

6月17日,上海 AI 独角兽 MiniMax 正式 open‑sourced MiniMax‑M1,这是全球首个 open‑weight 的大规模混合注意力推理模型。通过将专家混合(MoE)架构与全新的 Lightning Attention 机制结合,MiniMax‑M1 在推理速度、超长上下文处理以及复杂任务性能方面带来显著提升。
背景与演进
基于 MiniMax-Text-01 的基础,该模型在专家混合(MoE)框架上引入 Lightning Attention,在训练期间实现 1 million-token 上下文,并在推理时可达 4 million tokens,MiniMax‑M1 代表了 MiniMax‑01 系列的下一代。前代模型 MiniMax‑Text‑01 具有 456 billion 的总参数量、每个 token 激活 45.9 billion 参数,在显著扩展上下文能力的同时,表现与顶级 LLM 相当。
MiniMax‑M1 的关键特性
- 混合 MoE + Lightning Attention:MiniMax‑M1 将稀疏的专家混合设计(总参数 456 billion,但每个 token 仅激活 45.9 billion)与 Lightning Attention(为超长序列优化的线性复杂度注意力)相结合。
- 超长上下文:支持最多 1 million 个输入 tokens——约为 DeepSeek‑R1 的 128 K 限制的 8 倍——可深度理解海量文档。
- 更高效率:在生成 100 K tokens 时,MiniMax‑M1 的 Lightning Attention 仅需 DeepSeek‑R1 计算量的约 25–30%。
模型变体
- MiniMax‑M1‑40K:1 M token 上下文,40 K token 推理预算
- MiniMax‑M1‑80K:1 M token 上下文,80 K token 推理预算
在 TAU‑bench 工具使用场景中,40K 变体优于所有开放权重模型——包括 Gemini 2.5 Pro——展现出其代理能力。
训练成本与设置
MiniMax‑M1 采用大规模强化学习(RL)进行端到端训练,覆盖多样任务——从高级数学推理到基于沙盒的软件工程环境。一种新算法 CISPO(Clipped Importance Sampling for Policy Optimization)通过裁剪重要性采样权重而非进行 token 级更新,进一步提升训练效率。该方法结合模型的 Lightning Attention,使在 512 H800 GPUs 上的完整 RL 训练仅用三周即完成,总租用成本为 $534,700。
可用性与定价
MiniMax‑M1 基于 Apache 2.0 开源许可发布,并可通过以下方式立即访问:
- GitHub 仓库,包含模型权重、训练脚本与评估基准。
- SiliconCloud 托管,提供两个变体——40 K‑token(“M1‑40K”)与 80 K‑token(“M1‑80K”)——并计划启用完整的 1 M token 漏斗。
- 价格目前设定为输入 每百万 tokens ¥4,输出 每百万 tokens ¥16,企业客户可享批量折扣。
开发者与组织可通过标准 API 集成 MiniMax‑M1,基于领域数据进行微调,或在本地部署以处理敏感工作负载。
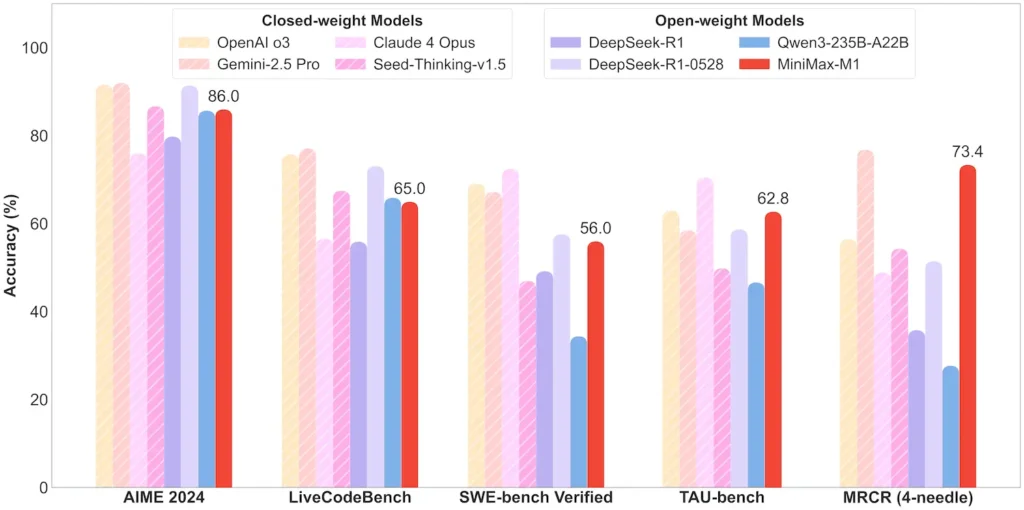
任务级性能
| 任务类别 | 亮点 | 相对表现 |
|---|---|---|
| 数学与逻辑 | AIME 2024:86.0% | > Qwen 3,DeepSeek‑R1;接近闭源水平 |
| 长上下文理解 | Ruler(4 K–1 M tokens):稳定的顶级表现 | 在 128 K token 长度以上优于 GPT‑4 |
| 软件工程 | SWE‑bench(真实 GitHub 缺陷):56% | 开源模型中最佳;位列领先闭源之后第 2 |
| 代理与工具使用 | TAU‑bench(API 仿真) | 62–63.5% 对比 Gemini 2.5、Claude 4 |
| 对话与助理 | MultiChallenge:44.7% | 与 Claude 4、DeepSeek‑R1 相当 |
| 事实问答 | SimpleQA:18.5% | 未来改进空间 |
注:百分比与基准来自 MiniMax 官方披露与独立新闻报道
技术创新
- 混合注意力栈:交替叠加 Lightning Attention 层(线性开销)与周期性 Softmax Attention(二次开销但更具表达力),以平衡效率与建模能力。
- 稀疏 MoE 路由:32 个专家模块;每个 token 仅激活约 10% 的总参数,在保留容量的同时降低推理成本。
- CISPO 强化学习:一种新颖的“Clipped IS‑weight Policy Optimization”算法,在学习信号中保留稀有但至关重要的 tokens,加速 RL 的稳定性与速度。
MiniMax‑M1 的 open‑weight 发布为所有人开启超长上下文、高效率的推理能力——弥合研究与可部署大规模 AI 之间的鸿沟。
入门指南
CometAPI 提供统一的 REST 接口,将数百个 AI 模型(包括 ChatGPT 家族)聚合在一致的端点之下,并内置 API‑key 管理、用量配额与计费看板。无需同时应对多个供应商的 URL 与凭据。
首先,可在 Playground 中探索模型能力,并查阅 API guide 获取详细说明。在访问之前,请确保已登录 CometAPI 并获得 API key。
最新集成的 MiniMax‑M1 API 将很快在 CometAPI 上线,敬请期待!在我们完成 MiniMax‑M1 模型上传期间,可在 Models page 浏览其他模型,或在 AI Playground 试用。MiniMax 在 CometAPI 上的最新模型为 Minimax ABAB7-Preview API 与 MiniMax Video-01 API,参考:
