

OpenAI、Anthropic 和 Google 以其最新旗舰产品——OpenAI 的 o3(及其增强版 o3-pro)、Anthropic 的 Claude Opus 4,以及 Google 的 Gemini 2.5 Pro——持续推动大型语言模型的边界。每个模型都带来了独特的架构创新、性能优势与生态集成,适配从企业级代码辅助到面向消费者的搜索增强等多样用例。本文将深入比较它们的发布历史、技术能力、基准表现与推荐应用,帮助组织为自身需求选择合适的模型。
OpenAI 的 o3 是什么,它如何演进?
OpenAI 于 2025 年 4 月 16 日首次推出 o3,定位为“我们最智能的模型”,旨在支持扩展上下文并提供高度可靠的响应。不久之后,在 2025 年 6 月 10 日,OpenAI 发布了 o3-pro——一款面向 ChatGPT Pro 用户与 API 的性能调优变体,在高负载下提供更快的推理与更高的吞吐。
上下文窗口与吞吐
OpenAI o3 提供200K 令牌的输入与输出上下文窗口,可处理海量文档、代码库或多轮对话而无需频繁截断。其吞吐约为37.6 令牌/秒,虽然不是最快,但在持续工作负载下能保持稳定的响应速度。
高级审慎推理
- “私有思维链”:o3 通过强化学习训练,在生成最终输出前进行中间步骤的规划与推理,显著提升其逻辑推断与问题分解能力。
- 审慎对齐:通过分步推理的安全技术,引导模型更可靠地遵循规范,降低在复杂、真实任务中的重大错误。
定价与企业集成
OpenAI 的 o3 定价约为每百万输入令牌 2 美元、每百万输出令牌 8 美元。这将其置于中端价位:在重负载下比 Claude Opus 4 这类高端模型更实惠,但仍高于 Gemini 2.5 Pro 等经济型选择。关键在于,企业可借助更广泛的 OpenAI API 生态实现无缝集成——覆盖 embeddings、微调与专用端点——从而将集成开销降至最低。
Claude Opus 4 如何在市场中实现差异化?
Anthropic 于 2025 年 5 月 22 日发布 Claude Opus 4,宣称其为“全球最佳编码模型”,在复杂、长时任务与代理工作流中表现稳定。它同时在 Anthropic 自有 API 与 Amazon Bedrock 上线,使 AWS 客户可通过 Bedrock 的 LLM 功能与 REST API 访问.
扩展“思考”能力
Opus 4 的一项独特功能是其**“扩展思考”**测试版模式,可在模型内推理与工具调用(如搜索、检索、外部 API)之间动态分配算力。配合“思维摘要”,用户可洞察模型的内部推理链——这对金融与医疗等合规敏感场景至关重要。
定价与上下文权衡
以每百万输入令牌 15 美元、每百万输出令牌 75 美元计费,Claude Opus 4 处于价格谱的高端。其200K 令牌的输入窗口(输出上限为32K 令牌)小于 Gemini 2.5 Pro 的 1M 令牌窗口,但足以覆盖大多数代码审查与长程推理任务。Anthropic 用更高的内部算力密度与持续的思维链保真来支撑其溢价,同时通过提示缓存最多可节省 90%,通过批处理可节省 50%。付费层包含扩展思考预算;免费用户仅可访问 Sonnet 变体。
Gemini 2.5 Pro 具有什么独特特性与性能?
作为 Google 下一代“Pro”层的产品,Gemini 2.5 Pro面向需要超大上下文、多模态输入与具成本优势的组织。其显著支持单次入站提示最多1,048,576 令牌、出站65,535 令牌,可覆盖贯穿几十万页的端到端文档工作流。
更强的上下文与多模态能力
得益于1M 令牌的上下文窗口,Gemini 2.5 Pro 在法律合同分析、专利挖掘与全面代码库重构等场景中表现突出。该模型原生接受文本、代码、图像、音频、PDF 与视频帧,无需额外预处理即可串联多模态管线。
Gemini 如何增强多模态与会话式搜索?
