

GPT-5.2 是 OpenAI 于 2025 年 12 月发布的 GPT-5 系列小版本更新:一款面向文本、视觉与工具的旗舰多模态模型家族,专为专业知识工作、长上下文推理、具备代理性的工具使用与软件工程而调优。OpenAI 将 GPT-5.2 定位为迄今最强的 GPT-5 系列模型,强调其在可靠的多步推理、处理超大文档以及安全性/政策合规方面的改进;本次发布包含三个面向用户的变体——Instant、Thinking 与 Pro——并首先向付费 ChatGPT 订阅者与 API 客户逐步推出。
什么是 GPT-5.2,为什么重要?
GPT-5.2 是 OpenAI GPT-5 家族的最新成员——一个面向“前沿”能力的新模型系列,旨在缩小单轮对话助理与需要跨长文档推理、调用工具、理解图像并可靠执行多步工作流的系统之间的差距。OpenAI 将 5.2 定位为其在专业知识工作方面迄今最强的版本:在内部基准(尤其是面向知识工作的新基准 GDPval)上取得新的最先进成绩,在软件工程基准上展现更强的编码表现,并显著提升长上下文与视觉能力。
在实际使用中,GPT-5.2 不只是“更大的聊天模型”。它由三个调优变体(Instant、Thinking、Pro)构成,在时延、推理深度与成本上进行权衡——结合 OpenAI 的 API 与 ChatGPT 路由,可用于运行长时间研究任务、构建会调用外部工具的代理、解读复杂图像与图表,并以比早期版本更高保真度生成生产级代码。该模型支持超大上下文窗口(OpenAI 文档列出旗舰模型的 400,000 token 上下文窗口与 128,000 最大输出限制)、在 API 中提供明确的推理投入级别,以及具备“代理性”的工具调用行为。
