Technical Details
- Adaptive Reasoning:
Gemini 2.5 Flash-Litesupports on-demand thinking, allowing developers to allocate compute resources only when deeper reasoning is required. - Tool Integrations: Full compatibility with Gemini 2.5’s native tools, including Grounding with Google Search, Code Execution, URL Context, and Function Calling for seamless multimodal workflows.
- Model Context Protocol (MCP): Leverages Google’s MCP to fetch real-time web data, ensuring responses are up-to-date and contextually relevant.
- Deployment Options: Available through the CometAPI, Gemini API, Vertex AI, and Google AI Studio, with a preview track for early adopters to experiment and provide feedback .
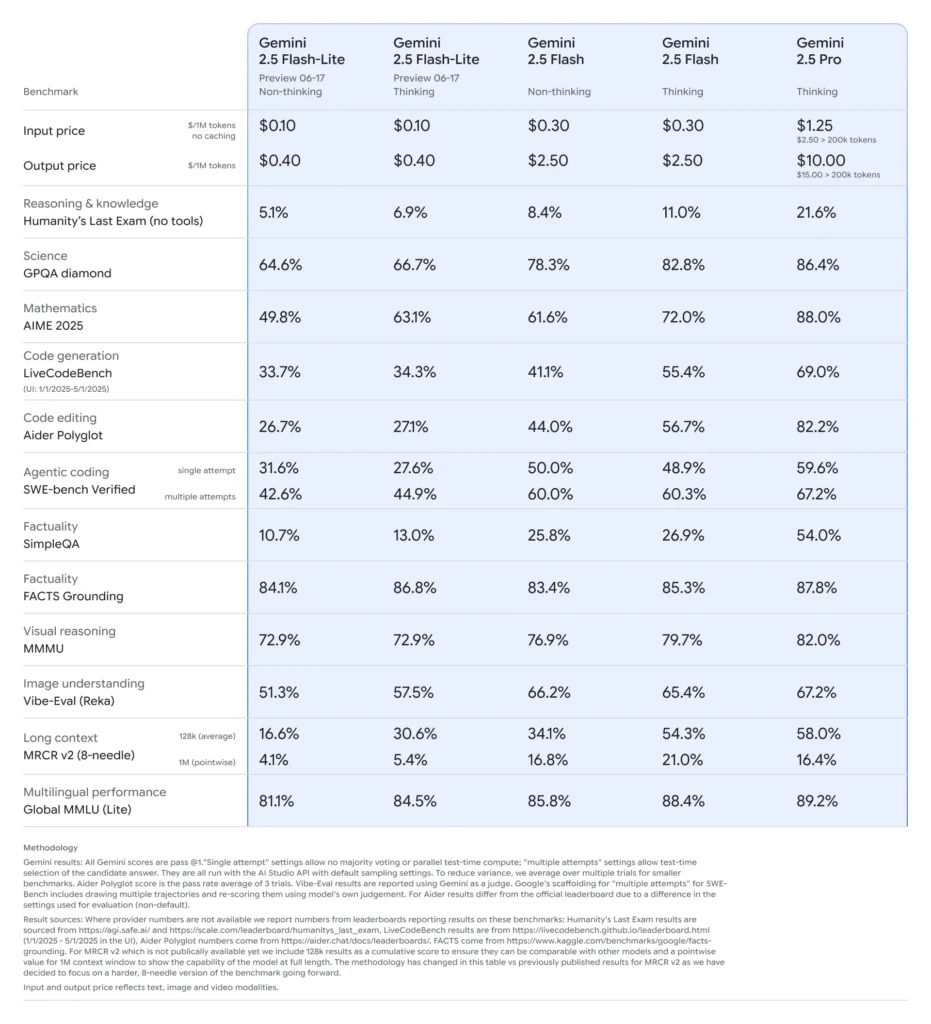
Benchmark Performance of Gemini 2.5 Flash-Lite
- Latency: Achieves up to 50% lower median response times compared to Gemini 2.5 Flash, with typical sub-100 ms latencies on standard classification and summarization benchmarks.
- Throughput: Optimized for high-volume workloads, sustaining tens of thousands of requests per minute without degradation in performance.
- Price-Performance: Demonstrates a 25% reduction in cost per 1,000 tokens versus its Flash counterpart, making it the Pareto-optimal choice for cost-sensitive deployments.
- Industry Adoption: Early users report seamless integration into production pipelines, with performance metrics aligning with or exceeding initial projections .
Ideal Use Cases
- High-Frequency, Low-Complexity Tasks: Automated tagging, sentiment analysis, and bulk translation
- Cost-Sensitive Pipelines: Data extraction from large document corpora, periodic batch summarization
- Edge and Mobile Scenarios: When latency is critical but resource budgets are limited
Limitations of Gemini 2.5 Flash-Lite
- Preview Status: May undergo API changes before GA; integrations should account for possible version bumps.
- No On-the-Fly Fine-Tuning: Cannot upload custom weights; rely on prompt engineering and system messages.
- Reduced Creativity: Tuned for deterministic, high-throughput tasks; less suited for open-ended generation or “creative” writing.
- Resource Ceiling: Scales linearly only up to ~16 vCPUs; beyond this, throughput gains diminish.
- Multimodal Constraints: Supports image/audio inputs but with limited fidelity; not ideal for heavy vision or audio transcription tasks.
- Context-Window Trade-Off : Although it accepts up to 1 M tokens, practical inference at that scale may see degraded throughput.