

Anthropic 的 Claude Opus 4.6 于 2026 年 2 月发布,明确面向企业级智能体、长上下文知识工作以及更强的自主编码能力。这一版本将雄心勃勃的工程能力(测试版百万 token 上下文模式、“自适应思考”能力以及智能体团队协作特性)与务实的商业决策相结合:Anthropic 保持了与此前 Opus 系列一致的 API 定价。二者叠加——能力显著提升而价格未立刻上涨——成为焦点。
Claude Opus 4.6 到底是什么?
Claude Opus 4.6 是 Anthropic 在 Opus 系列中的旗舰:一款面向企业的大规模生成式 AI 模型,针对智能体工作流、编码和长周期知识工作进行了优化。Anthropic 将 Opus 4.6 定位为其构建智能体与自动化的最智能模型——不仅用于回答问题,还能规划、调用工具、协调子智能体,并在大型代码库和文档语料库中执行多步骤任务。
不同于面向消费者的聊天机器人,Opus 4.6 面向企业集成:可通过 Anthropic 的 claude.ai 界面、Claude API,以及 CometAPI 获取。Opus 4.6 在智能体编码任务与工具调用方面表现突出。对于企业而言,这意味着 Opus 4.6 被定位为智能体助理、代码迁移工具、文档审阅流水线和需要比常规聊天更广泛上下文的分析型工作流中的“即插即用式”升级。
Opus 4.6 关键新特性的深入解析
百万 token 上下文(及实用模式)
Opus 4.6 支持更大的默认上下文窗口(标称 200K token,另提供 1M token 的测试版窗口)。百万级窗口在纸面上是一次变革:模型可以在一次会话中容纳完整的代码仓库、冗长的法律文书、多年的邮件归档或大型数据表,从而减少对外部检索支撑的依赖。Anthropic 将“上下文压缩”工具与大窗口配套,帮助压缩相关信息并降低 token 成本。简言之:Opus 确实能够在不切碎内容的情况下处理超大体量的资料,让构建长生命周期智能体更为简单。
为何重要: 对于代码重构、法律/财务审阅或需要跨文档推理的研究项目,更大的窗口可减少工程开销(更少检索、更少状态管理),并在超长推理链上保持更高连贯性。
自适应思考与扩展推理控制
Opus 4.6 引入了 Anthropic 所称的“自适应思考”(是其早期“扩展思考”理念的演进)。这既是内部能力,也是 API 控制项:开发者可以调节模型的“计算投入水平”和规划深度,让其在复杂规划上投入更多算力,或在琐碎任务上保持简短而快速的回复。
为何重要: 在智能体工作流中,边际质量提升会复合放大:更好的规划与协作意味着更少的人为纠正与更可靠的自主执行。
“智能体团队”和智能体编排是什么?
Opus 4.6 强化了对智能体工作流的支持:可以生成、协调并监督多个子智能体以分而治之。Anthropic 的资料(以及早期合作伙伴报告)强调,Opus 能主动创建子智能体、分派子任务、监控进度,并在需要时终止或切换策略——实际上充当复杂多步骤工程或分析工作的轻量级编排器。与规划、工具使用和错误纠正的紧密集成,是面向自动化团队的核心卖点。
面向企业集成的 API 与工具改进
Anthropic 扩展了针对压缩、持久化与工具调用的 API 控制。模型支持更大的输出上限(Anthropic 提到可达 128K 输出 token)、更细的检索语义,以及面向 Microsoft 365 和开发者环境的企业集成。实际效果是把 Opus 接入电子表格、幻灯片和内部工具链时需要的“胶水代码”更少。Anthropic 已将 Opus 4.6 集成进更高层的工具,如 Claude Cowork(无代码界面)以及更新后的 Claude Code,使非技术用户也能触达自动化能力。
Opus 4.6 在基准测试中的表现如何?
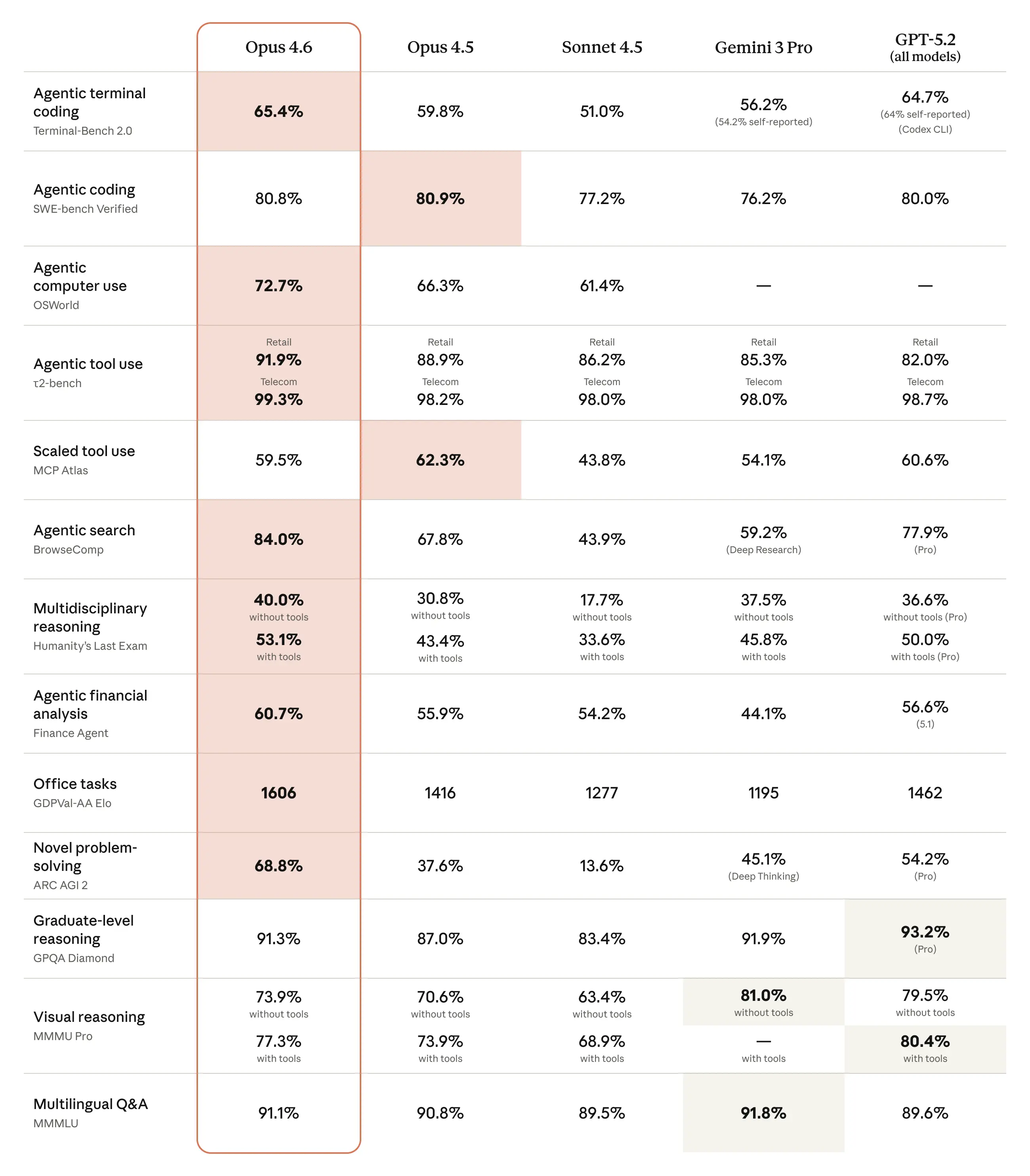
与 Opus 4.5 相比,Opus 4.6 取得了提升,并在编码、推理与领域专项测试中与 OpenAI 和 Google 的近期模型形成竞争关系。简要示例如下:
- BigLaw Bench:在 Anthropic 的 BigLaw Bench(法律推理)上,Opus 4.6 达到了 ~90.2%。
- Terminal-Bench 2.0 / GDPval 指标:独立报道列出了 Terminal-Bench 2.0 分数与 GDPval-AA Elo 评级,显示 Opus 4.6 领先于 Opus 4.5,并与部分竞争对手的近期发布相当。有报告列出 Terminal-Bench 2.0 得分 65.4%,GDPval-AA Elo ~1,606。
Anthropic 报告称在智能体编码任务上有大幅提升:更好的规划、更少的迭代,以及在超大代码库上的更强表现——包括号称能在更短时间内规划并执行对数百万行仓库的迁移。模型在“自我发现错误”与跨多步骤持续推理方面的改进被特别强调。
Opus 4.6 的费用是多少?
