

阿里巴巴在人工智能领域的最新进展——Qwen3-Coder——标志着在由 AI 驱动的软件开发快速演进的格局中迈出的重要一步。Qwen3-Coder 于 2025 年 7 月 23 日发布,是一款开源的、代理式编码模型,旨在自主处理复杂的编程任务,从生成样板代码到覆盖整个代码库的调试。该模型基于前沿的专家混合(MoE)架构构建,拥有 480 billion 参数,每个 token 激活 35 billion 参数,在性能与计算效率之间实现最佳平衡。本文将探讨 Qwen3‑Coder 的差异化特性,审视其基准表现,拆解其技术创新,为开发者提供最佳用法指南,并评估其市场反馈与未来前景。
Qwen3‑Coder 是什么?
Qwen3‑Coder 是 Qwen 系列中最新的代理式编码模型,正式发布于 2025 年 7 月 22 日。作为“迄今为止最具代理性的代码模型”,其旗舰变体 Qwen3‑Coder‑480B‑A35B‑Instruct 采用 Mixture‑of‑Experts(MoE)设计,具备 480 billion 总参数,每个 token 激活 35 billion 参数。它原生支持最长 256K token 的上下文窗口,并通过外推技术扩展至 1 million token,满足仓库级代码理解与生成的需求。
采用 Apache 2.0 开源
秉承阿里巴巴对社区驱动开发的承诺,Qwen3‑Coder 在 Apache 2.0 许可下发布。开源可用性确保了透明度,促进第三方贡献,并加速其在学术界与工业界的采纳。研究人员与工程师可获取预训练权重,并针对金融科技、科学计算等垂直领域进行微调。
从 Qwen2.5 演进
Qwen3‑Coder 建立在 Qwen2.5‑Coder 的成功基础上,后者提供从 0.5B 到 32B 参数规模的模型,并在代码生成基准上取得 SOTA 成绩。Qwen3‑Coder 通过更大规模、增强的数据管线与全新的训练机制进一步扩展其前身能力。Qwen2.5‑Coder 在超过 5.5 trillion token 上训练,配以严格的数据清洗与合成数据生成;Qwen3‑Coder 进一步以 7.5 trillion token(代码占比 70%)进行训练,并利用先前模型过滤与重写噪声输入,以提升数据质量。
Qwen3‑Coder 的主要差异化创新是什么?
多项关键创新使 Qwen3‑Coder 脱颖而出:
- 代理式任务编排:不仅仅生成片段,Qwen3‑Coder 可在无人干预的情况下自主串联多步操作——阅读文档、调用工具、验证输出。
- 增强的思考预算:开发者可配置每一步推理所投入的算力,在速度与充分性之间实现可定制的权衡,这对大规模代码合成至关重要。
- 无缝工具集成:Qwen3‑Coder 的命令行界面 “Qwen Code” 通过适配函数调用协议与定制提示,与主流开发者工具无缝集成,便于嵌入现有的 CI/CD 流水线与 IDE。
Qwen3‑Coder 相较竞品的表现如何?
