

DeepSeek 已发布 DeepSeek V3.2 作为其 V3.x 系列的继任者,并同时推出配套的 DeepSeek-V3.2-Speciale 变体,公司将其定位为面向代理/工具使用的高性能、以推理为先的版本。V3.2 基于实验性工作(V3.2-Exp)构建,引入了更强的推理能力、为“金牌级”数学/竞赛编程表现优化的 Speciale 版本,以及 DeepSeek 所称首创的双模式“思考 + 工具”系统,将内部的逐步推理与外部工具调用和代理工作流紧密集成。
什么是 DeepSeek V3.2 —— 以及 V3.2-Speciale 有何不同?
DeepSeek-V3.2 是 DeepSeek 的实验分支 V3.2-Exp 的官方继任者。DeepSeek 将其描述为一个**“以推理为先”的面向代理的模型家族**,即模型不仅为自然的对话质量而调优,更专门针对多步推理、工具调用,以及在包含外部工具(API、代码执行、数据连接器)的环境中实现可靠的链式思考风格推理。
什么是 DeepSeek-V3.2(基础版)
- 被定位为 V3.2-Exp 实验线的主流生产继任者;计划通过 DeepSeek 的应用/网页/API 广泛提供。
- 在计算效率与面向代理任务的稳健推理之间保持平衡。
什么是 DeepSeek-V3.2-Speciale
DeepSeek-V3.2-Speciale 是一个由 DeepSeek 推出的更高能力“特别版”,针对比赛级推理、高阶数学与代理性能进行了调优。其被宣传为“推动推理能力边界”的更高能力变体。目前 Speciale 仅通过 API 提供并采用临时访问路由;早期基准结果显示其定位于与高端闭源模型在推理与编码基准上竞争。
哪些传承与工程选择促成了 V3.2?
V3.2 继承了 DeepSeek 在 2025 年公开的一系列迭代工程谱系:V3 → V3.1(Terminus)→ V3.2-Exp(一个实验步骤)→ V3.2 → V3.2-Speciale。实验版 V3.2-Exp 引入了 DeepSeek Sparse Attention (DSA) —— 一种细粒度稀疏注意力机制,旨在在超长上下文长度下降低内存与计算成本,同时保持输出质量。该 DSA 研究与成本优化工作成为官方 V3.2 家族的技术踏板。
官方版 DeepSeek 3.2 有哪些新变化?
1) 增强的推理能力 —— 推理究竟如何提升?
DeepSeek 将 V3.2 宣传为**“以推理为先”**。这意味着架构与微调专注于可靠执行多步推理、维持内部思维链,并支持代理在使用外部工具时所需的结构化审慎推断。
具体改进包括:
- 训练与 RLHF(或类似对齐流程)侧重鼓励显式的逐步问题求解与稳定的中间状态(有助于数学推理、多步代码生成与逻辑任务)。
- 架构与损失函数的选择,能够保留更长的上下文窗口,并让模型更高保真地引用先前的推理步骤。
- 实用模式(见下文“双模式”)允许同一模型在更快的“聊天”风格模式与更审慎的“思考”模式间运行:在“思考”模式下,模型会有意识地先经过中间步骤再采取行动。
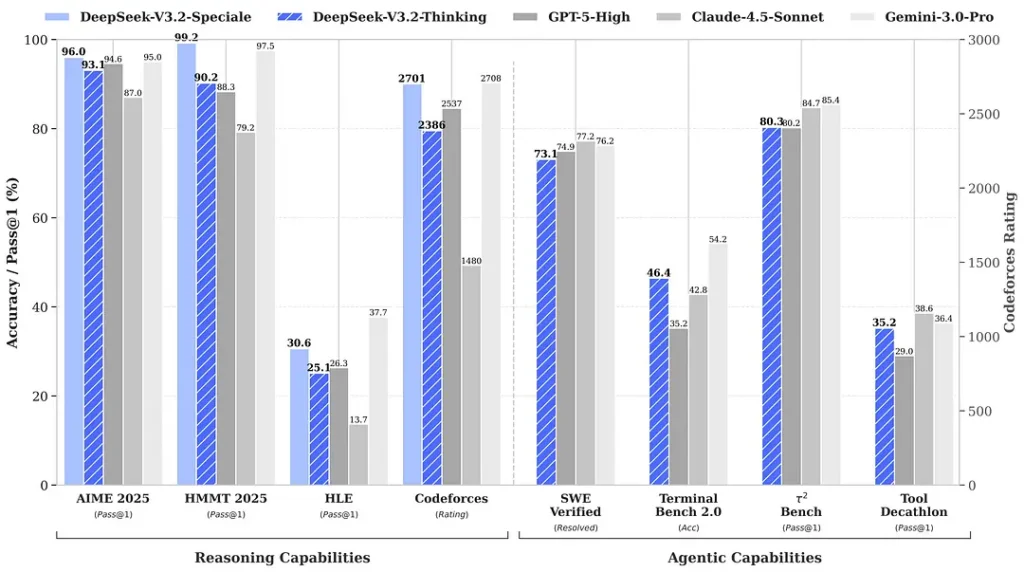
围绕发布所引用的基准宣称在数学与推理套件上取得显著提升;独立的早期社区基准也在竞争性评测集上报告了令人印象深刻的成绩:
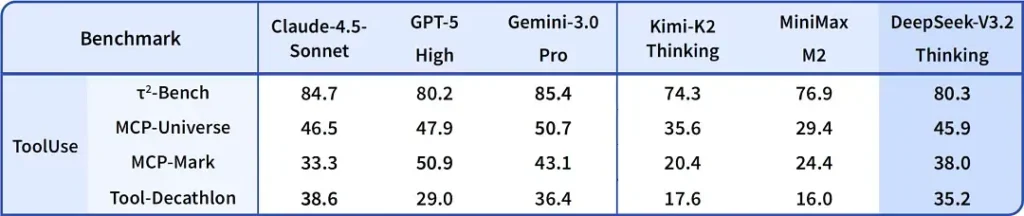
2) 特别版的突破性表现 —— 具体好多少?