简短回答 — 按 token 计费
- 标准(prompts ≤ 200K tokens): $5 / 1M input tokens 和 $25 / 1M output tokens。
- 大提示(prompts > 200K tokens): $10 / 1M input 和 $37.50 / 1M output。
- Fast 模式(研究预览): 高级档位 — $30 / 1M input 和 $150 / 1M output(更快推理)。
实际成本考量:
- 智能体工作流通常 token 开销较大。 多步规划、工具调用与长输出会增加输出 token;谨慎使用压缩与缓存读取有助于控制账单。
- 批处理更省钱。 如果你的工作负载适合异步批处理,Anthropic 的批处理 API 定价可显著降低单 token 成本。
- 高级上下文更昂贵。 如果你频繁依赖 1M token 测试版,要预估更高的单 token 费用。许多组织会混合使用模式:在绝对必要时才启用大上下文,其余场景保持精简会话。
寻找更便宜的 Claude API 使用方案
CometAPI 是一个不错的选择。Opus 4.6 API 亦来自 Anthropic,但其 API 定价仅为官方价格的 20%,且不会随上下文长度变化而改变。
Opus 4.6 与 GPT-5.3 和 Google Gemini 3 如何对比?
Opus 4.6 vs OpenAI 的 GPT-5.3
OpenAI 近期的 GPT-5.3(在“Codex”线下品牌化,面向编码/智能体任务)明确针对深度编码与智能体式工作流进行调优,并宣称在多项工程基准(SWE-Bench Pro、Terminal-Bench)上处于行业领先。早期报道显示,GPT-5.3-Codex 在软件工程基准与智能体规划方面推动了 SOTA 表现,使其成为 Opus 4.6 在纯编码与智能体任务上的最直接对手。相较之下,Opus 4.6 以超长上下文与多智能体编排作为差异点。简言之:GPT-5.3 更偏向原生工程深度与开发者测试上的强势成绩;Opus 4.6 强调跨长上下文的企业工作流与领域推理的广度。
Opus 4.6 vs Google Gemini 3?
Google 的 Gemini 3(及 Gemini 3 Pro / Deep Think 变体)在抽象推理、视觉问题求解与部分科学问答基准上表现强劲,并进一步推动了多模态推理。报道认为 Gemini 3 在科学与视觉推理套件上尤为出色,而 Opus 4.6 则在长上下文代码与法律/企业类工作上更有优势。对需要多模态科学推理或高级视觉逻辑任务的组织而言,Gemini 3 或许更有优势;而在长时程知识工作与多智能体自动化方面,Opus 4.6 更具竞争力。
正面对比下谁“更胜一筹”?
没有哪一家能够在所有场景中“通吃”:关键在于关注的工作流。早期的独立对比显示,Opus 4.6 在长周期与领域任务上显著超过 Opus 4.5,而 GPT-5.3 与 Gemini 3 则在某些编码与多模态测试中保持优势。与快速迭代的现实一样,赢家是能将模型优势映射到真实工作负载与工具集成的团队,而不是单一基准分数最高的模型。
Claude Opus 4.6 值得吗?
简短回答:值得——如果你的核心问题是长上下文推理、自主智能体工作流或企业合规。Opus 4.6 的强项切中要害:200K(及测试版 1M)上下文、自适应思考、智能体团队与企业集成,都是实打实的升级,既降低产品工程复杂度,又拓展了可自动化的问题范围。
如果你的工作负载以短小、重复的微任务为主,且极度关注单次成本与时延,那么与其选择 Opus 4.6,不如考虑短时程的专项模型(如 GPT-5.3 Codex)——除非你计划进行任务路由组合使用。
CometAPI 是大型模型 API 的一站式聚合平台,提供无缝的 API 服务集成与管理。在同一平台上支持调用多种主流 AI 模型,覆盖图像生成、视频生成、聊天、TTS 与 STT 等。
你也可以根据成本与模型能力选择所需模型,并随时切换,例如 Gemini 3 Flash、GPT 5.3 或 Opus 4.6。访问前请确保已登录 CometAPI 并获取 API Key。CometAPI 提供远低于官方的价格,助你快速集成。
Ready to Go?→ 立即注册开始编码