基准对比
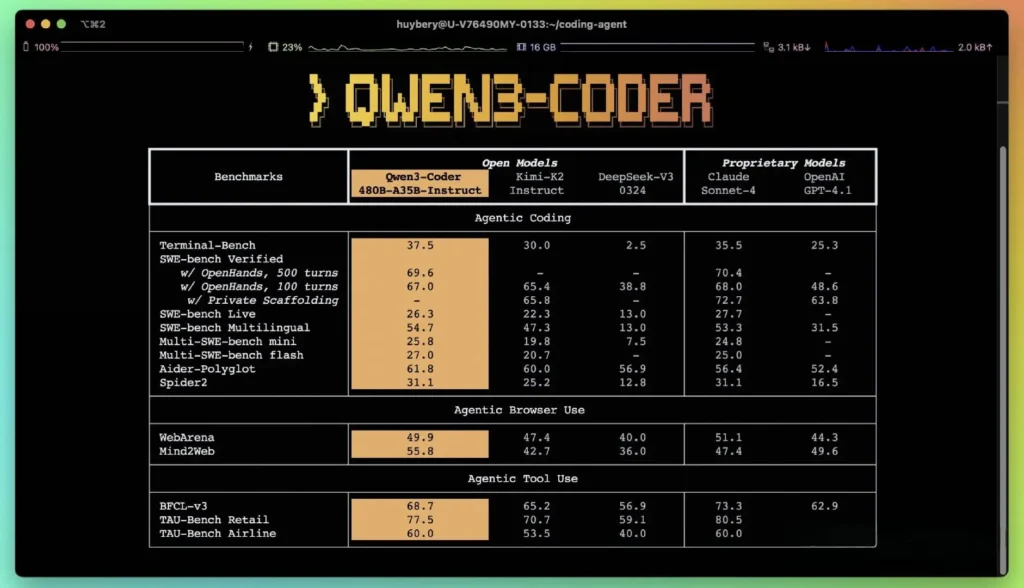
根据阿里巴巴发布的性能指标,Qwen3‑Coder 在多个基准上优于国内领先替代方案——如 DeepSeek 的 codex 风格模型与 Moonshot AI 的 K2——并在编码能力上与美国顶尖产品相当或更胜一筹。在第三方评测中:
- Aider Polyglot:Qwen3‑Coder‑480B 取得 61.8% 的分数,展现出强劲的多语言代码生成与推理能力。
- MBPP 与 HumanEval:独立测试报告显示,Qwen3‑Coder‑480B‑A35B 在功能正确性与复杂提示处理方面均优于 GPT‑4.1,尤其是在多步编码挑战中表现突出。
- 480B 参数变体在 SWE‑Bench Verified 套件上达到超过 85% 的执行成功率——超越 DeepSeek 的顶级模型(78%)与 Moonshot 的 K2(82%),并与 Claude Sonnet 4(86%)非常接近。
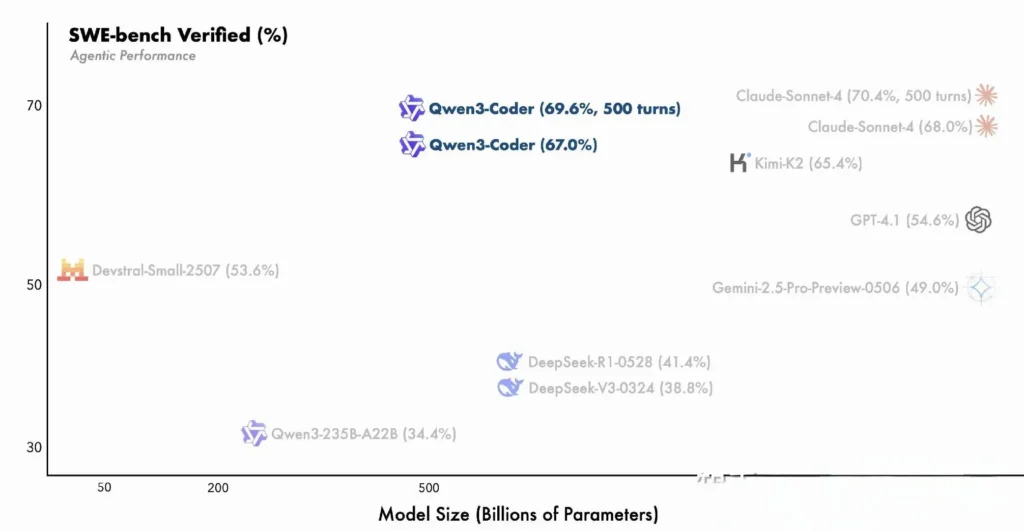
与专有模型的比较
阿里巴巴声称,Qwen3‑Coder 在端到端编码工作流中的代理式能力与 Anthropic 的 Claude 和 OpenAI 的 GPT‑4 相当,这对于一款开源模型而言颇为不凡。早期测试者报告其多轮规划、动态工具调用与自动错误修正能力,能够以极少的人类提示处理复杂任务——如构建全栈 Web 应用或集成 CI/CD 流水线。这些能力受益于模型通过代码执行进行自我验证的能力,而这在纯生成式 LLM 中并不突出。
Qwen3‑Coder 背后的技术创新有哪些?
