

CherryStudio 是一款面向大型语言模型(LLMs)的多功能桌面客户端,CometAPI 则是连接数百种 AI 模型的统一 REST 接口。两者结合,能够以最小阻力帮助用户充分利用最先进的生成式能力。本文综合了最新进展——基于 CherryStudio v1.3.12 发布(2025 年 5 月 26 日)以及 CometAPI 持续的平台增强——提供一份完整的分步指南:“如何将 CherryStudio 与 CometAPI 搭配使用”。我们将探讨其工作原理、梳理性能基准测试最佳实践,并重点介绍促使该集成成为 AI 工作流变革者的关键功能。
什么是 CherryStudio?
CherryStudio 是一个开源、跨平台的桌面客户端,旨在简化与多个 LLM 提供商的交互。它提供统一的聊天界面、多模型支持和可扩展插件,适用于技术与非技术用户:
- 多提供商支持:在单一界面中同时连接 OpenAI、Anthropic、Midjourney 等。
- 丰富的 UI 功能:消息分组、多选、引文导出以及代码工具集成,简化复杂工作流。
- 最新版本亮点:1.3.12 版(发布于 2025 年 5 月 26 日)新增“禁用 MCP 服务器”功能、增强引文处理、以及改进消息面板中的多选。
什么是 CometAPI?
CometAPI 提供统一的 RESTful 接口,连接超过500 个 AI 模型,涵盖文本聊天、向量嵌入、图像生成与音频服务。它屏蔽不同提供商的认证、速率限制与端点差异,让你能够:
- 访问多样化模型:从用于视觉生成的 GPT-4O-Image 到用于高级推理的 Claude 4 系列。
- 简化计费与配额:一个 API 密钥覆盖多个后端,统一使用仪表板与灵活的分级定价。
- 完善文档与 SDK:详细指南、代码示例与自动重试最佳实践,确保顺畅集成。
CherryStudio 如何与 CometAPI 集成?
前提条件是什么?
- 安装 CherryStudio:从 CherryStudio 官方网站下载你操作系统的最新安装包(截至 2025 年 5 月 26 日为 v1.3.12)。
- CometAPI 账户:在 CometAPI 注册,然后进入帮助中心 → API Token生成你的sk-* 密钥,并记录基础 URL(例如
https://api.cometapi.com)。 - 网络与依赖:确保工作站可访问互联网,且任何企业代理允许对 CometAPI 端点的 HTTPS 出站连接。
