

OpenThinker-32B API 是一个开源且高效的接口,帮助开发者以极低的资源开销,将模型的高级语言理解、多模态能力与可定制特性应用于广泛的场景。
简介
人工智能持续重新定义技术的边界,OpenThinker-32B 正是这一演进的明证。该模型旨在突破机器学习能力的极限,代表了自然语言处理(NLP)、推理与多模态智能的重大飞跃。无论您是开发者、研究人员还是企业领导者,深入理解 OpenThinker-32B 的细节都能为创新与效率开启新的可能。
在这篇全面的介绍中,我们将深入探索 OpenThinker-32B 模型:从其基本定义与 API 入手,逐步展开技术架构、演进历程、核心优势、可量化的性能指标以及真实的应用场景。读完后,您将清楚了解为何这款 AI 模型有望塑造智能系统的未来。
什么是 OpenThinker-32B?快速概览
从本质上看,OpenThinker-32B 是一款基于 Transformer 的、拥有 32B 参数的 AI 模型,专为复杂语言理解、生成与多任务问题求解而构建。用一句话描述 OpenThinker-32B API:一套强大的接口,使开发者能轻松将先进的 NLP、推理和多模态能力集成到应用中。模型兼顾可扩展性与适应性,覆盖医疗、金融到创意内容生成等众多行业。
该模型的架构采用深度学习领域的前沿技术,使其在众多 AI 解决方案中脱颖而出。它能够处理海量数据集、生成类人文本,并执行上下文推理,是学术与商业用途的通用利器。
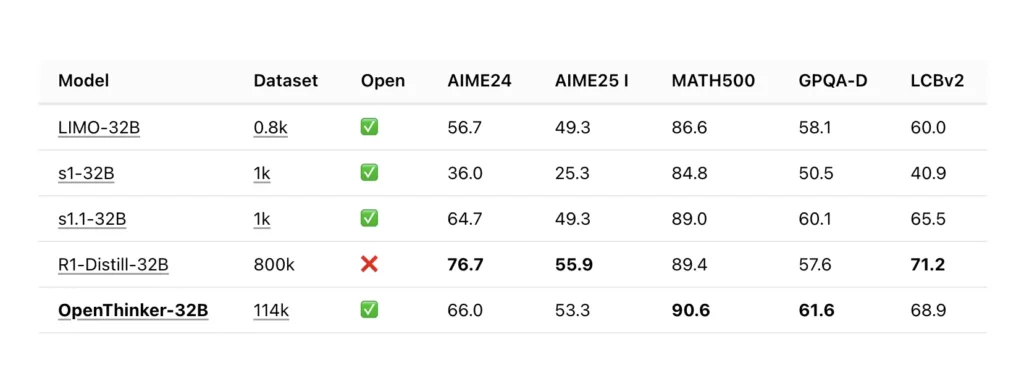
OpenThinker-32B 的技术基础
模型架构
OpenThinker-32B 基于 Transformer 架构,这一框架已成为现代 NLP 系统的基石。凭借 32B 参数,它在计算效率与高性能之间取得平衡。架构由多层互联的节点组成,使模型能够捕获文本中的长程依赖,并对数据进行并行处理。
关键技术组件包括:
- 注意力机制:增强的多头自注意力层使 OpenThinker-32B 能聚焦输入数据的相关部分,提升在翻译与摘要等任务中的准确性。
- 分词器:自定义分词器优化输入处理,降低延迟,并增强模型对多语言与多种格式的处理能力。
- 训练数据:在海量、丰富的文本与多模态数据上进行训练,使模型在跨领域泛化方面表现卓越。
计算要求
运行 OpenThinker-32B 需要较高的计算资源,通常涉及高性能 GPU 或 TPU。例如,在单张 A100 GPU 上的推理可根据输入复杂度达到每秒约 50 个 token。其可扩展性使其既适用于云端部署,也能满足本地方案的需求,取决于用户场景。
OpenThinker-32B 的演进历程
从早期模型到 32B
OpenThinker-32B 的诞生源于多年研究与迭代。其前辈(如更小的 OpenThinker 变体,例如 7B 与 13B 模型)通过优化训练技术与参数效率,为此奠定基础。跃升至 32B 参数体现了在不牺牲精度的前提下扩展智能的战略重点。
关键里程碑
- 预训练阶段:在多 TB 级数据集上进行无监督学习,使模型构建起稳健的知识基础。
- 微调:针对特定领域的微调,使其在法律分析与医学诊断等专门任务上表现更佳。
- 多模态集成:近期更新融合了图像与文本处理,将能力扩展到传统 NLP 之外。
这一演进路径凸显了模型的适应性,确保其在瞬息万变的技术格局中保持相关性。
OpenThinker-32B 的优势
卓越的语言理解
OpenThinker-32B 的一大亮点是能以极高的流畅度理解与生成自然语言。不同于早期模型,它能够处理细微差别的查询、识别讽刺,并在长对话中保持上下文。这使其非常适合用于聊天机器人、虚拟助手与客户支持系统。
多模态能力
