
.webp&w=3840&q=75)
GLM-5.1 标志着 AI 版图的一次关键转变。随着中国 AI 公司在开源前沿能力的同时加速商业化,这一模型在实际软件工程上尤其缩小了与 OpenAI 的 GPT-5.4、Anthropic 的 Claude Opus 4.6、以及 Google 的 Gemini 3.1 Pro 等闭源领军者之间的差距。它基于与 GLM-5 相同的 744B 参数 MoE 架构训练,但针对智能体工作流进行了大幅优化,恰恰擅长大多数 LLM 易失手的场景:需要规划、试验、调试与自我纠错的长时、含糊且迭代性强的任务,并能在成千上万次工具调用中保持表现。
现在,CometAPI 已集成 GLM-5.1 与 GLM-5,开发者也可以看到其他西方头部模型并以极低的 API 价格获取(这也是 CometAPI 相较其他竞争者的优势之一)。
什么是 GLM-5.1?
GLM-5.1 是 Z.ai 最新的旗舰语言模型,也是其在长周期、智能体式软件工作上的最新推进。用 Z.ai 自身的话说,它面向需要持续执行而非一次性回答的任务,被定位为能在单次长流程中进行规划、执行、打磨与交付的模型。Z.ai 的发布说明称,GLM-5.1 采用了多轮监督微调、强化学习与过程质量评估框架,并在长程任务中提升了稳定性、一致性与工具使用能力。
这一定位很重要,因为 GLM-5.1 并非以“又一个聊天模型”售卖。它面向工程化工作流——模型需要牢牢记住目标、处理中间步骤,并能在不丢失主线的情况下从错误中恢复,被定位为用于自主规划、持续执行、修复缺陷与策略迭代的模型,这与休闲助手或短上下文编码副驾截然不同。
一个实用细节:GLM-5.1 仅支持文本,包含在 GLM Coding Plan 中,并可用于 Claude Code、OpenClaw 等流行的编码智能体,这使其尤其适合那些希望将模型嵌入既有开发者工作流而非替代它的团队。
核心技术规格(在 GLM-5 基础上继承并强化):
- 架构:Mixture-of-Experts(MoE),总参数 744B,每次推理约 40B 激活参数
- 上下文窗口:203K–204.8K token(支持最高 131K 输出 token)
- 关键增强:用于高效长上下文处理并降低部署成本的 DeepSeek Sparse Attention(DSA);基于 Z.ai “slime” 框架的先进异步强化学习基础设施,以提升后训练效果
- 可用性:开放权重(MIT 许可证,Hugging Face:zai-org/GLM-5.1),可通过 Z.ai 平台与 CometAPI 等聚合器 API 访问,并集成至 GLM Coding Plan 工具(兼容 Claude Code / OpenClaw)
不同于早期更聚焦通用智能或短期“vibe coding”的 GLM 系列,GLM-5.1 瞄准的是面向生产的自主智能体。它可以在无人干预下数小时独立规划、执行、基准评测、调试与迭代复杂工程项目——使其成为 Anthropic 与 OpenAI 专业编码智能体的直接竞争者。
此次发布伴随约 10% 的 API 价格上调(输入 token 约 $0.54/M、输出约 $4.40/M),但相较 Anthropic 的 Opus 4.6(贵约 250–470%)仍大幅便宜。