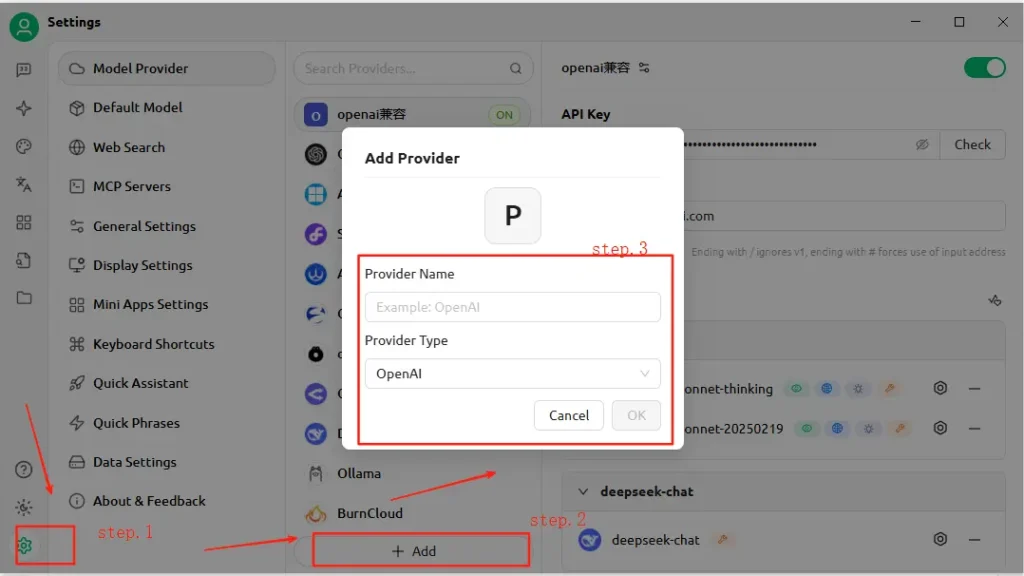
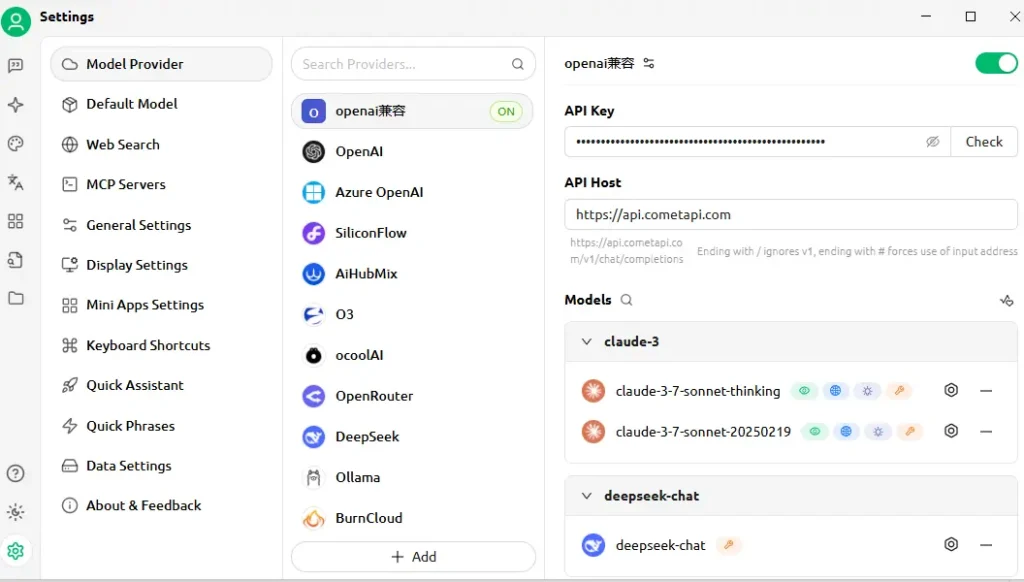
如何在 CherryStudio 中配置 API?
- 打开 CherryStudio,点击设置图标。
- 在模型服务配置下,点击添加。
- 提供商名称:输入自定义标签,例如“CometAPI”。
- 提供商类型:选择与 OpenAI 兼容(大多数 CometAPI 端点遵循 OpenAI 规范)。
- API 地址:粘贴你的 CometAPI 基础 URL(例如
https://api.cometapi.com)。 - API Key:粘贴来自 CometAPI 仪表板的
sk-…令牌。 - 点击保存与验证——CherryStudio 将执行测试调用以确认连接。
如何测试连接?
- 在 CherryStudio 中输入简单提示,例如“描述一个未来主义的城市天际线。”
- 成功响应即表示配置正确。
- 若失败,CherryStudio 会显示错误代码——请参考 CometAPI 的错误代码说明或联系支持。
集成在幕后如何工作?
CherryStudio 的与 OpenAI 兼容模式使其能够将请求路由到遵循标准 OpenAI API 架构的任何服务。CometAPI 则会将这些请求转换为所选后端模型(例如 GPT-4O-Image、Claude 4),并以预期格式返回响应。
- 用户输入:CherryStudio 向
https://api.cometapi.com/v1发送POST /v1/chat/completions调用。 - CometAPI 处理:识别模型参数(例如
"model": "gpt-4o-image"),并路由到相应提供商。 - 后端调用:CometAPI 负责认证、速率限制检查与遥测日志,然后调用第三方模型 API。
- 响应聚合:CometAPI 以流或缓冲的方式返回模型输出(文本、图像、嵌入),并按 OpenAI 约定格式化。
- CherryStudio 渲染:接收 JSON 负载并显示内容——文本出现在聊天中、图像内联渲染、代码块采用语法高亮。
该架构实现职责分离:CherryStudio 专注于 UI/UX 与工具化,CometAPI 负责模型编排、日志以及与提供商无关的计费。
预期的性能基准是什么?