GPT-5.2 的 5 项核心能力升级
1) GPT-5.2 是否更擅长多步逻辑与数学?
GPT-5.2 带来更锋利的多步推理,并在数学与结构化问题求解上有着明显提升。OpenAI 表示他们增加了对推理投入的更细粒度控制(新增如 xhigh 的级别),加入了“reasoning token”支持,并调优模型以在更长的内部推理轨迹中保持 chain-of-thought。诸如 FrontierMath 与 ARC-AGI 风格测试的基准显示相较 GPT-5.1 有实质性增益;在科学与金融工作流使用的领域专用基准上优势更大。简言之:在你的要求下,GPT-5.2 会“想得更久”,并能更一致地完成更复杂的符号/数学工作。

| RC-AGI-1(已验证) 抽象推理 | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2(已验证) 抽象推理 | 52.9% | 17.6% |
GPT-5.2 Thinking 在多个高级科学与数学推理测试中创下纪录:
- GPQA Diamond 科学测验:92.4%(Pro 版本 93.2%)
- ARC-AGI-1 抽象推理:86.2%(首个突破 90% 阈值的模型)
- ARC-AGI-2 高阶推理:52.9%,为 Thinking Chain 模型创造新纪录
- FrontierMath 高等数学测试:40.3%,远超其前代;
- HMMT 数学竞赛题:99.4%
- AIME 数学测试:100% 完整解答
此外,GPT-5.2 Pro(High)在 ARC-AGI-2 上达到最先进水平,以每个任务 $15.72 的成本取得 54.2% 的成绩!超越所有其他模型。
