上具备竞争性准确度,匹配或超越早期 Flash-Lite 预览版本。
理想用例
- 高容量聊天机器人:在数百万用户中提供一致、低延迟的对话体验。
- 自动化内容生成:规模化处理文档摘要、翻译与微文案创作。
- 搜索与推荐流水线:利用快速推理实现实时个性化。
- 批量数据处理:以最低算力成本为大型数据集添加标注。
如何通过 CometAPI 获取并管理 Gemini 2.5 Flash-Lite 的 API 访问?
为什么使用 CometAPI 作为你的网关?
CometAPI 在统一的 REST 端点下聚合了 500+ AI 模型(包括 Google 的 Gemini 系列),简化了跨供应商的认证、限流与计费。无需同时应对多个基础 URL 和 API 密钥,你只需将所有请求指向 https://api.cometapi.com/v1,在请求负载中指定目标模型,并通过一个仪表盘管理用量。
先决条件与注册
- 登录 cometapi.com。如果你还不是我们的用户,请先注册
- 获取接口访问凭证 API key。在个人中心的 API token 处点击“Add Token”,获取令牌密钥:sk-xxxxx 并提交。
- 获取本站的 url:https://api.cometapi.com/
管理你的令牌与配额
CometAPI 的仪表盘提供可在 Google、OpenAI、Anthropic 等模型间共享的统一令牌配额。使用内置监控工具设置用量告警与速率限制,避免超出预算分配或产生意外费用。
如何为 CometAPI 集成配置开发环境?
安装所需依赖
对于 Python 集成,安装以下包:
pip install openai requests pillow
- openai:与 CometAPI 通信的兼容 SDK。
- requests:用于执行 HTTP 操作,例如下载图像。
- pillow:在发送多模态输入时进行图像处理。
初始化 CometAPI 客户端
使用环境变量将 API 密钥从源代码中隔离:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
现在,你可以在请求中通过指定模型 ID(例如 gemini-2.5-flash-lite-preview-06-17)来定向到任一受支持模型。
配置思维预算与其他参数
发送请求时,你可以包含可选参数:
- temperature/top_p:控制生成的随机性。
- candidateCount:备选输出数量。
- max_tokens:输出令牌上限。
- thought_budget:Flash-Lite 的自定义参数,用于在推理深度与速度/成本之间权衡。
通过 CometAPI 发往 Gemini 2.5 Flash-Lite 的基础请求是什么样?
纯文本示例
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "你是一位简洁的摘要者。"},
{"role": "user", "content": "请总结 AI 模型定价的最新趋势。"}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
此调用可在 200 毫秒内返回精炼摘要,非常适合聊天机器人或实时分析流水线。
多模态输入示例
from PIL import Image
import requests
# 从 URL 加载一张图像
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite 可处理最大 7 MB 的图像并返回上下文描述,适用于文档理解、UI 分析与自动化报告。
如何利用流式传输与函数调用等高级功能?
面向实时应用的流式响应
对于聊天机器人界面或实时字幕,使用流式 API:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
这将随着生成过程提供部分输出,降低交互式界面中的感知延迟。
用函数调用实现结构化数据输出
定义 JSON 模式以强制结构化响应:
functions = [{
"name": "extract_entities",
"description": "从文本中抽取命名实体。",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
该方法可保证输出符合 JSON 规范,简化下游数据流水线与集成。
使用 Gemini 2.5 Flash-Lite 时如何优化性能、成本与可靠性?
思维预算调优
Flash-Lite 的思维预算参数允许你控制模型投入的“认知努力”。较低预算(如 0)优先速度与成本;较高值则带来更深入的推理,但会增加延迟与令牌消耗。
令牌限制与吞吐量管理
- 输入令牌:每次请求最多 1,048,576。
- 输出令牌:默认上限为 65,536。
- 多模态输入:图像、音频与视频资产合计最多 500 MB。
为高容量工作负载实施客户端批处理,并利用 CometAPI 的自动扩缩容以在无需人工干预的情况下应对突发流量。
成本效率策略
- 将低复杂度任务集中在 Flash-Lite 上,同时为重型任务保留 Pro 或标准 Flash。
- 在 CometAPI 仪表盘中使用速率限制与预算告警,防止失控支出。
- 按模型 ID 监控用量,以比较每次请求成本并据此调整路由逻辑。
初始集成后的最佳实践与下一步
监控、日志与安全
- 日志:采集请求/响应元数据(时间戳、延迟、令牌使用)以进行性能审计。
- 告警:在 CometAPI 中设置错误率或成本超限的阈值通知。
- 安全:定期轮换 API 密钥,并存储于安全的密钥库或环境变量。
常见使用模式
- 聊天机器人:用 Flash-Lite 处理快速用户查询,对复杂问题回退至 Pro。
- 文档处理:在较低预算设置下于夜间批量处理 PDF 或图像分析。
- 实时分析:通过流式 API 传输金融或运营数据以获得即时洞察。
进一步探索
- 试验混合提示:结合文本与图像输入以提供更丰富的上下文。
- 原型化 RAG(Retrieval-Augmented Generation,检索增强生成),将向量搜索工具与 Gemini 2.5 Flash-Lite 集成。
- 与竞争产品(如 GPT-4.1、Claude Sonnet 4)进行基准对比,以验证成本与性能的权衡。
生产级扩展
- 利用 CometAPI 的企业版获取专属配额池与 SLA 保证。
- 实施蓝绿部署策略,在不影响在线用户的情况下测试新提示或预算。
- 定期审查模型用量指标,识别进一步的成本节约或质量提升机会。
入门指南
CometAPI 提供统一的 REST 接口,在一个一致的端点下聚合数百个 AI 模型,并内置 API 密钥管理、用量配额与计费仪表盘。无需再同时处理多个供应商的 URL 与凭据。
开发者可通过 CometAPI 访问 [Gemini 2.5 Flash-Lite (preview) API](https://www.cometapi.com/flux-1-kontext/)(Model: gemini-2.5-flash-lite-preview-06-17),本文所列最新模型以发布时为准。开始之前,请在 Playground 中探索该模型的能力,并参考 API guide 获取详细说明。在访问前,请确保你已登录 CometAPI 并取得 API key。CometAPI 提供远低于官方价格的报价,助你快速集成。
只需几个步骤,你就能通过 CometAPI 将 Gemini 2.5 Flash-Lite 集成到你的应用中,解锁速度、经济性与多模态智能的强大组合。遵循上述涵盖配置、基础请求、高级功能与优化的指南,你将能够为用户交付下一代 AI 体验。成本高效、高吞吐的 AI 时代已然来临:立即开始使用 Gemini 2.5 Flash-Lite。