

在快速演进的人工智能版图中,2025 年见证了大型语言模型(LLMs)的重大进展。处于领先行列的有 Alibaba 的 Qwen2.5、DeepSeek 的 V3 与 R1 模型,以及 OpenAI 的 ChatGPT。它们各自带来了独特的能力与创新。本文深入探讨围绕 Qwen2.5 的最新发展,并将其特性与性能与 DeepSeek 和 ChatGPT 进行对比,以判断目前谁在这场 AI 竞赛中领先。
什么是 Qwen2.5?
概述
Qwen 2.5 是 Alibaba Cloud 最新的稠密、仅解码器大型语言模型,提供从 0.5B 到 72B 参数的多种规模。它针对指令跟随、结构化输出(如 JSON、表格)、编程与数学问题求解进行了优化。凭借对 29+ 种语言的支持与最高 128K token 的上下文长度,Qwen2.5 面向多语言与领域特定的应用设计。
关键特性
- 多语言支持:支持 29+ 种语言,服务全球用户。
- 扩展的上下文长度:可处理最高 128K token,支持长文档与长对话。
- 专用变体:包含适用于编程任务的 Qwen2.5-Coder 与面向数学问题求解的 Qwen2.5-Math 等模型。
- 可访问性:可通过 Hugging Face、GitHub 等平台,以及新上线的网页界面 chat.qwenlm.ai 获取。
如何在本地使用 Qwen 2.5?
下面是针对 7 B Chat 检查点的分步指南;更大规模仅在 GPU 要求上有所不同。
1. 硬件先决条件
| 模型 | 8 位所需显存 | 4 位所需显存(QLoRA) | 磁盘大小 |
|---|---|---|---|
| Qwen 2.5‑7B | 14 GB | 10 GB | 13 GB |
| Qwen 2.5‑14B | 26 GB | 18 GB | 25 GB |
单张 RTX 4090(24 GB)即可在完整 16 位精度下进行 7 B 推理;两张同款显卡或结合 CPU 卸载与量化可支持 14 B。
2. 安装
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. 快速推理脚本
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
由于 Qwen 提供了自定义的旋转位置嵌入(Rotary Position Embedding)封装器,因此需要使用 trust_remote_code=True 标志。
4. 使用 LoRA 微调
得益于参数高效的 LoRA 适配器,你可以在单张 24 GB GPU 上,用约 50 K 的领域配对数据(例如医学)在四小时内对 Qwen 进行专项训练:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
得到的适配器文件(约 120 MB)可回并或按需加载。
可选:将 Qwen 2.5 作为 API 运行
CometAPI 充当多个领先 AI 模型 API 的集中式枢纽,免去分别接入多个 API 提供商的需求。CometAPI 提供远低于官方价格的方案,帮助你集成 Qwen API;注册并登录后你将获得账户内 $1!欢迎注册体验 CometAPI。面向希望将 Qwen 2.5 集成到应用中的开发者:
步骤 1:安装必要的库:
bash
pip install requests
步骤 2:获取 API Key
步骤 3:实现 API 调用
使用 API 凭据向 Qwen 2.5 发起请求。将 <YOUR_AIMLAPI_KEY> 替换为你账户中的实际 CometAPI 密钥。
例如,使用 Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
此集成允许将 Qwen 2.5 的能力无缝融入各类应用,提升功能与用户体验。选择 “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” 端点发送 API 请求并设置请求体。请求方法与请求体请参见我们网站的 API 文档。我们的网站也提供 Apifox 测试以便你使用。