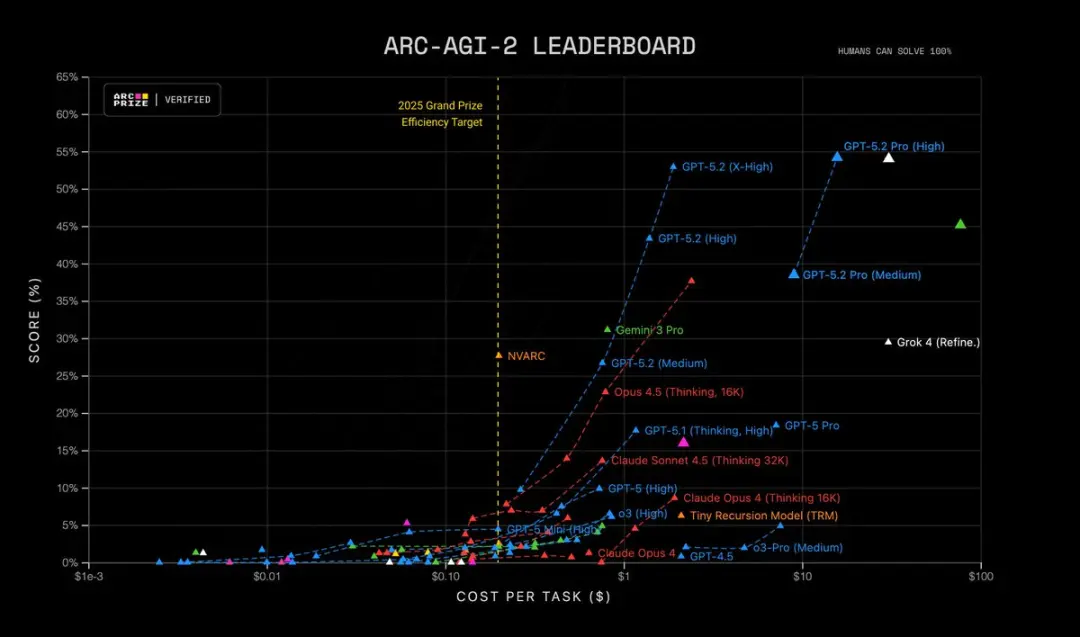
重要性:许多真实世界任务——如财务建模、实验设计、需要形式化推理的程序综合——受制于模型能否将多个正确步骤串联起来。GPT-5.2 减少了“幻觉式步骤”,在你要求其展示解题过程时,能产出更稳定的中间推理轨迹。
2) 长文本理解与跨文档推理有何改进?
长上下文理解是本次的看点之一。GPT-5.2 的底层模型支持 400k token 上下文窗口,并且——更重要的是——当相关内容位于上下文深处时仍能保持更高准确度。在跨越 44 个职业、面向“明确规格化知识工作”的任务套件 GDPval 中,GPT-5.2 Thinking 在大量任务上达到或优于人类专家评审水平。独立报道确认,该模型在跨多文档的信息保持与综合方面远优于以往模型。这对尽调、法律总结、文献综述与代码库理解等任务而言是一次切实可用的进步。
GPT-5.2 可处理多达 256,000 token 的上下文(约 200+ 页文档)。此外,在 “OpenAI MRCRv2” 长文本理解测试中,GPT-5.2 Thinking 的准确率接近 100%。
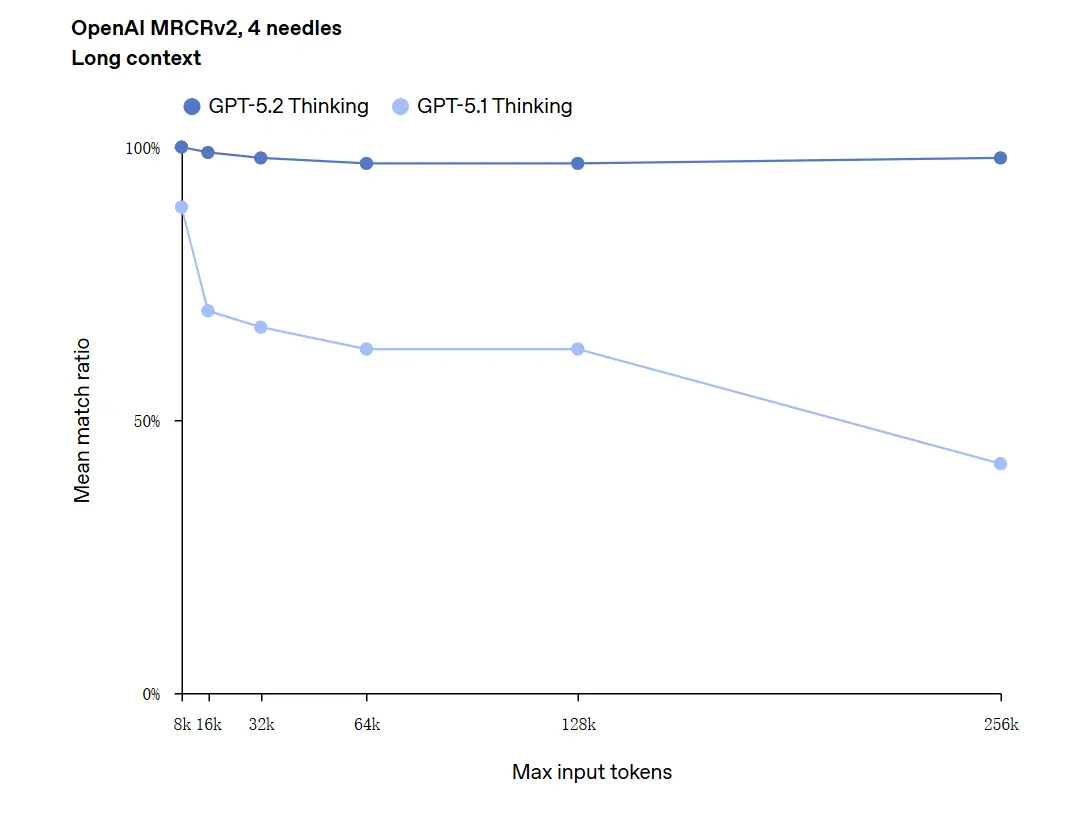
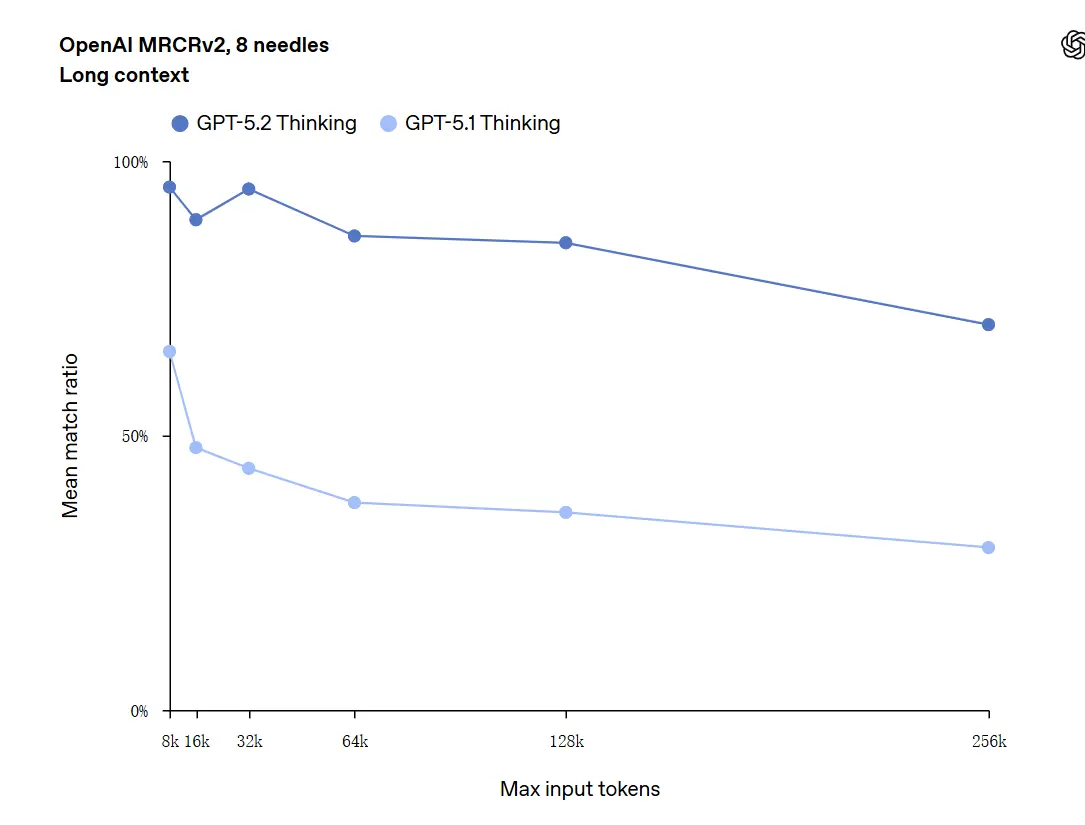
关于“100% 准确率”的注意事项:应将其描述为在狭窄的微任务上“接近 100%”;OpenAI 的数据更适合表述为“在被评估任务上达到最先进水平,且在诸多情况下达到或超过人类专家水平”,而非在所有使用场景上毫无瑕疵。基准显示大幅提升,但并非普遍完美。
3) 视觉理解与多模态推理有哪些新进展?