专家混合(MoE)架构
Qwen3‑Coder 的核心是一种最先进的 MoE 设计。与每个 token 都激活全部参数的致密模型不同,MoE 架构会选择性地启用针对特定 token 类型或任务的专用子网络(专家)。在 Qwen3‑Coder 中,480 billion 总参数分布在多个专家上,每个 token 仅激活 35 billion 参数。与同等致密模型相比,这种方法将推理成本削减超过 60%,同时在代码合成与调试方面保持高保真度。
思考模式与非思考模式
借鉴更广泛的 Qwen3 系列创新,Qwen3‑Coder 集成了双模式推理框架:
- 思考模式为复杂、多步推理任务(如算法设计或跨文件重构)分配更高的“思考预算”。
- 非思考模式提供快速、上下文驱动的响应,适用于简单的代码补全与 API 用法片段。
这种统一的模式切换消除了为聊天优化与推理优化任务分别切换模型的需求,从而简化了开发者工作流。
通过自动化测试用例合成的强化学习
Qwen3‑Coder 的一项亮点是原生 256K token 的上下文窗口——是领先开源模型典型容量的两倍——并通过外推方法(例如 YaRN)支持最多 1 million token。这使模型能够在单次处理中覆盖整个代码仓库、文档集或多文件项目,保留跨文件依赖并减少重复提示。经验测试表明,上下文窗口扩展在长周期任务性能上带来递减但仍然显著的收益,尤其是在受环境驱动的强化学习场景中。
开发者如何访问和使用 Qwen3‑Coder?
Qwen3‑Coder 的发布策略强调开放性与易用性:
- 开源模型权重:所有模型检查点在 GitHub 上以 Apache 2.0 许可提供,确保完全透明并促进社区驱动的改进。
- 命令行界面(Qwen Code):基于 Google Gemini Code 分叉而来,CLI 支持定制提示、函数调用与插件架构,可与现有构建系统和 IDE 无缝集成。
- 云与本地部署:预配置的 Docker 镜像与 Kubernetes Helm chart 便于在云环境中进行可扩展部署,而本地量化方案(2–8 bit 动态量化)则让在普通 GPU 上进行高效本地推理成为可能。
- 通过 CometAPI 的 API 访问:开发者也可通过如 CometAPI 等平台的托管端点与 Qwen3‑Coder 交互,这些平台以相同价格提供 Open source(
qwen3-coder-480b-a35b-instruct)与商用版本(qwen3-coder-plus; qwen3-coder-plus-2025-07-22)。商用版本支持 1M 长上下文。 - Hugging Face:Alibaba 已将 Qwen3‑Coder 的权重及配套库免费发布到 Hugging Face 与 GitHub,并以 Apache 2.0 许可打包,允许学术与商业用途且无需版税。
通过 CometAPI 进行 API 和 SDK 集成
CometAPI 是一个统一的 API 平台,将来自 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等领先提供商的 500+ AI 模型聚合到一个对开发者友好的接口中。通过一致的认证、请求格式与响应处理,CometAPI 大幅简化了将 AI 能力集成到应用中的流程。无论你在构建聊天机器人、图像生成器、音乐作曲器,还是数据驱动的分析管道,CometAPI 都可帮助更快迭代、控制成本并保持供应商无关性,同时利用 AI 生态的最新突破。
开发者可通过 CometAPI 提供的兼容 OpenAI 风格的 API 与Qwen3-Coder交互。CometAPI 以相同价格提供 Open source(qwen3-coder-480b-a35b-instruct)与商用版本(qwen3-coder-plus; qwen3-coder-plus-2025-07-22)。商用版本支持 1M 长上下文。Python 示例代码(使用兼容 OpenAI 的客户端)及最佳实践推荐采样参数为 temperature = 0.7、top_p = 0.8、top_k = 20、repetition_penalty = 1.05。输出长度可扩展至 65,536 token,适用于大型代码生成任务。