Gemini 2.5 Pro 以其“查询扇出”方法脱颖而出:将复杂查询分解为子问题并行检索,实时综合生成全面、对话式的答案。凭借对文本、语音与图像输入的支持,AI Mode 利用 Gemini 的多模态能力适配多样交互——但当前仍处于早期阶段,偶尔会误解查询。
竞争性定价
Gemini 2.5 Pro 的输入单价为每百万令牌 1.25–2.50 美元,输出为每百万令牌 10–15 美元,在三者中提供最佳的价格/令牌比。这使其对高量、文档密集型应用尤为具有吸引力——这些场景的令牌消耗主要由长上下文驱动,而非原始性能指标。付费高级计划解锁“Deep Think”预算与更高吞吐。Google AI Pro 与 Ultra 订阅将 Gemini 2.5 Pro 与 Veo 视频生成、NotebookLM 等工具打包提供。
底层架构与能力
OpenAI o3:可扩展的反思式推理
OpenAI 的 o3 是一款反思式生成预训练 Transformer,旨在为分步逻辑推理任务投入额外的思考时间。从架构上看,它以 GPT-4 的 Transformer 主干为基础,引入“思考预算”机制:模型会为复杂问题动态分配更多计算周期,在生成输出前形成内部思维链。这显著提升其在多步推理领域(如高等数学、科学研究与代码生成)中的表现。
Claude Opus 4:用于扩展工作流的混合推理
Anthropic 的 Claude Opus 4 是迄今最强的模型,针对编码与持续的代理式工作流进行优化。与 o3 类似,它采用 Transformer 核心,但引入混合推理模式——近乎即时的“快思”与更长时间的“深思”——使其能在数千步与数小时的计算中保持上下文。这种混合方式使 Opus 4 特别适合长运行的软件工程管线、多阶段研究任务与自主代理编排。
Gemini 2.5 Pro:具有自适应预算的多模态思考
Google DeepMind 的 Gemini 2.5 Pro 扩展了 Gemini 的原生多模态与推理能力。它引入“Deep Think”,一种自适应的并行思考机制,将子任务在内部模块间扇出并综合为一致的响应。Gemini 2.5 Pro 还拥有极长的上下文窗口——可在单次传入中摄取完整代码库、大型数据集(文本、音频、视频)与设计文档——并提供对思考预算的精细化控制,以平衡性能与成本。
这些模型的性能基准如何比较?
学术与科学推理
在近期的 SciArena 排行中,o3 在研究者评估的技术推理问题上名列前茅,体现出社区对其科学准确性的强力信任。与此同时,Claude Opus 4 在需要持续、数小时问题求解的代理类基准中表现更优,在 TAU-bench 与预测性推理任务上较 Sonnet 模型高出多达 30%。Gemini 2.5 Pro 在许多学术基准上也名列前茅,在 LMArena 的人类偏好指标夺得第一,并在数学与科学测试中取得显著优势。