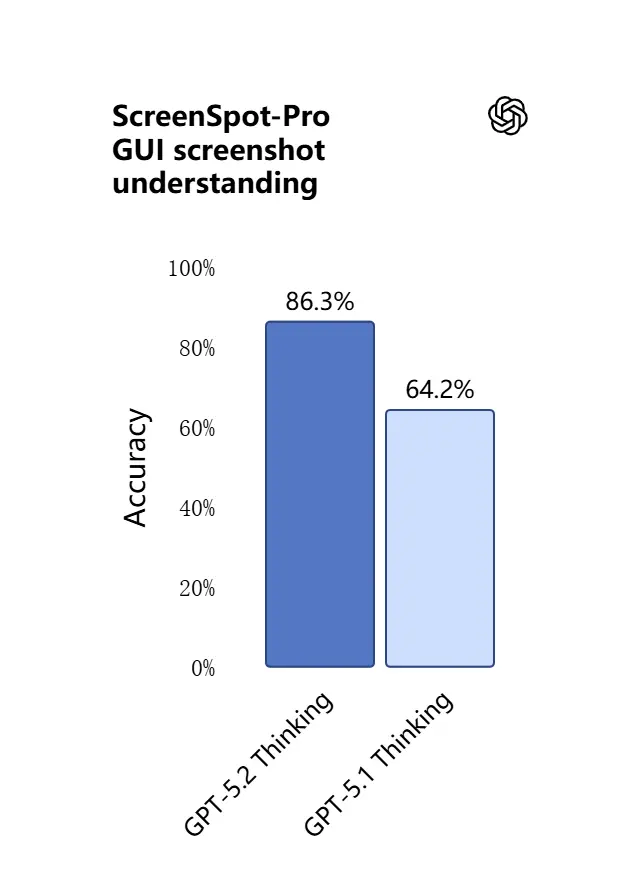
GPT-5.2 的视觉能力更锐利且更实用。模型更擅长解读截图、读取图表与表格、识别 UI 元素,并将视觉输入与长文本上下文结合。这并非只是图像描述:GPT-5.2 能从图像中抽取结构化数据(例如从 PDF 表格中提取数据)、解释图形,并以支持后续工具动作的方式对图解进行推理(例如从拍摄的报告生成电子表格)。
.webp)
实际效果:团队可以直接将完整的幻灯片、扫描的研究报告或图像密集型文档输入模型,并请求跨文档综合——大幅减少手动抽取工作量。
4) 工具调用与任务执行有何变化?