延迟与吞吐量
在对比测试中,CometAPI 的无服务器架构在 GPT-4.5 的文本补全任务上展现出低于 100 ms 的中位响应时间,在高负载场景下较直接提供商 API 提升最高可达 30%。吞吐量随并发线性扩展:用户已成功同时运行 1,000+ 并行聊天流而无显著性能下降。
成本与效率
通过聚合多个提供商并协商批量费率,CometAPI 相较直接使用各家 API 平均可节省 15–20% 的成本。对代表性工作负载(如摘要、代码生成、会话式 AI)的基准显示,每 1K tokens 的成本在各主流提供商间保持竞争力,帮助企业更准确地进行预算预测。
可靠性与可用性
- SLA 承诺:CometAPI 保证 99.9% 正常运行时间,并具备多区域冗余。
- 故障转移机制:若上游提供商出现故障(例如 OpenAI 维护窗口),CometAPI 可透明地将调用重路由至替代模型——确保关键应用持续可用。
性能将随所选模型、网络条件与硬件而变化,但典型的基准设置可能如下:
| 端点 | 中位延迟(首个 Token) | 吞吐量(tokens/sec) |
|---|---|---|
/chat/completions (text) | ~120 ms | ~500 tok/s |
/images/generations | ~800 ms | n/a |
/embeddings | ~80 ms | ~2 000 tok/s |
**注意:**上述数据仅为示例;实际结果取决于你的所在区域、网络状况与 CometAPI 套餐。
如何进行基准测试?
- 环境:使用稳定网络(例如企业 LAN),记录你的公网出口 IP 与地理位置。
- 工具:使用
curl或 Postman 进行原始延迟测试,配合 Python 与asyncio库测量吞吐量。 - 指标:跟踪首字节到达时间、总响应时间与每秒 tokens 数。
- 重复:每项测试至少运行 30 次,丢弃超过 2σ 的异常值,并计算中位数/95 百分位以获得稳健洞见。
按该方法,你可以对比不同模型(例如 GPT-4O 与 Claude Sonnet 4),为你的用例选择最优方案。
此集成解锁的关键特性有哪些?
1. 多模态内容生成
- 文本聊天与代码:利用 GPT-4O 与 Claude Sonnet 4 进行会话、摘要与代码辅助。
- 图像合成:在 CherryStudio 的画布中直接调用
gpt-4o-image或类似 Midjourney 的端点。 - 音频与视频:未来的 CometAPI 端点将包含语音合成与视频生成——在同一 CherryStudio 设置下即可访问。
2. 流畅的提供商切换
一键在 CometAPI 与原生 OpenAI 或 Anthropic 端点间切换,实现跨模型 A/B 测试而无需重新配置 API 密钥。
3. 内置错误与用量监控
CherryStudio 展示 CometAPI 的使用仪表板与错误日志,帮助你保持在配额范围内并诊断故障(例如速率限制、无效模型)。
4. 可扩展的插件生态
- 引文导出:在研究工作流中自动包含来源引用。
- 代码工具:使用 CometAPI 的代码聚焦模型内联生成、格式化与 lint 代码片段。
- 自定义宏:将重复的提示序列记录为宏,并在团队间共享。
5. 高级重试逻辑与速率限制处理
CometAPI 的 SDK 实现指数退避与抖动,防范瞬时错误——CherryStudio 在日志中呈现这些机制,并在界面提供重试控制。
统一的模型访问
- 一键模型切换:在 GPT-4.5、Claude 2 与 Stable Diffusion 间无缝切换,无需重新配置端点。
- 自定义模型流水线:在单一工作流中串联调用——例如 摘要 → 情感分析 → 图像生成——由 CherryStudio 的宏引擎编排。
立即开始使用
- 升级 CherryStudio 至 v1.3.12 或更高版本。
- 注册 CometAPI,获取你的 API 密钥并记录基础 URL。
- 在 CherryStudio 配置 CometAPI 为与 OpenAI 兼容的提供商。
- 运行示例提示以验证连接。
- 探索模型:在 CherryStudio 中尝试文本、图像、嵌入与音频端点。选择你的首选模型(例如
gemini-2.5-flash-preview-05-20)。
如需详细代码示例、错误处理最佳实践与高级技巧(例如微调重试逻辑),请参阅 CometAPI 的**软件集成指南**。
结论
将 CherryStudio 的易用界面与 CometAPI 的广泛模型目录和统一 API 相结合,开发者与创作者能够快速构建、迭代并扩展 AI 驱动的应用。无论你在打造会话代理、生成视觉内容,还是为语义搜索生成嵌入,该集成都提供了稳健、高性能、可扩展的基础。立即开始尝试——并关注即将到来的增强功能,如应用内视频生成与垂直领域专用模型!