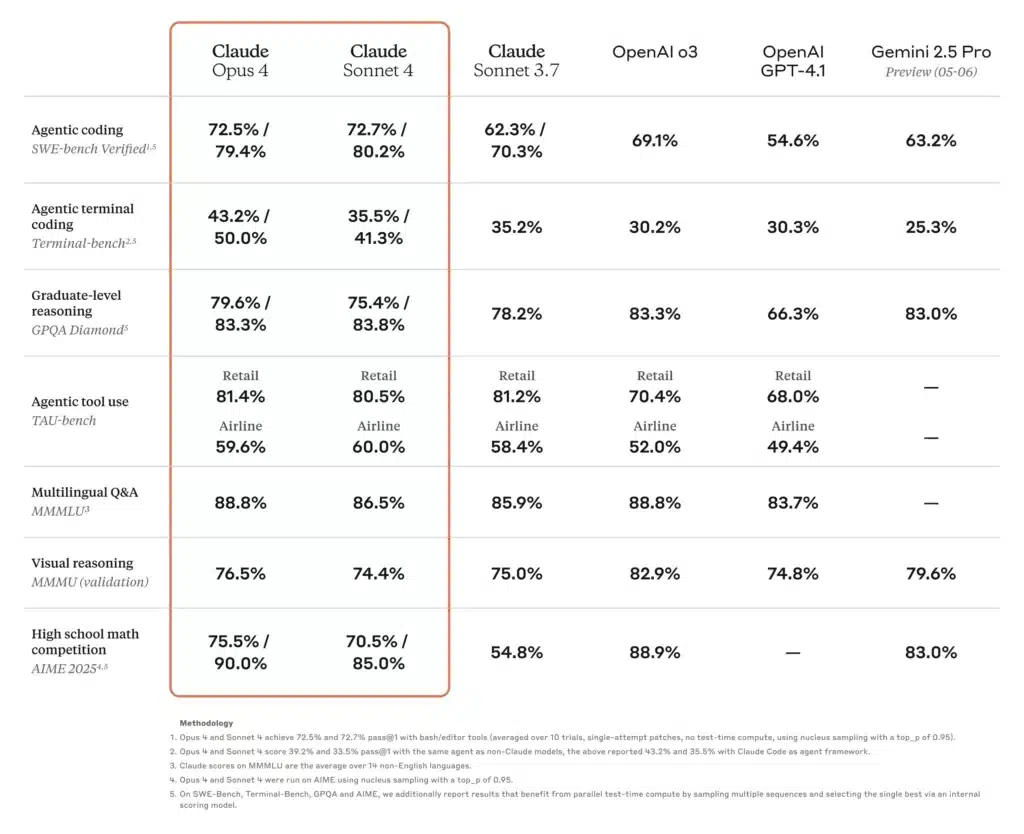
编码与软件工程
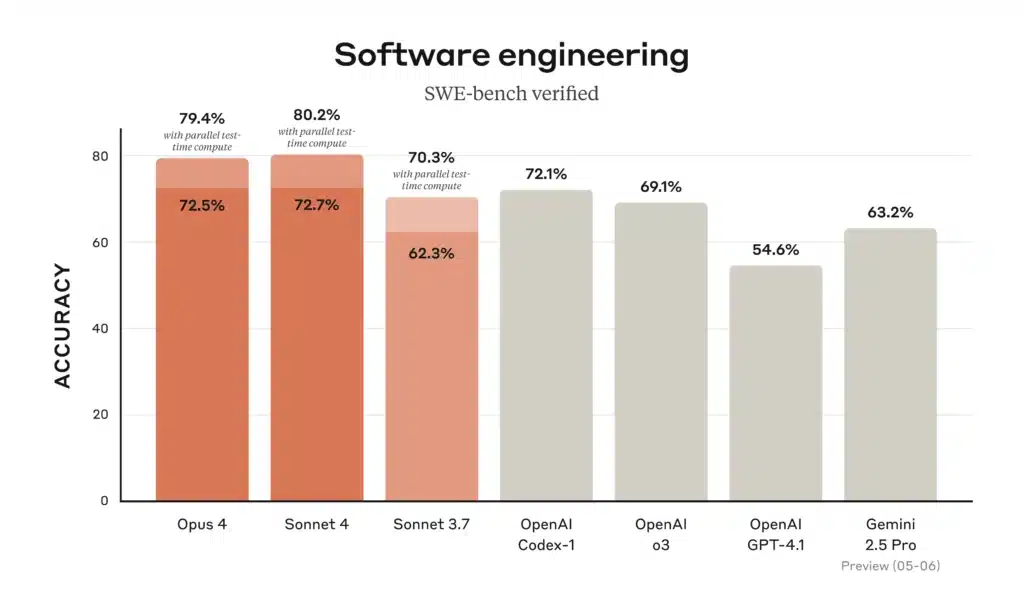
在编码排行榜上,Gemini 2.5 Pro “位居热门的 WebDev Arena 之首”,并在常见编码基准中领先,得益于其加载与推理整个仓库的能力。Claude Opus 4 则以“全球最佳编码模型”著称,在 SWE-bench 得分 72.5%,在 Terminal-bench 得分 43.2%——这些基准聚焦复杂、长时的软件任务。o3 同样在代码合成与调试方面表现出色,但在多步、超大规模工程场景中略逊于 Opus 4 与 Gemini;尽管如此,其直观的思维链让它在个体编码任务中非常可靠。
工具使用与多模态集成
Gemini 2.5 Pro 的多模态设计——处理文本、图像、音频与视频——在交互式仿真、可视化数据分析与视频脚本创作等创意工作流中具优势。Claude Opus 4 的代理式工具使用,包括 Claude Code CLI 与集成的文件系统操作,在构建跨 API 与数据库的自主管线上表现出色。o3 支持网页浏览、文件分析、Python 执行与图像推理,使其成为适用于混合格式任务的“多面手”,但其上下文上限短于 Gemini 2.5 Pro。
这些模型在真实编码场景中的表现如何对比?
在编码辅助方面,基准只展示了部分情况。开发者更看重准确的代码生成、重构能力,以及理解跨多文件的项目上下文。
准确性与幻觉率
- Claude Opus 4在避免幻觉方面领先,较少出现不存在的 API 引用或错误的库签名——这对关键代码库至关重要。在大规模代码审计中,其幻觉率报告为约 12%,而 Gemini 为约 18%、o3 为约 20%。
- Gemini 2.5 Pro在批量转换(例如在数万行中迁移代码模式)方面表现出色,得益于其庞大的上下文窗口,但偶尔会在大型代码块的细微逻辑上出现错误。
- OpenAI o3因其稳定的时延与高可用性,仍是快速片段、样板生成与交互式调试的首选——但开发者通常会与另一模型交叉验证,以捕捉边缘情况的错误。
工具与 API 生态
- o3与Gemini都利用了丰富的工具:分别是 OpenAI 的函数调用 API 与 Google 的集成 Actions 框架,从而实现数据检索、数据库查询与外部 API 调用的无缝编排。
- Claude Opus 4正被集成到类似 Claude Code(Anthropic 的 CLI 工具)与 Amazon Bedrock 的代理框架中,为构建跨 API 与数据库的自主工作流提供高级抽象,无需手动编排。
哪个模型在性价比上更优?
