

Gemini Embedding 2 是 Google 的首个原生多模态嵌入模型,可将文本、图像、音频、视频和 PDF 映射到单一的 3,072 维语义向量空间(支持可配置输出大小)。它引入 Matryoshka 表示学习,以提供嵌套/可截断的嵌入,提升多语言表现(100+ 种语言),并针对特定任务提供优化控制(例如 task:search、task:code)。
What is Gemini Embedding 2?
Gemini Embedding 2 是 Google 的统一嵌入模型,可将多种输入模态——文本、图像、音频、视频与文档——映射到同一个语义向量空间。每个嵌入默认是一个 3,072 维的浮点向量,用于表示输入的语义含义,使得语义相似的条目(无论模态)在向量空间中彼此接近。其核心能力包括:
- 广泛的语言与格式覆盖:单一模型同时接受文本、图像、音频、视频与文档,并置于同一语义向量空间。文档显示 Gemini Embedding 2 能捕获100+ 种语言的语义意图,并接受常见文件格式(PNG/JPEG、MP4/MOV、MP3/WAV、PDF),且给出了具体的每请求限制(例如每次请求最多几张图片或音/视频的几十秒时长——见下文“如何使用”)。
- 真正的多模态:单一模型同时接受文本、图像、音频、视频与文档,并置于同一语义向量空间,从而实现跨模态比较或检索(例如 文本→图像、音频→文本)。
- 较大的默认维度与灵活截断:模型默认输出3072 维向量,但通过*Matryoshka 表示学习(MRL)*将最重要的语义信息集中在靠前的维度,因此可截断至 1536、768(或更低)而检索质量仅有温和下降。这在存储与计算成本之间提供更优权衡。
为何重要。 过去的嵌入大多是仅限文本,或需要为不同模态配备独立编码器并辅以复杂的跨模态对齐层。Gemini Embedding 2 通过对多种格式的原生支持,打破了这一障碍——文本查询即可直接按语义相似度检索图像或短视频片段,无需中间转写或手动映射。这简化了 RAG(检索增强生成)、语义搜索与多模态检索管线。
Key features & capabilities (what’s new)
1. 真正的原生多模态(一个嵌入空间)
单一模型同时接受文本、图像、音频、视频与文档,并置于同一语义向量空间。Gemini Embedding 2 将文本、图像、音频、视频和文档映射到相同的嵌入空间,因此跨模态检索(文本→图像、音频→文本)可直接工作,无需跨模型对齐。这降低了管线复杂度并简化了 RAG(检索增强生成)技术栈。
2. 3,072 维默认向量与可调输出
Gemini Embedding 2 默认输出3072 维向量,同时利用*Matryoshka 表示学习(MRL)*将最重要的语义内容集中在前部维度,使其可截断至 1536、768(或更低),且仅带来温和的检索质量下降。这在存储与计算成本之间提供更优的折中。
3. Matryoshka 表示学习(MRL)
MRL 产生“嵌套”的嵌入——就像俄罗斯套娃——因此更低维度的切片仍能保留更高层语义。这使系统在无需维护多套不同嵌入模型的情况下,自由选择运行点(存储/精度权衡)。早期博客分析与文档将这一技术描述为实现灵活性的核心创新。
4. 任务提示/自定义嵌入目标
API 接受 task 提示(例如 task:search、task:code retrieval、task:semantic-similarity),从而让模型为特定下游关系优化嵌入几何结构——类似于早期嵌入系统中的任务条件化,但扩展至多模态输入。
5. 语言与模态广度
文档显示可捕获100+ 种语言的语义意图,并接受常见文件格式(PNG/JPEG、MP4/MOV、MP3/WAV、PDF),同时对每次请求给出具体限制(例如每次请求最多几张图片或音/视频的几十秒时长——见下文“如何使用”)。
Performance benchmarks
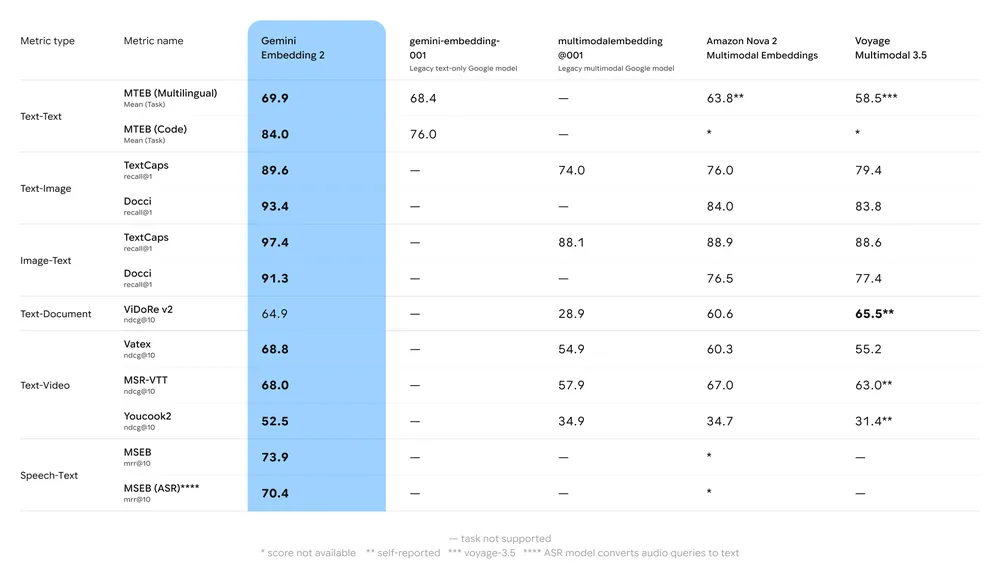
基准要点摘要:
- MTEB(大规模文本嵌入基准):据报在英文与多语言任务的 MTEB 排行榜上具有较强表现;分析显示较上一代 Gemini 嵌入模型和多款专有替代品有显著提升。
- 多模态检索:在跨模态相似度(例如 文本→图像检索)上,由于原生多模态训练,表现超越或匹配领先的单模态嵌入。
- 延迟与吞吐:采用云托管生成嵌入,但对延迟敏感的场景可考虑使用截断向量或替代的轻量嵌入模型以满足边缘侧需求。
Gemini Embedding 2 vs gemini-embedding-001 and text-embedding-3-large
| Attribute | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Release / availability | Mar 10, 2026 — public preview (Gemini API / Vertex AI). | Earlier Gemini embedding (text-only variants) — GA earlier. | Announced Jan 2024 (text-only GA). |
| Modalities supported | Text, images, audio, video, documents (PDF) — unified vector space. | Text (primarily). | Text only (high-quality multilingual). |
| Default embedding dim. | 3072 (MRL / truncation recommended: 1536, 768). | 3072 (for large) — text only. | 3072 (text-embedding-3-large). |