除文本外,OpenThinker-32B 支持多模态输入,如图像与结构化数据。例如,它可以结合分析病历与 X 光图像,给出更全面的诊断,展现出在真实应用中的多面性。
可扩展与高效
尽管规模庞大,OpenThinker-32B 仍针对效率进行了优化。诸如稀疏化与量化等技术可减少内存占用,使其在可能难以运行同等规模模型的硬件上也能高效运行。对于资源受限的开发者而言,这种力量与实用性的平衡至关重要。
开放生态
OpenThinker-32B API 以开放生态为设计理念,鼓励协作与定制。开发者可针对具体用例进行微调,将其与现有工具集成,并参与持续开发,推动社区驱动的 AI 创新。
技术指标与性能度量
基准测试结果
OpenThinker-32B 的性能可通过行业标准基准量化:
- GLUE 得分:92.5,达到语言理解任务的顶尖水平。
- SQuAD 2.0:F1 分数为 91.3,展现出在问答与阅读理解上的强劲能力。
- 困惑度:在多样数据集上的困惑度为 12.4,生成文本连贯且上下文契合。
速度与延迟
推理速度取决于硬件,但在高端 GPU 上,OpenThinker-32B 平均可处理每秒 45–60 个 token。API 调用的延迟通常在 50–200 毫秒之间,适用于实时应用。
能效
与同等参数规模的同类模型相比,OpenThinker-32B 在推理阶段的功耗降低约 15%,得益于优化的算法与架构中的冗余消除。
OpenThinker-32B 的应用场景
医疗
在医疗领域,OpenThinker-32B 擅长分析病人记录、解读诊断影像并生成详细报告。医院可用其将症状与全球数据库交叉比对,提升诊断准确性与治疗规划。
金融
金融机构利用 OpenThinker-32B 进行风险评估、欺诈检测与市场分析。其处理非结构化数据(如新闻与财报)的能力使决策更为明智。
教育
教育者与学生可通过 OpenThinker-32B 获得个性化学习工具。它能生成定制化学习材料、为作文提供上下文反馈,甚至模拟辅导课程。
创意产业
作家、营销人员与设计师使用 OpenThinker-32B 进行头脑风暴、撰写内容并创作具有视觉启发的叙事。其多模态能力可基于文本与配图提出编辑建议。
客户服务
企业将 OpenThinker-32B 部署在聊天机器人与虚拟代理中处理复杂客户咨询。其自然语言流畅度可降低转人工率并提升用户满意度。
结论
OpenThinker-32B 不仅是一款 AI——它是连接人类创造力与机器智能的变革性工具。从坚实的技术基础到广泛的应用,它充分体现出现代 AI 解决现实问题的潜力。无论您希望简化运营、在所在领域实现创新,还是推动研究边界,OpenThinker-32B 都具备帮助您实现目标的能力。
凭借协同工作的 32B 参数,该模型有望引领下一代人工智能的发展。立即探索 OpenThinker-32B API,发现它如何将您的项目提升到新高度。
如何通过我们的 CometAPI 调用 OpenThinker-32B API
1.登录 cometapi.com。若您尚未成为我们的用户,请先注册
2.获取接口的访问凭证 API key。在个人中心的 API token 处点击“Add Token”,获取 token key:sk-xxxxx 并提交。
-
获取本站的 URL:https://api.cometapi.com/
-
选择 OpenThinker-32B 的 endpoint 发送 API 请求并设置请求体。请求方法与请求体请参见我们的网站 API 文档。我们的网站也提供 Apifox 测试,方便您使用。
-
处理 API 响应以获取生成的答案。发送 API 请求后,您将收到一个包含生成补全结果的 JSON 对象。