GPT-5.2 进一步推进了具备代理性的行为:更善于规划多步任务、判定何时调用外部工具,并执行一系列 API/工具调用以端到端完成工作。“具备代理性的工具调用”得到改进——模型会提出计划、调用工具(数据库、计算、文件系统、浏览器、代码运行器),并比以往版本更可靠地将结果综合为最终交付物。API 引入了路由与安全控制(允许工具列表、工具脚手架),而 ChatGPT 的界面可以将请求自动路由到合适的 5.2 变体(Instant vs Thinking)。
GPT-5.2 在 Tau2-Bench Telecom 基准中取得 98.7% 的成绩,展示了其在复杂多轮任务中的成熟工具调用能力。
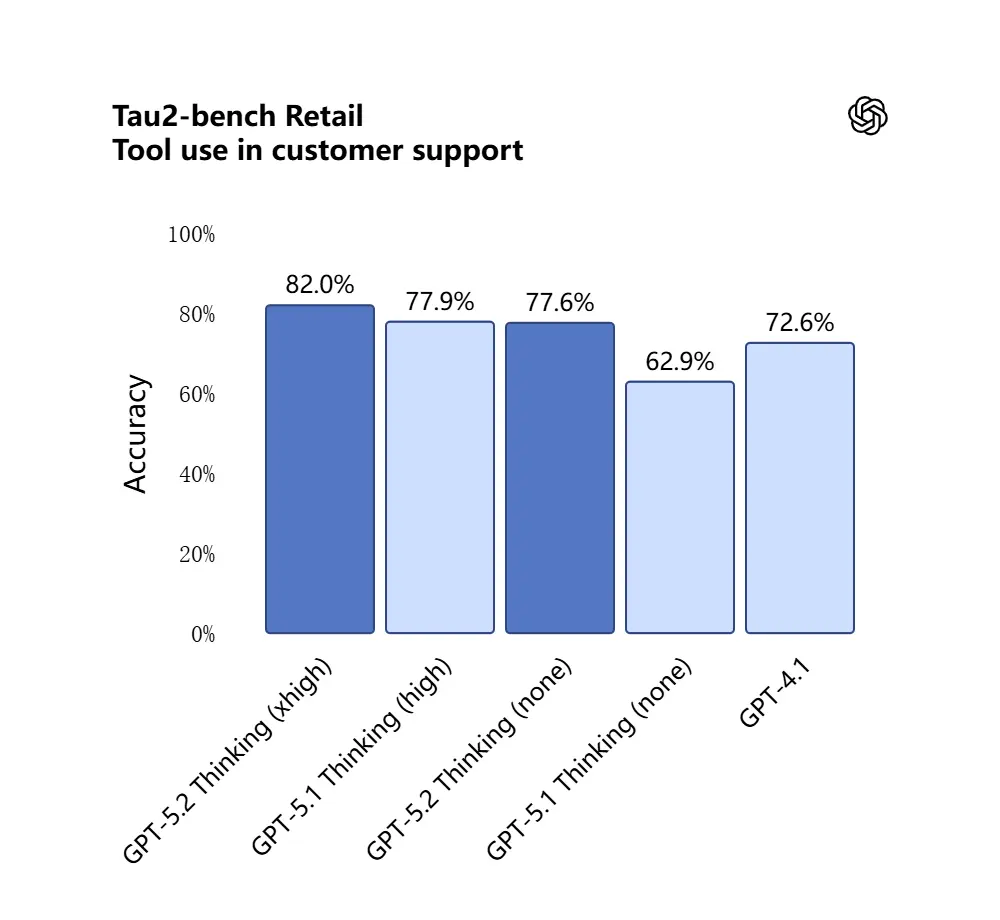
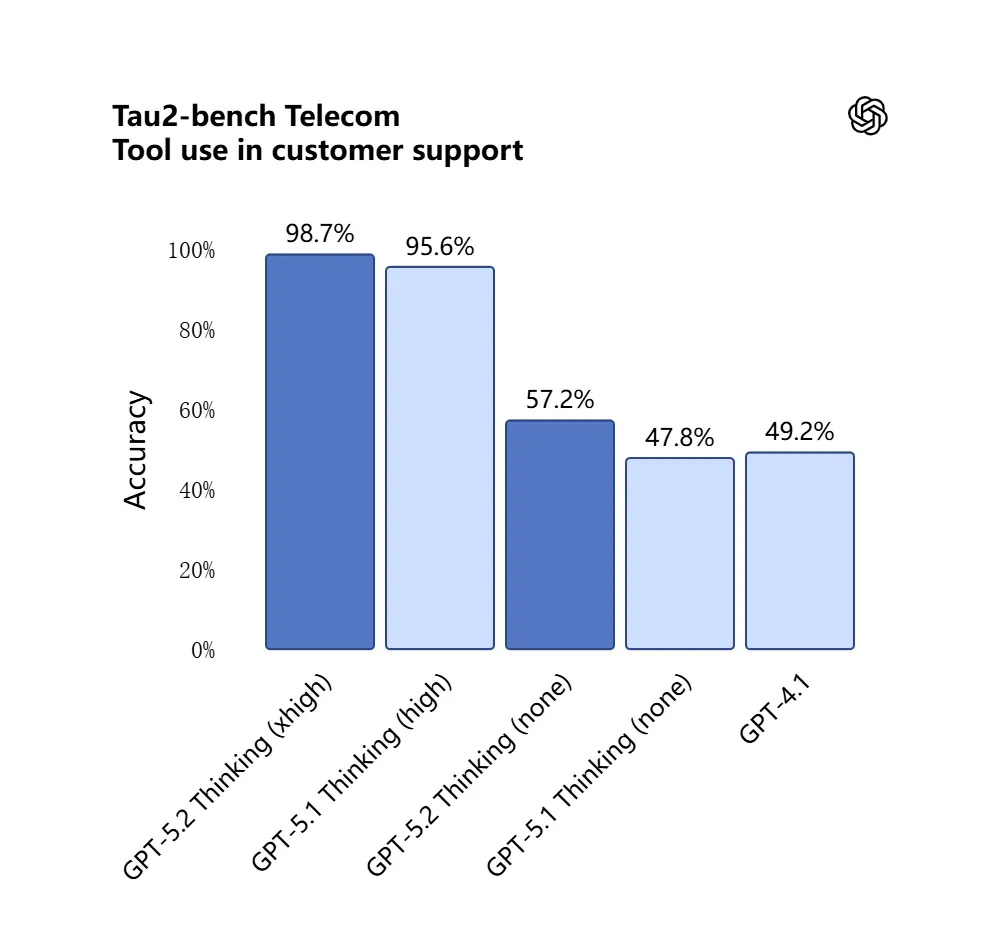
重要性:这使得 GPT-5.2 更适合作为面向诸如“导入这些合同、提取条款、更新电子表格并撰写总结邮件”等工作流的自主助理——过去这些任务需要精细的编排。
5) 编程能力演进
GPT-5.2 在软件工程任务上有显著提升:能编写更完整的模块,更可靠地生成与运行测试,更好理解复杂的项目依赖图谱,并且不再容易出现“懒惰编码”(跳过样板或未正确连接模块)。在行业级编码基准(SWE-bench Pro 等)上,GPT-5.2 创下新纪录。对将 LLM 用作结对程序员的团队而言,这一提升可以减少生成后所需的人工验证与返工。
在 SWE-Bench Pro 测试(真实世界工业级软件工程任务)中,GPT-5.2 Thinking 的分数提升至 55.6%,同时在 SWE-Bench Verified 测试中也取得了 80% 的新高。
_Software%20engineering.webp)
在实际应用中,这意味着:
- 生产环境代码自动调试带来更高稳定性;