在原始能力、上下文长度与成本之间做平衡,会因工作负载特征不同而得到不同的“最佳价值”结论。
高量、以文档为中心的用例
若要处理海量语料——如法律库、科学文献或企业档案——Gemini 2.5 Pro往往胜出。其1M 令牌窗口与输入 1.25–2.50 美元/百万令牌、输出 10–15 美元/百万令牌的价位,为长上下文任务提供了无可匹敌的成本结构。
深度推理与多步工作流
当准确性、思维链保真度与长运行代理能力至关重要——例如金融建模、法律合规审查或研发管线——尽管价格更高,Claude Opus 4能通过减少错误处理与人工复核,提升端到端吞吐并降低重跑成本。
平衡的企业级采用
对于寻求稳定通用性能而非极端规模的团队,OpenAI o3提供了一种折中方案。凭借广泛的 API 支持、适中的定价与扎实的基准成绩,它在数据科学平台、客服自动化与早期产品集成中仍极具吸引力。
针对你的特定需求应选择哪种 AI 模型?
最终,你的理想选择取决于三大因素:
- 上下文规模:对需要超大输入窗口的工作负载,Gemini 2.5 Pro 有绝对优势。
- 推理深度:若任务涉及多步逻辑且容错率低,Claude Opus 4 提供更高的一致性。
- 成本敏感度与生态契合度:对于 OpenAI 技术栈内的通用任务——尤其是需要与既有数据管线集成——o3 是兼顾成本与性能的选择。
通过评估应用的令牌画像(输入 vs 输出)、对幻觉的容忍度与工具需求,你可以选择在技术与预算上最为契合的模型。
以下是并排对比表,总结了 OpenAI o3、Anthropic Claude Opus 4 与 Google Gemini 2.5 Pro 的关键规格、性能指标、定价与理想用例:
| 特性 / 指标 | OpenAI o3 | Claude Opus 4 | Gemini 2.5 Pro |
|---|---|---|---|
| 上下文窗口(入站 / 出站) | 200 K 令牌 / 200 K 令牌 | 200 K 令牌 / 32 K 令牌 | 1 048 576 令牌 / 65 535 令牌 |
| 吞吐量(令牌/秒) | ~37.6 | ~42.1 | ~83.7 |
| 平均延迟 | ~2.8 秒 | ~3.5 秒 | ~2.52 秒 |
| 编码基准(SWE-bench) | 69.1 % | 72.5 % | 63.2 % |
| 数学基准(AIME-2025) | 78.4 %¹ | 81.7 %¹ | 83.0 % |
| 幻觉率(代码审计) | ~20 % | ~12 % | ~18 % |
| 多模态输入 | 文本与代码 | 文本与代码 | 文本、代码、图像、音频、PDF、视频 |
| “思维链”支持 | 标准 | 扩展思考,带摘要 | 标准 |
| 函数/工具调用 API | 是(OpenAI Functions) | 是(通过 Anthropic agents 与 Bedrock) | 是(Google Actions) |
| 定价(输入令牌) | $2.00 / M 令牌 | $15.00 / M 令牌 | $1.25–$2.50 / M 令牌 |
| 定价(输出令牌) | $8.00 / M 令牌 | $75.00 / M 令牌 | $10–$15 / M 令牌 |
| 理想用例 | 通用聊天机器人、客户支持、快速代码片段 | 深度推理、复杂代码库、自主代理 | 大规模文档分析、多模态工作流 |
o3 与 Opus 4 的 AIME-2025 数学分数为基于已报告基准的近似中位区间值。
入门指南
CometAPI 是一个统一的 API 平台,将超过 500 个来自领先提供商的 AI 模型——如 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等——聚合到一个对开发者友好的接口中。它通过统一的认证、请求格式与响应处理,显著简化了将 AI 能力集成到应用中的过程。无论你在构建聊天机器人、图像生成器、音乐作曲器,还是数据驱动的分析管线,CometAPI 都能帮助你更快迭代、控制成本并保持供应商中立,同时紧跟 AI 生态的最新突破。
开发者可通过CometAPI访问 Gemini 2.5 Pro、Claude Opus 4 和 O3 API,本文所列版本为发布时最新。开始使用前,请在Playground探索模型能力,并参考API guide获取详细说明。访问前,请确保已登录 CometAPI 并获取 API 密钥。CometAPI提供远低于官方价格的报价,以帮助你完成集成。
最终,在 OpenAI 的 o3 系列、Anthropic 的 Claude Opus 4 与 Google 的 Gemini 2.5 Pro 之间做选择,取决于具体的组织优先事项——无论是顶级技术性能、安全的企业集成,还是面向消费者的无缝多模态体验。将你的用例与各模型的优势和生态相匹配,便可利用前沿 AI 推动研究、开发、教育等领域的创新。
作者注:截至 2025 年 7 月 31 日,这些模型仍在持续演进,伴随频繁的小版本更新与生态改进。做出最终决策前,请始终参考最新的 CometAPI API 文档与性能基准。