

Kimi K2 Thinking 是 Moonshot AI 的 Kimi K2 家族中的新“思考”变体:一个万亿参数的稀疏专家混合(MoE)模型,明确工程化为在行动中进行思考——即在可靠的工具调用、长程规划与自动自检之间交织深度思维链推理。它结合了大型稀疏骨干(≈1T 总参数,每个 token 激活 ~32B)、原生 INT4 量化管线,以及一种在推理时扩展推理(更多“思考 token”与更多工具调用轮次)而非仅仅增加静态参数数量的设计。
通俗而言:K2 Thinking 将模型视为一个解决问题的agent,而不是一次性的语言生成器。这种转变——从“语言模型”到“思考模型”——正是本次发布引人注目的原因,许多从业者也因此将其视为开源 agentic AI 的一个里程碑。
“Kimi K2 Thinking”究竟是什么?
架构与关键规格
K2 Thinking 构建为稀疏 MoE 模型(384 个专家,每个 token 选择 8 个专家),总参数约为1 万亿,每次推理~32B 激活参数。它采用混合式架构选择(MLA 注意力、SwiGLU 激活),在 Moonshot 的 Muon/MuonClip 优化器与其技术报告描述的大规模 token 预算上训练。“思考”变体在基础模型上扩展了训练后量化(原生 INT4 支持)、256k 上下文窗口,并通过工程实践在真实使用中暴露并稳定模型的内部推理轨迹。
“思考”在实践中的含义
“思考”是一种工程目标:使模型能够(1)生成长而结构化的内部推理链(思维链 token),(2)将外部工具(搜索、Python 沙盒、浏览器、数据库)作为推理的一部分进行调用,(3)评估并自我验证中间结论,(4)在大量此类循环中迭代且不丧失连贯性。Moonshot 的文档与模型卡展示了 K2 Thinking 明确训练与调优以交织推理与函数调用,并在数百个步骤中保持稳定的代理性行为。
核心目标是什么
传统大规模模型的局限:
- 生成过程短视,缺乏跨步骤逻辑;
- 工具使用受限(通常只能调用外部工具一两次);
- 在复杂问题中无法自我纠错。
K2 Thinking 的核心设计目标是解决上述三大问题。在实践中,K2 Thinking 可以在无人干预的情况下:执行 200–300 次连续工具调用;维持数百步逻辑连贯的推理;通过上下文自检解决复杂问题。
重新定位:语言模型 → 思考模型
K2 Thinking 项目体现了该领域更广泛的战略转变:从条件文本生成迈向代理式问题求解者。核心目标不再主要是提升困惑度或下一 token 预测,而是让模型能够:
- 规划自身的多步策略;
- 协同外部工具与执行器(搜索、代码执行、知识库);
- 验证中间结果并纠错;
- 维持在长上下文与长工具链中的连贯性。
这种重构同时改变了评估(基准更强调过程与结果,而非仅是文本质量)与工程(面向工具路由、步数计数、自我批判等结构)。
工作方法:思考模型如何运作
在实践中,K2 Thinking 展示了几种“思考模型”方法论的典型工作方式:
- 持久化内部轨迹: 模型生成结构化的中间步骤(推理轨迹),保留在上下文中并可复用或审计。
- 动态工具路由: 基于每个内部步骤,K2 决定调用哪种工具(搜索、代码解释器、网页浏览器)以及何时调用。
- 测试时扩展: 在推理过程中,系统可以扩展“思考深度”(更多内部推理 token),并增加工具调用次数以更好地探索解法。
- 自我验证与恢复: 模型明确检查结果、运行健全性测试,并在检查失败时重新规划。
这些方法将模型架构(MoE + 长上下文)与系统工程(工具编排、安全检查)结合起来。
是什么技术创新赋能了 Kimi K2 Thinking?
