

OpenAI 最新的推理模型 o3‑pro,在性能与能力上对 AI 驱动应用而言是一次显著飞跃。于 2025 年 6 月上旬发布的 o3‑pro 为开发者与企业提供高级推理、多模态理解与工具使用——且价格定位较高。本文综合最新公告、用户报告与基准数据,全面概述 o3‑pro 的性能、成本考量与可用性。
什么是 o3‑pro?
OpenAI 最新推出的 o3‑pro,是 AI 推理模型的重要里程碑,在增强能力的同时配以高端定价。o3‑pro 于 2025 年 6 月 11 日发布,继任标准版 o3 模型并取代 o1‑pro,面向重视深度分析与可靠性而非纯速度的开发者与企业。o3‑pro 构建于与 o3 相同的底层架构(o3 最初于 2025 年 4 月推出),在单一界面中集成实时网页搜索、文件分析、视觉推理、Python 执行与高级记忆功能,以应对科学、编程、商业与写作等复杂工作流。不过,该模型的审慎推理方式带来更长的响应延迟与显著的成本提升,反映其计算密集型设计。
o3‑pro 与标准版 o3 有何不同?
高级多模态推理
OpenAI 在多项标准 AI 评测中对 o3‑pro 进行了严格验证,以佐证其推理能力。在数学领域,o3‑pro 在 AIME 2024 基准上优于 Google 的 Gemini 2.5 Pro,展现了在限时条件下更强的逻辑推理与复杂方程求解能力。同样地,在衡量博士级科学理解与问题求解能力的 GPQA Diamond 基准上,o3‑pro 超过 Anthropic 的 Claude 4 Opus,凸显其在高级科学推理方面的深度。
o3‑pro 在 OpenAI 旗舰模型 o3 的优势基础上,进一步将实时网页浏览、文件分析、视觉理解与即时 Python 执行整合到一个界面。根据 OpenAI 的说法,这种增强的推理能力使 o3‑pro 能以更高可靠性处理复杂任务——例如科学数据解读、长篇代码调试与多模态内容生成——优于其前代。
以可靠性优先于延迟
这些新能力伴随权衡:o3‑pro 的响应时间可测地慢于 o3,反映其为高级工具使用所需的额外计算与上下文处理步骤。早期用户报告显示,在等价提示下其典型延迟为 o3 的 1.5–2×,但具体数值随请求复杂度而变化。
首发阶段的功能限制
在发布时,o3‑pro 用户注意到一些临时限制:图像生成仍不可用,且在 OpenAI 为新模型扩展基础设施期间,部分 ChatGPT 功能(如短暂的“Canvas”会话与临时聊天线程)被停用。随着产能扩张,这些限制预计将在未来数月逐步缓解。
o3‑pro 在行业基准中的表现如何?
标准化推理测试
在内部测试中,o3‑pro 在涵盖数学、逻辑谜题与编程挑战的标准化推理套件上较 o3 有显著提升。社区报告分数显示,o3 约为 2,517 分,o3‑pro 接近 2,748 分——约提升 9%。
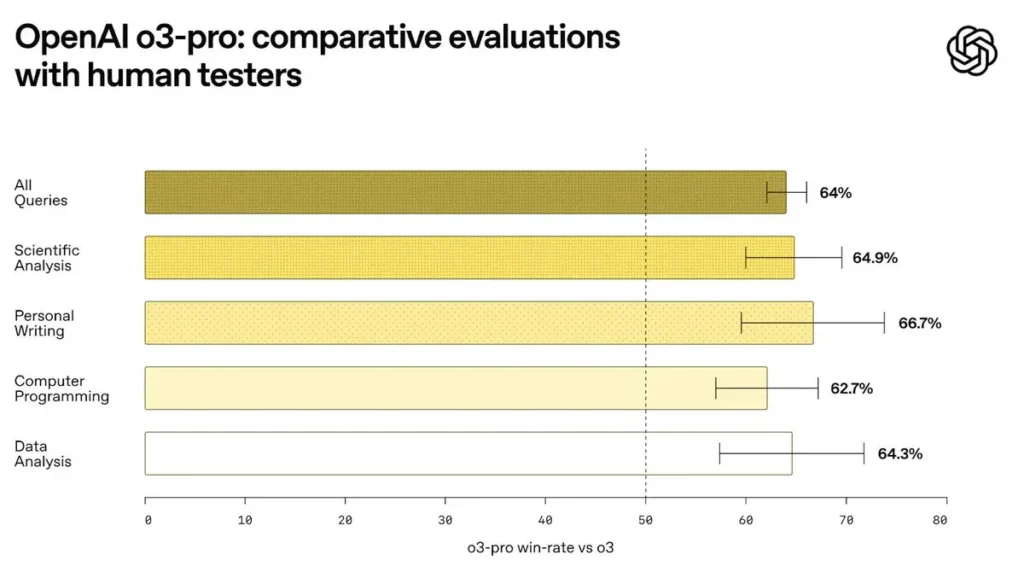
真实世界编码评估
开发者在实时代码生成与调试任务中观察到,o3‑pro 在单次与少样例设置下输出的语法正确性与语义准确性更高。针对 CodeSearchNet 等代码库的基准显示,其在功能正确性上较 o3 提升 5–7%,尤其是在超过 4,000 tokens 的长上下文问题上。
与竞品的对比表现
在正面对比测试中,o3‑pro 不仅在原始分数上胜过 Gemini 2.5 Pro 与 Claude 4 Opus,还在对抗性压力测试下提供更一致的输出。通过结合多模态输入处理与动态工具使用,o3‑pro 缩小了与竞争对手如 Google PaLM 与 Anthropic Claude X 的专项模型差距。早期正面对比测试显示,o3‑pro 在复杂推理基准上可达到或超过竞品准确性,尽管更为全面的第三方报告尚待发布。
开发者应预期何种定价结构?