DeepSeek-V3.2-Speciale 被称在推理准确性与代理编排方面相较标准版 V3.2 带来进一步提升。提供方将 Speciale 定位为面向重型推理工作负载与高难代理任务的性能层级;其目前仅通过 API 提供,作为临时的更高能力端点(DeepSeek 表示 Speciale 的可用性初期会受限)。Speciale 版本整合了此前的数学模型 DeepSeek-Math-V2;它可以自行证明数学定理并验证逻辑推理;它在多个世界级赛事中取得了非凡成绩:
- 🥇 IMO(国际数学奥林匹克)金牌
- 🥇 CMO(中国数学奥林匹克)金牌
- 🥈 ICPC(国际大学生程序设计竞赛)人类赛第二名
- 🥉 IOI(国际信息学奥林匹克)人类赛第十名
| 基准 | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) 首次实现“双模式”——“思考 + 工具”系统
V3.2 中一个非常实用且有趣的主张是双模式工作流,它区分(并允许你在两者间选择)快速的对话式运行与更慢、更审慎的“思考”模式,并与工具使用紧密集成。
- “Chat / fast” 模式: 为低延迟、面向用户的聊天而设计,输出简洁、内部推理痕迹较少——适合轻量帮助、短问答与对速度敏感的应用。
- “Thinking / reasoner” 模式: 针对严格的链式思考、逐步规划以及外部工具(API、数据库查询、代码执行)的编排进行了优化。在“思考”模式下,模型会产生更明确的中间步骤,这些步骤可供检查或用于在代理系统中驱动安全、正确的工具调用。
这一模式(双模式设计)在早期实验分支中就已出现,DeepSeek 在 V3.2 与 Speciale 中做了更深入的集成——当前 Speciale 仅支持思考模式(因此采用 API 限制)。在需要与现实系统交互的代理构建中,能在速度与审慎之间切换尤为有价值,因为它让开发者可以为延迟与可靠性选择合适的权衡。
为何值得关注: 许多现代系统要么提供强链式思考的模型(用于解释推理),要么提供独立的代理/工具编排层。DeepSeek 的表述暗示更紧密的耦合——模型可以先“思考”,再确定性地调用工具,并用工具响应来指导后续思考——这对构建自主代理的开发者而言更为顺畅。
如何获取 DeepSeek v3.2
简短回答——根据你的需求,有多种方式获得 DeepSeek v3.2:
- 官方网页/应用(在线使用)——通过 DeepSeek 的网页界面或移动应用交互使用 V3.2。
- API 访问——DeepSeek 通过其 API 暴露 V3.2(文档包含模型名称/base_url 与定价)。注册 API Key 并调用 v3.2 端点。
- 可下载/开放权重(Hugging Face)——模型(V3.2 / V3.2-Exp 变体)已在 Hugging Face 发布并可下载(开放权重)。使用
huggingface-hub或transformers拉取文件。 - CometAPI——一个 AI API 聚合平台,提供托管的 V3.2-Exp 端点。价格低于官方价格。
几个实用提示:
- 若你希望本地运行权重,前往 Hugging Face 模型页面(按要求接受许可/访问条件),并使用
huggingface-cli或transformers下载;GitHub 仓库通常会展示具体命令。 - 若你希望通过 API 进行生产使用,请参考所选平台(如 cometapi)的 API 文档以获取端点名称以及 V3.2 变体的正确
base_url。
DeepSeek-V3.2-Speciale:
- 仅开放研究用途,支持“Thinking Mode”对话,但不支持工具调用。
- 最大输出可达 128K tokens(超长思维链)。
- 目前免费测试至 2025 年 12 月 15 日。
最后想法
DeepSeek-V3.2 标志着以推理为中心的模型走向成熟的有意义一步。其将多步推理的改进、专门的高性能版本(Speciale)以及“思考 + 工具”集成生产化结合在一起,对于构建需在审慎推理与外部动作间交替的高级代理、编码助手或研究工作流而言,值得关注。
开发者可通过 CometAPI 访问 DeepSeek V3.2。开始前,可在 Playground 体验 CometAPI 的模型能力,并查阅 API guide 获取详细说明。访问前请确保你已登录 CometAPI 并获取 API Key。CometAPI 提供远低于官方价格的方案,帮助你集成。
Ready to Go?→ Sign up for CometAPI today !