- 支持多语言编程(不限于 Python);
- 能够独立完成端到端的修复任务。
GPT-5.2 与 GPT-5.1 有何不同?
简短回答:GPT-5.2 是一次迭代但实质的改进。它延续了 GPT-5 家族的架构与多模态基础,但在四个实用维度上前进:
- 推理的深度与一致性。 5.2 引入更高的推理投入级别,并在多步问题的链式推理上表现更佳;5.1 曾在早些时候提升了推理能力,但 5.2 将复杂数学与多阶段逻辑的上限抬得更高。
- 长上下文可靠性。 两个版本都扩展了上下文,但 5.2 被调优为在非常长的输入中保持准确度(OpenAI 声称在数十万 token 范围内的保留能力有所改进)。
- 视觉 + 多模态保真度。 5.2 提升了图像与文本之间的交叉引用——例如读取图表并将数据整合进电子表格——呈现更高的任务级准确性。
- 具备代理性的工具行为与 API 特性。 5.2 在 API 中暴露新的推理投入参数(
xhigh)与上下文压缩特性,OpenAI 也优化了 ChatGPT 中的路由逻辑,使 UI 能自动选择最佳变体。 - 更少错误、更高稳定性:GPT-5.2 将其“幻觉率”(错误响应率)降低了 38%。在研究、写作与分析类问题上回答更可靠,减少“捏造事实”的情况。复杂任务中,其结构化输出更清晰、逻辑更稳定。同时,模型在心理健康相关任务上的响应安全性显著提升。在心理健康、自我伤害、自杀与情感依赖等敏感场景中表现更稳健。
在系统评估中,GPT-5.2 Instant 在“心理健康支持”任务上获得 0.995(满分 1.0),显著高于 GPT-5.1(0.883)。
量化来看,OpenAI 发布的基准显示在 GDPval、数学基准(FrontierMath)与软件工程评测上实现了可衡量的增益。GPT-5.2 在初级投行业务的电子表格任务上较 GPT-5.1 提升了数个百分点。
GPT-5.2 是否免费——费用如何?