GLM-5.1 基准表现
Z.ai 将 GLM-5.1 定位为全球最强的开源模型以及智能体式编码的全球前三。性能数据来自官方在 SWE-Bench Pro、NL2Repo、Terminal-Bench 2.0 以及定制长周期场景上的评测。
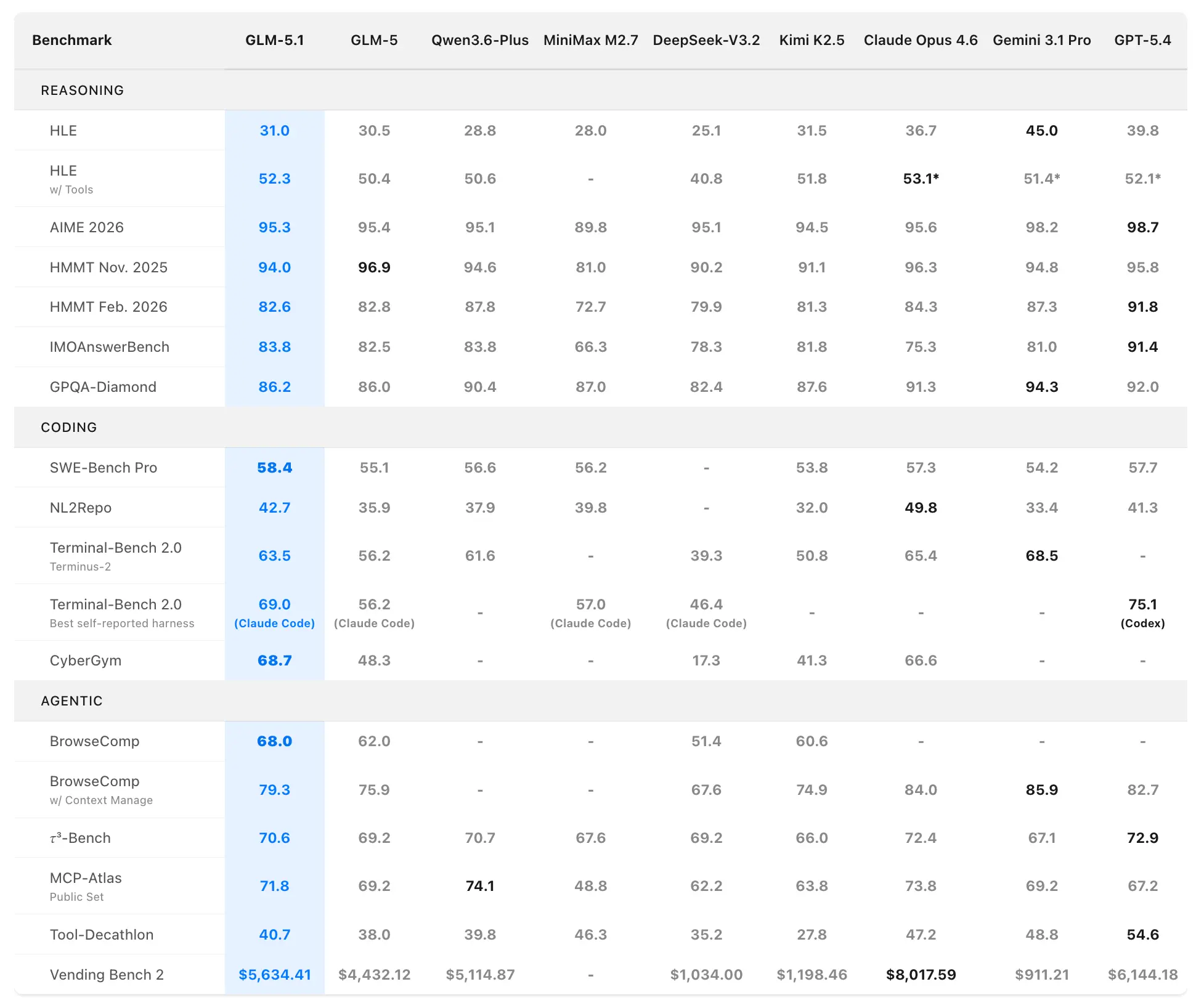
编码与智能体基准
SWE-Bench Pro(真实世界软件工程任务,要求仓库导航、代码编辑与功能验证):
- GLM-5.1:58.4(新的 SOTA)
- GLM-5:55.1
- GPT-5.4:57.7
- Claude Opus 4.6:57.3
- Gemini 3.1 Pro:54.2
GLM-5.1 成为首个在这一严格基准上夺冠的中国本土与开源模型,该基准与专业开发者工作流高度贴合。
NL2Repo(自然语言到完整仓库生成):
- GLM-5.1:42.7(大幅领先 GLM-5 的 35.9)
- 竞争模型范围 32.0–49.8(具体领先者随评测套件而异)
Terminal-Bench 2.0(真实世界终端与系统任务):
- Terminus-2 套件:GLM-5.1 63.5(vs. GLM-5 56.2)
- 自报最佳(Claude Code):最高 69.0
在另一套编码评测(Claude Code 风格)中,GLM-5.1 得分 45.3——达到 Claude Opus 4.6 的 47.9 的 94.6%,并较 GLM-5 的 35.4 提升 28%。
综合排名:开源第 1、中国模型第 1、SWE-Bench Pro + NL2Repo + Terminal-Bench 全球第 3。
长周期任务表现:真正的差异化
标准基准衡量的是一次性或短会话表现。GLM-5.1 在长时间自主运行中表现突出:
- VectorDBBench 优化(600+ 次迭代,6,000+ 次工具调用):从 Rust 骨架出发,GLM-5.1 迭代式重构索引、压缩、路由与剪枝,实现 21.5k QPS(是 Claude Opus 4.6 在 50 轮内最佳 3,547 QPS 的 6×),同时在 SIFT-1M 上保持 ≥95% 召回。其表现呈现“阶梯式”提升,每 100–200 次迭代出现结构性突破。
- KernelBench Level 3(完整 ML 模型优化,1,000+ 轮):在 50 个复杂问题上的几何平均加速比 3.6×(优于 torch.compile 最大自动调优的 1.49×)。GLM-5.1 在 GLM-5 进入平台期后仍持续提升;仅有 Claude Opus 4.6 以 4.2× 略胜。
- Linux 桌面 Web 应用构建(8+ 小时,开放式):仅给出自然语言提示、无起始代码,GLM-5.1 自主构建了一个可用的类 Linux 桌面环境——包含任务栏、窗口、交互与细节打磨——而先前模型只产出基础骨架。
这些结果表明,GLM-5.1 能在极长周期中保持连贯、自我评估、修订策略并跳出局部最优——这正是 Z.ai 为真实世界智能体系统明确打造的能力。
GLM-5.1 与 GLM-5 有何不同?