Kimi K2 Thinking 的推理机制支持交织的思考与工具使用。K2 Thinking 的推理循环:
- 理解问题(解析与抽象)
- 生成多步推理计划(计划链)
- 使用外部工具(代码、浏览器、数学引擎)
- 验证并修订结果(验证与修订)
- 完成推理(总结推理)
下面,我将介绍三项关键技术,使 xx 中的推理循环成为可能。
1) Test-time Scaling
是什么: 传统“Scaling Laws”关注在训练过程中增加参数或数据。K2 Thinking 的创新在于:在“推理阶段”动态扩展 token 数量(即思考深度);同时扩展工具调用次数(即行动广度)。这种方法称为 test-time scaling,其核心假设是:“更长的推理链 + 更多交互工具 = 实际智能的质的跃迁。”
为何重要: K2 Thinking 为此进行明确优化:Moonshot 展示了扩展“思考 token”及工具调用的数量/深度会在代理型基准上带来可测的提升,使模型在 FLOPs 匹配的场景中优于同等或更大规模的模型。
2) Tool-Augmented Reasoning
是什么: K2 Thinking 经过工程优化,能够原生解析工具 schema,自主决定何时调用工具,并将工具结果融入其持续的推理流。Moonshot 在训练与调优中交织思维链与函数调用,并将这种行为稳定到数百个连续工具步骤。
为何重要: 正是“可靠解析 + 稳定内部状态 + API 工具化”的组合,使得模型能将网页浏览、代码运行与多阶段工作流编排纳入单次会话中。
在其内部架构中,模型形成一条“可视化思考过程”的执行轨迹:提示词 → 推理 token → 工具调用 → 观察 → 下一步推理 → 最终答案
3) Long-horizon Coherence & Self-verification
是什么: 长视野连贯性是指模型在大量步骤与极长上下文中保持连贯计划与内部状态的能力。自我验证是指模型主动检查中间输出,并在验证失败时重跑或修订步骤。长任务常使模型漂移或幻觉。K2 Thinking 通过多种技术来应对:超长上下文窗口(256k)、在长思维链序列上保持状态的训练策略、以及显式的句级忠实度/判别模型以检测无支撑的陈述。