我可以免费使用 GPT-5.2 吗?
OpenAI 从付费 ChatGPT 计划与 API 接入开始推出 GPT-5.2。历史上 OpenAI 通常将最快/最强的模型置于付费层,并在后续更广泛开放较轻量的变体;在 5.2 中,公司表示将从付费计划(Plus、Pro、Business、Enterprise)开始推出,并向开发者开放 API。这意味着即时的免费访问受限:随着 OpenAI 扩大推出范围,免费层可能稍后获得降级或路由访问(例如到较轻的子变体)。
好消息是,CometAPI 现已集成 GPT-5.2,且当前有圣诞促销。你现在可以通过 CometAPI 使用 GPT-5.2;其 playground 允许你自由与 GPT-5.2 交互,开发者也可使用 GPT-5.2 API(CometAPI 的定价为 OpenAI 的 20%)来构建工作流。
通过 API(开发/生产用)需要多少费用?
API 使用按 token 计费。OpenAI 在发布时公布的平台定价显示(CometAPI 的定价为 OpenAI 的 20%):
- GPT-5.2(标准聊天) — 每 1M 输入 token $1.75,每 1M 输出 token $14(支持缓存输入折扣)。
- GPT-5.2 Pro(旗舰) — 每 1M 输入 token $21,每 1M 输出 token $168(因面向高精度、计算密集的工作负载,价格显著更高)。
- 对比之下,GPT-5.1 更便宜(例如每 1M token 输入 $1.25 / 输出 $10)。
解读: 相较前代,API 成本有所上升;价格信号表明 5.2 的高端推理与长上下文性能作为独立产品层定价。对于生产系统,费用主要取决于输入/输出 token 的数量以及缓存输入的复用频次(缓存输入可享受大幅折扣)。
实际意味着什么
- 对于通过 ChatGPT UI 的日常使用,按月订阅计划(Plus、Pro、Business、Enterprise)是主要路径。随着 5.2 发布,ChatGPT 订阅层的定价未改变(OpenAI 通常保持计划价格稳定,即便模型提供有所调整)。
- 对于生产与开发者使用,需要为 token 成本做预算。如果你的应用会流式输出大量长回复或处理长文档,输出 token 的价格(Thinking 为 $14 / 1M tokens)将成为主要成本,除非你谨慎地缓存输入并复用输出。
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAI 随 GPT-5.2 推出了三个面向用途分层的变体,以匹配不同用例:Instant、Thinking 与 Pro:
- GPT-5.2 Instant: 快速、性价比高,面向日常工作——FAQ、操作指南、翻译、快速撰稿。延迟更低;适合初稿与简单工作流。
- GPT-5.2 Thinking: 面向持续工作的更深入高质量响应——长文档总结、多步规划、详细代码审查。延迟与质量平衡;专业任务的默认“主力”。
- GPT-5.2 Pro: 最高质量与可信度。更慢且更昂贵;适合困难、高风险任务(复杂工程、法律综合、高价值决策)以及需要“xhigh”推理投入的场景。
对比表
| 功能 / 指标 | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| 预期用途 | 日常任务、快速撰稿 | 深度分析、长文档 | 最高质量、复杂问题 |
| 延迟 | 最低 | 适中 | 最高 |
| 推理投入 | 标准 | 高 | 支持 xHigh |
| 最佳适用 | FAQ、教程、翻译、短提示 | 摘要、规划、电子表格、编码任务 | 复杂工程、法律综合、研究 |
| API 名称示例 | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| 输入 token 价格(API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| 输出 token 价格(API) | $14 / 1M | $14 / 1M | $168 / 1M |
| 可用性(ChatGPT) | 分阶段推出;先付费计划后更广泛 | 分阶段向付费计划推出 | Pro 用户 / Enterprise(付费) |
| 典型用例示例 | 撰写邮件、少量代码片段 | 构建多表财务模型、长报告问答 | 审核代码库、生成生产级系统设计 |
谁适合使用 GPT-5.2?