GLM-5 与 GLM-5.1 关系密切,但定位并不相同。GLM-5 是 Z.AI 面向**智能体工程(Agentic Engineering)**的早期基础模型。它为复杂系统工程与长程智能体任务而设计,具备开源权重下的 SOTA 编码与智能体能力,在真实编程情境中的编码表现接近 Claude Opus 4.5。其在 SWE-bench Verified 上得分 77.8,在 Terminal Bench 2.0 上得分 56.2。
相比之下,GLM-5.1 被定位为迈向长周期任务与更可靠的持续执行的下一步,在长程任务中进一步提升了稳定性、一致性与工具使用能力,并且整体对齐到更接近 Claude Opus 4.6。换言之,GLM-5 是更偏工程基础的早期版本,GLM-5.1 则是更强调任务耐力的旗舰。
GLM-5 代际中的架构与训练差异也有助于解释跃迁。GLM-5 从355B 参数(32B 激活)扩展到744B 参数(40B 激活),预训练数据从23T 增至28.5T,新增异步强化学习框架,并集成DeepSeek Sparse Attention,在提升效率的同时保持长文本质量。这些细节属于 GLM-5 的基础,而 GLM-5.1 显然在此之上继续构建。
GLM-5.1 与其他前沿模型对比
GLM-5.1 以最强开源竞争者的姿态脱颖而出,并具有令人信服的性价比。
对比表:主要编码与智能体基准(2026 年 4 月)
| Model | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding Harness Score | Long-Horizon Sustained? | Open-Source? | Approx. API Price (Input/Output per M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% of Opus) | Yes (600+ iter, 8 hrs) | Yes | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Limited | Yes | Lower (pre-hike) |
| GPT-5.4 | 57.7 | — | — | — | Strong | No | Higher |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Strongest | No | ~250–470% more expensive |
| Gemini 3.1 Pro | 54.2 | — | — | — | Good | No | Higher |
结论:GLM-5.1 在开源可及性、成本与特定长周期编码指标上占优。在智能体场景中与闭源领军者短兵相接的同时,进一步普惠了前沿能力。
GLM-5.1 的应用场景
1) 自主化软件工程
当任务接近真实工程冲刺时,GLM-5.1 最具吸引力:阅读代码库、规划变更、实现、测试、修复回归,并持续迭代直到结果稳定。Z.ai 的发布说明明确强调自主规划、持续执行、修复缺陷与策略迭代,使该模型仿佛为编码智能体与软件交付流水线量身打造。
2) 长时间运行的智能体工作流
如果你的用例涉及大量工具调用、长多步工作流或反复自我纠错,GLM-5.1 的设计高度契合。文档强调了工具调用、结构化输出、MCP 集成与工具流式支持——这些在模型不仅需回答,更要在更大系统内操作时尤为关键。
3) 企业知识工作与报告
GLM-5.1 也面向办公生产力任务,如 PowerPoint、Word、PDF 与 Excel 工作流。Z.ai 称其在复杂内容组织、版式设计、结构化输出与视觉打磨上有所提升,适用于报告生成、教学材料、研究综述等文档密集工作。
4) 前端原型与制品
Z.ai 表示 GLM-5.1 擅长网站生成、交互页面与前端原型,模板化更少、任务完成质量更高。这对需要从简短说明快速到可用原型的产品团队尤为合适,而不仅仅是做得“好看”。
5) 复杂对话与指令跟随
尽管主打编码,GLM-5.1 在开放式问答、复杂指令与多轮交互上也更强。这使其适合需要跟踪约束、反复修订输出并在长对话中保持上下文的助手式工作流。
结论:为什么 GLM-5.1 在 2026 年重要
GLM-5.1 并非一次小步迭代——它预示着真正有能力的开源智能体式 AI 的到来。它在最难的真实工程基准上表现卓越,同时保持低成本与开源开放,Z.ai 为整个行业抬升了门槛。无论你是独立开发者、企业团队还是研究者,GLM-5.1 都以专有模型一小部分的成本提供了面向长周期编码任务的无与伦比的自主性。
准备好试试了吗? 立即通过 CometAPI 的 GLM-5.1 模型、Hugging Face 仓库或 GLM Coding Plan 获取访问。