首先可在Playground中探索模型能力,并查阅API guide获取详细说明。访问前,请确保你已登录 CometAPI 并获得 API key。
在 Hugging Face 和 Alibaba Cloud 上的快速开始
渴望尝试 Qwen3‑Coder 的开发者可在 Hugging Face 上找到仓库 Qwen/Qwen3‑Coder‑480B‑A35B‑Instruct。集成可通过 transformers 库(版本 ≥ 4.51.0,以避免 KeyError: 'qwen3_moe')以及兼容 OpenAI 的 Python 客户端顺畅完成。最小示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
input_ids = tokenizer("def fibonacci(n):", return_tensors="pt").input_ids
output = model.generate(input_ids, max_length=200, temperature=0.7, top_p=0.8, top_k=20, repetition_penalty=1.05)
print(tokenizer.decode(output))
定义自定义工具与代理式工作流
Qwen3‑Coder 的一项突出特性是动态工具调用。开发者可注册外部工具——如 linter、formatter、测试运行器——并允许模型在编码会话中自主调用。这一能力将 Qwen3‑Coder 从被动的代码助手转变为主动的编码代理,能够运行测试、调整代码风格,甚至根据对话意图部署微服务。
Qwen3‑Coder 能够启用哪些潜在应用与未来方向?
通过将开源自由与企业级性能相结合,Qwen3‑Coder 为新一代 AI 驱动的开发工具铺平道路。从自动化代码审计与安全合规检查,到持续重构服务与 AI 驱动的 DevOps 助手,该模型的多样性正在激发初创公司与内部创新团队的灵感。
软件开发工作流
早期采用者报告,在样板代码编写、依赖管理与初始脚手架方面的耗时减少 30–50%,使工程师能够专注于高价值的设计与架构任务。持续集成套件可借助 Qwen3‑Coder 自动生成测试、检测回归,甚至基于实时代码分析提出性能优化建议。
企业应用
随着金融、医疗与电商等行业将 Qwen3‑Coder 集成进关键业务系统,用户团队与阿里巴巴研发之间的反馈循环将加速改进——包括面向领域的微调、增强的安全协议与更紧密的 IDE 插件。此外,阿里巴巴的开源战略鼓励全球社区贡献,促进形成活跃的扩展生态、基准与最佳实践库。
结论
总而言之,Qwen3‑Coder 是软件工程开源 AI 的里程碑:一款强大的代理式模型,它不仅能写代码,还能以最少的人类监督编排整个开发流水线。通过使该技术自由可用且易于集成,阿里巴巴正在让先进 AI 工具的使用更加民主化,并为一个软件创作更加协作、高效与智能的时代奠定基础。
常见问题
是什么让 Qwen3‑Coder “具有代理性”?
代理式 AI 指能够自主规划并执行多步任务的模型。Qwen3‑Coder 能够调用外部工具、运行测试并在无人干预的情况下管理代码库,正是这一范式的体现。
Qwen3‑Coder 是否适用于生产环境?
尽管 Qwen3‑Coder 在基准与真实世界测试中表现强劲,企业在集成到关键生产工作流前应进行面向领域的评估,并实施防护措施(例如输出验证流水线)。
专家混合架构如何惠及开发者?
MoE 通过在每个 token 上仅激活相关子网络,大幅降低推理成本,从而加快生成并减少计算开销。这种效率对于在云环境中扩展 AI 编码助手至关重要。