GPT-5.2 的目标用户十分广泛。以下是基于角色的建议:
企业与产品团队
如果你在构建知识工作产品(研究助理、合同审阅、分析流水线或开发者工具),GPT-5.2 的长上下文与代理性能力可显著降低集成复杂度。需要强健文档理解、自动化报告或智能助手的企业会发现 Thinking/Pro 更为实用。Microsoft 与其他平台伙伴已将 5.2 集成进生产力套件(例如 Microsoft 365 Copilot)。
开发者与工程团队
希望将 LLM 用作结对程序员或自动化代码生成/测试的团队将受益于 5.2 在编程保真度上的提升。通过 API(使用 thinking 或 pro 模式),借助 400k token 上下文窗口,可对大型代码库进行更深入的综合。使用 Pro 的 API 成本更高,但在复杂系统中减少的人工作业与调试可能抵消该成本。
研究人员与数据密集型分析师
如果你经常综合文献、解析长技术报告,或希望在实验设计上获得模型辅助,GPT-5.2 的长上下文与数学能力改进可加速工作流。为保证可复现性,请结合谨慎的提示工程与验证步骤。
小型企业与进阶用户
ChatGPT Plus(以及面向进阶用户的 Pro)将获得到 5.2 变体的路由访问;这使得高级自动化与高质量输出为较小团队所及,即便不构建 API 集成。对需要更好文档摘要或幻灯片制作的非技术用户,GPT-5.2 提供明显的实用价值。
面向开发者与运维的实用说明
值得关注的 API 特性
reasoning.effort级别(例如medium、high、xhigh)允许你告知模型在内部推理上投入多少计算;使用它在单次请求层面权衡延迟与准确度。- 上下文压缩(Context compaction):API 提供工具压缩与精简历史,以保留真正相关的内容,这在需要保持有效 token 使用可控的长对话链中至关重要。
- 工具脚手架与 allowed-tools 控制:生产系统应显式白名单化模型可调用的工具,并记录工具调用以便审计。
成本控制技巧
- 缓存常用文档的向量表示,并对重复查询使用缓存输入(可获得大幅折扣)。OpenAI 的平台定价对缓存输入提供显著优惠。
- 将探索性/低价值查询路由至 Instant,将 Thinking/Pro 留给批处理作业或最终环节。
- 在评估 API 成本时,仔细估算 token 使用(输入 + 输出),因为长输出会成倍放大成本。
结论——是否应该升级到 GPT-5.2?
如果你的工作依赖长文档推理、跨文档综合、多模态理解(图像 + 文本),或构建会调用工具的代理,GPT-5.2 是一次明确的升级:它提升了实际准确度,减少了手动集成工作。如果你主要运行高吞吐、低延迟的聊天机器人或受严格预算约束的应用,Instant(或更早的模型)可能仍是合理选择。
GPT-5.2 代表着从“更好的聊天”向“更好的专业助理”的刻意转变:更多计算、更多能力与更高价层——但对于能够利用可靠长上下文、改进的数学/推理、图像理解与具备代理性的工具执行的团队而言,也带来实实在在的生产力提升。
开始体验,请在 Playground 中探索 GPT-5.2 模型(GPT-5.2;GPT-5.2 pro、GPT-5.2 chat)的能力,并查阅 API guide 获取详细说明。访问前,请确保已登录 CometAPI 并获取 API key。CometAPI 以远低于官方的价格助你集成。
Ready to Go?→ Free trial of gpt-5.2 models !