基于 token 的计费模式
OpenAI 延续其基于 token 的计费:o3‑pro 的价格为每百万输入 tokens 20 美元、每百万输出 tokens 80 美元——恰好是标准版 o3 在近期降价后的 10 倍。相较之下,o3 自 2025 年 6 月上旬起降价至每百万输入 tokens 2 美元、每百万输出 tokens 8 美元。
| 模型 | 输入 token 价格 | 输出 token 价格 |
|---|---|---|
| o3 | $2 / 1M tokens | $8 / 1M tokens |
| o3‑pro | $20 / 1M tokens | $80 / 1M tokens |
高价的原因
这 10 倍的价格提升反映了额外的计算资源、高吞吐基础设施与专用工具集成的需求。OpenAI 将 o3‑pro 定位为“任务关键”模型,适用于准确性与高级推理足以支撑成本溢价的应用场景。
量价折扣与 Batch API
处理海量 tokens 的企业仍可利用 Batch API,在缓存的输入与输出上节省最高 50%。尽管该机制主要惠及 GPT‑4.1 系列的高量用户,类似的批处理选项预计将在 2025 年晚些时候推广到 o 系列模型。
开发者与团队如何访问 o3‑pro?
API 可用性
在正面对比测试中,o3‑pro 不仅在原始分数上胜过 Gemini 2.5 Pro 与 Claude 4 Opus,还在对抗性压力测试下提供更一致的输出。
OpenAI 于 2025 年 6 月 10 日通过公共 API 开放 o3‑pro,并在 Completions 与 Chat 端点中即刻支持。开发者可在 API 调用中指定 "o3-pro" 模型,但受其订阅等级对应的速率限制与配额约束。
POST https://api.openai.com/v1/chat/completions
{
"model": "o3-pro",
"messages": ,
"max_tokens": 1500
}
ChatGPT Pro 与 Team 方案
ChatGPT Pro 与 Team 订阅者可在 ChatGPT 界面中直接使用 o3‑pro。用户可在模型选择器中切换 o3 与 o3‑pro,但最初的可用性仅限于部分企业客户与测试用户。
通过 CometAPI API
开发者可通过 CometAPI 访问 o3-Pro API(model: ”o3-Pro“or”o3-pro-2025-06-10”),文中列示的最新模型以文章发布日期为准。开始之前,请在 Playground 中探索模型能力,并参考 API guide 获取详细说明。访问前请确保已登录 CometAPI 并获取 API key。CometAPI 提供远低于官方价格的方案,帮助你完成集成。
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.cometapi.com/v1",
api_key="<YOUR_API_KEY>",
)
response = client.chat.completions.create(
model="o3-Pro",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices.message.content
print(f"Assistant: {message}")
哪些实际用例最受益于 o3‑pro?
科学研究与数据分析
处理大型数据集的研究人员——从基因组学到气候模拟——可利用 o3‑pro 的文件分析与 Python 执行能力,在不受上下文长度限制的情况下自动化假设检验并生成洞见。
企业知识型工作流
在金融与法律等强调精确性与可审计性的行业中,o3‑pro 改进的指令遵循与多模态推理可降低合同审查、财务建模与合规任务的错误率。
软件开发与 DevOps
通过将长上下文代码理解与通过 Python 执行进行的实时测试结合,o3‑pro 简化调试并自动化复杂重构工作流,加速大型软件项目的交付周期。
组织在升级前应考虑什么?
成本效益分析
团队需权衡 10× 的价格提升与预期效率增益。对于高价值、低体量的任务——如撰写战略报告或构建关键安全系统——其准确性与工具支持或可证明 o3‑pro 的溢价合理。对于批量内容生成,继续使用标准版 o3 或 o4‑mini 模型可能更具经济性。
基础设施准备度
鉴于 o3‑pro 带来更高的延迟与吞吐要求,组织应审计其 API 速率限制、网络容量与错误重试策略,以避免峰值使用期间的瓶颈。
结论
OpenAI 的 o3‑pro 模型为高级推理、多模态理解与集成工具使用设定了新标杆。其基准提升与可靠性增强使其成为任务关键型应用的有吸引力选择,前提是预算与基础设施能够支撑更高的成本。随着 AI 版图演进,o3‑pro 将在要求最高准确性与上下文深度的领域巩固其角色,而更注重成本的工作负载则可能继续使用基础 o 系列模型或新兴的 mini 变体。