有关集成细节,请参见 Qwen 2.5 Max API。CometAPI 已更新最新的 QwQ-32B API。更多关于 Comet API 的模型信息请见 API doc。
最佳实践与提示
| 场景 | 建议 |
|---|---|
| 长文档问答 | 将段落分块至 ≤16 K token,并使用检索增强提示替代朴素的 100 K 上下文,以降低时延。 |
| 结构化输出 | 在系统消息前加前缀:You are an AI that strictly outputs JSON. Qwen 2.5 的对齐训练在受约束生成方面表现优异。 |
| 代码补全 | 设置 temperature=0.0 与 top_p=1.0 以最大化确定性,然后采样多束(num_return_sequences=4)进行排序。 |
| 安全过滤 | 使用 Alibaba 开源的 “Qwen‑Guardrails” 正则表达式集合或 OpenAI 的 text‑moderation‑004 作为第一道筛查。 |
Qwen 2.5 的已知局限
- 提示注入易感性。外部审计显示 Qwen 2.5‑VL 的越狱成功率为 18%,提醒我们仅靠模型规模并不能免疫对抗性指令。
- 非拉丁字符的 OCR 噪声。在针对视觉‑语言任务进行微调时,模型的端到端流程有时会混淆繁体与简体中文的字形,需要领域特定的校正层。
- 在 128 K 时的 GPU 显存断崖。FlashAttention‑2 可部分抵消内存占用,但在 72 B 的稠密前向中跨越 128 K token 仍需 >120 GB 显存;实践中应使用窗口化注意或 KV 缓存。
路线图与社区生态
Qwen 团队已暗示将推出 Qwen 3.0,目标是混合路由主干(Dense + MoE)与统一的语音‑视觉‑文本预训练。与此同时,生态中已包含:
- Q‑Agent —— 一个 ReAct 风格的思维链代理,使用 Qwen 2.5‑14B 作为策略。
- Chinese Financial Alpaca —— 基于 Qwen2.5‑7B 的 LoRA,使用 100 万份监管文件进行训练。
- Open Interpreter 插件 —— 在 VS Code 中将 GPT‑4 替换为本地 Qwen 检查点。
请查看 Hugging Face 的 “Qwen2.5 collection” 页面,获取持续更新的检查点、适配器与评测工具链列表。
对比分析:Qwen2.5 与 DeepSeek、ChatGPT
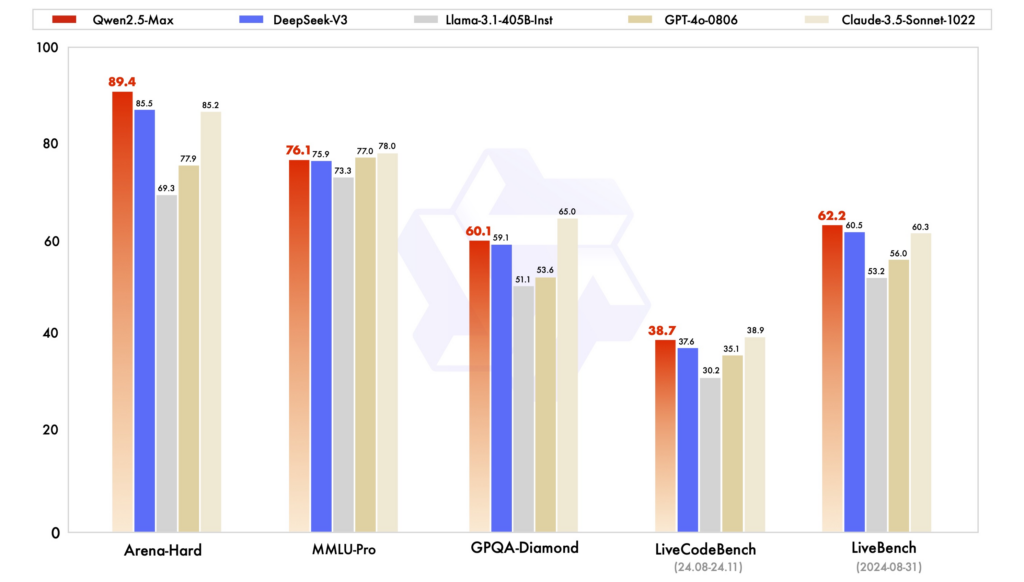
性能基准: 在各类评测中,Qwen2.5 在推理、编程与多语言理解任务上表现强劲。采用 MoE 架构的 DeepSeek‑V3 在效率与可扩展性方面更具优势,以更少的计算资源实现高性能。ChatGPT 在通用语言任务上依然稳健。
效率与成本: DeepSeek 的模型因其具备成本高效的训练与推理而突出,利用 MoE 架构在每个 token 只激活必要参数。Qwen2.5 虽为稠密模型,但通过专用变体优化特定任务的性能。ChatGPT 的训练使用了大量算力,这也反映在其运营成本上。
可访问性与开源可用性:Qwen2.5 与 DeepSeek 在不同程度上拥抱开源原则,模型可在 GitHub 与 Hugging Face 等平台获取。Qwen2.5 最近上线的网页界面进一步提升了可访问性。ChatGPT 虽非开源,但可通过 OpenAI 的平台与各类集成广泛使用。
结论
Qwen 2.5 处于“闭源高端服务”与“完全开源的兴趣模型”之间的甜蜜点。其宽松许可、多语言优势、长上下文能力与广泛的参数规模组合,使其成为研究与生产的有力基石。
随着开源 LLM 版图的加速前行,Qwen 项目展现了“透明与性能可以并存”。对于开发者、数据科学家与政策制定者而言,今天掌握 Qwen 2.5,是迈向更加多元、鼓励创新的 AI 未来的一项投资。