| Reported MTEB (example) | High-60s on MTEB; shows 68.17 at 1536 in vendor table (see docs). | gemini-embedding-001 reported ~68.32 mean in some leaderboards. | ~64.6 (MTEB average reported by OpenAI for text-embedding-3-large). |
| Native audio/video support | Yes (direct audio/video embedding). | No (text only). | No (text only). |
| Typical use cases | Multimodal retrieval, RAG, semantic search across file types, speech retrieval, video search. | Text retrieval, multilingual RAG. | Text retrieval, semantic search, RAG — strong multilingual text performance. |
Technical specs & limits
Default & adjustable embedding size
- 默认: 3,072 维。
- 可调: 通过
output_dimensionality参数可请求更低维度输出以节省存储/CPU。拥有海量向量库的场景往往将维度降至 512–1,024 以降低成本,但需接受一定精度权衡。
Supported modalities and per-request limits
- Images: PNG、JPEG —— 每次请求最多 6 张(厂商报告的限制)。
- Video: MP4、MOV —— 厂商报告单次请求对单个视频最长支持 ~128 秒。
- Audio: MP3、WAV —— 厂商报告单个音频输入最长 ~80 秒。
- Documents: PDFs —— 每次请求最多 6 页(厂商报告)。
- 文本内容的 Token 限制: 模型支持较大的文本输入;实际的每请求 token 上限请参阅 API 文档与 Vertex AI 配额。
Availability & access
- 公开预览: Gemini Embedding 2 以公开预览发布,可通过 Gemini API 与 Google Cloud 的 Vertex AI 立即试用
Frequently asked questions (FAQ)
Q1: What modalities does Gemini Embedding 2 support?
A: 文本、图像(PNG/JPEG)、视频(MP4/MOV)、音频(MP3/WAV)以及 PDF 文档——全部映射到同一语义向量空间。
Q2: What is the default vector size for Gemini Embedding 2?
A: 默认是3,072 维。你可以通过 API 请求更小的输出维度。
Q3: Is Gemini Embedding 2 available now?
A: 是的——它已作为公开预览发布,可通过 Gemini API 与 Vertex AI 获取(查看模型 ID gemini-embedding-2-preview 以及当前更新日志)。
Q4: How does it compare to embeddings from other providers?
A: 独立厂商测试报告称,Gemini Embedding 2 在多语言文本方面名列专有模型前茅,并在若干多模态任务上达到业界领先水平。具体排名因任务与数据集而异;请在你的数据上进行测试。
Q5: Will I need to transcribe audio to use Gemini Embedding 2?
A: 不需要——Gemini Embedding 2 可直接接受音频并生成嵌入,无需先转写为文本,从而支持端到端的音频语义检索。
Q6: How do I lower storage costs for 3,072-dim vectors?
A: 方案包括请求更低的 output_dimensionality,使用 float16/量化/PQ,以及在你的向量数据库中存储压缩表示。厂商文章提供了相关流程与最佳实践。
What comes next — should I adopt it now?
Gemini Embedding 2 在统一多模态检索方面迈出了重要一步,并简化了此前必须为文本、视觉与语音分别维护检索器的架构。是否采用的关键考量:
- 尽快采用:如果你的产品需要稳健的跨模态检索(文本↔图像/视频/音频),或者维护多套单模态检索器的成本与复杂度较高。
- 立即试点:如果你希望评估 MRL 截断,并衡量成本与质量(保持混合部署:1536 为主用,3072 用于重排序)。
- 暂缓:如果你的工作负载对成本极度敏感且仅需文本检索——顶级的纯文本模型(例如 OpenAI text-embedding-3-large)仍具竞争力,且在某些管线和合同下可能更便宜。
开发者现在即可通过 CometAPI 访问 Gemini Embedding 2 和 OpenAI text-embedding-3 API。开始使用前,可先在 Playground 探索模型能力,并查阅 API guide 获取详细说明。访问前,请确保已登录 CometAPI 并获取 API 密钥。CometAPI 提供远低于官方的价格,助你更快集成。
Ready to Go?→ Sign up for cometapi today !