为何重要: “Recurrent Reasoning Memory” 机制维持推理状态的持续性,赋予其类人“思考稳定性”与“上下文自监督”特征。随着任务扩展到许多步骤(如研究项目、多文件编码任务、长周期编辑流程),维持单一连贯主线变得至关重要。自我验证减少静默失败;模型不再返回看似合理但错误的答案,而是能检测不一致并重新调用工具或重新规划。
能力:
- 上下文一致性:在 10k+ token 范围内维持语义连续性;
- 错误检测与回滚:在早期思考过程中识别并纠正逻辑偏差;
- 自我验证环:在推理完成后自动验证答案的合理性;
- 多路径推理合并:从多条逻辑链中选择最优路径。
K2 Thinking 的四项核心能力是什么?
深度且结构化的推理
K2 Thinking 经过调优以生成明确的、多阶段推理轨迹,并据此达成稳健结论。模型在数学与严谨推理基准(GSM8K、AIME、IMO 风格基准)上表现强劲,并展现出在长序列中保持完整推理的能力——这是研究级问题求解的基本要求。其在人类终极考试(Humanity’s Last Exam,44.9%)上的优异表现体现了专家级分析能力。它可以从模糊的语义描述中提取逻辑框架并生成推理图。
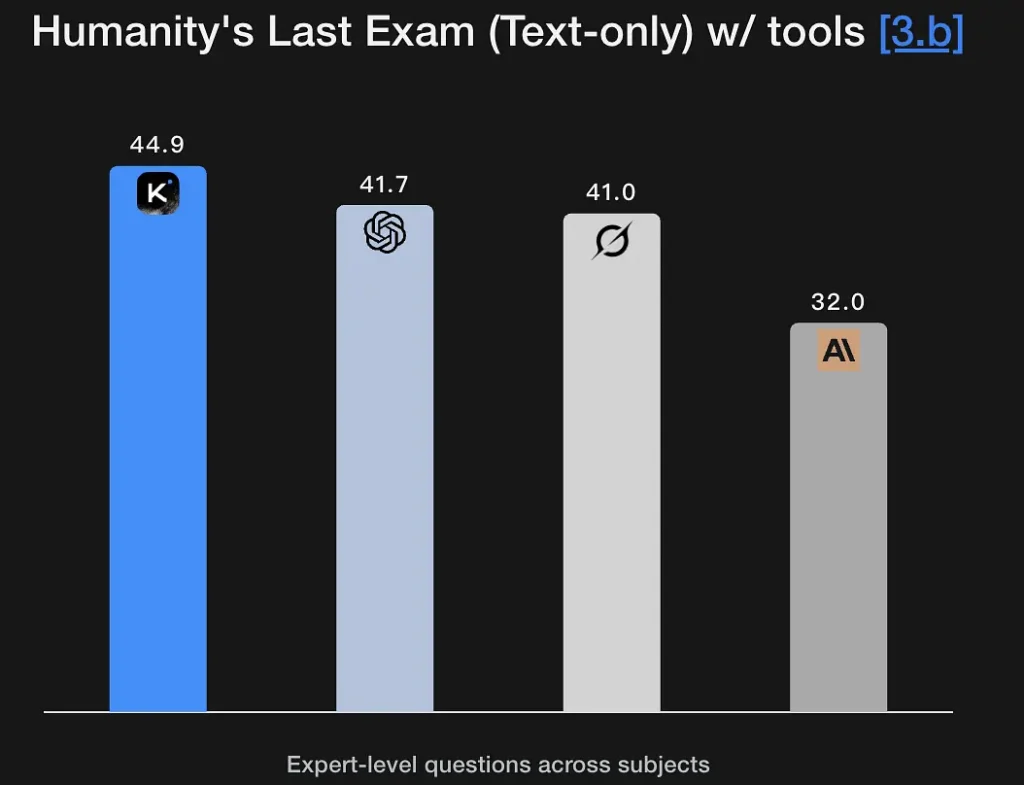
关键特性:
- 支持符号推理:理解并操作数学、逻辑与编程结构;
- 具备假设检验能力:可自发提出并验证假设;
- 能进行多阶段问题分解:将复杂目标拆解为多个子任务。
代理式搜索
不同于单次检索,代理式搜索使模型能够规划搜索策略(要找什么),通过重复的网页/工具调用执行、综合返回结果并细化查询。K2 Thinking 在 BrowseComp 与 Seal-0 的工具增强评分上表现出色;模型被明确设计为在多轮网页搜索中保持有状态规划。
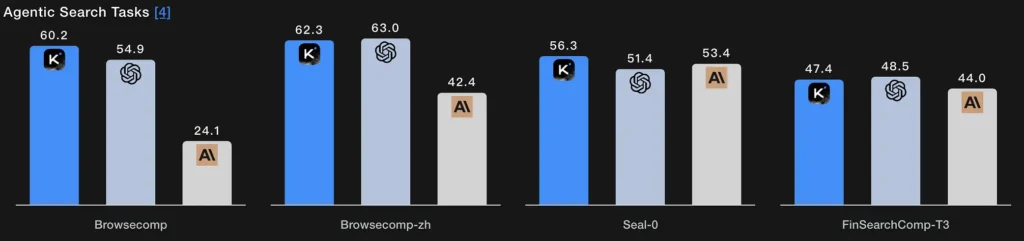
技术本质:
- 搜索模块与语言模型形成闭环:查询生成 → 网页检索 → 语义过滤 → 推理融合。
- 模型可自适应调整搜索策略,例如先查定义,再查数据,最后验证假设。
- 本质上,这是“信息检索 + 理解 + 论证”的复合智能。
代理式编程
这是在推理循环中编写、执行、测试并迭代代码的能力。K2 Thinking 在实时编码与代码验证基准上表现具有竞争力,在工具调用中支持 Python 工具链,并可通过调用沙盒、读取错误并在多次往返中修复代码来运行多步调试循环。其在 EvalPlus/LiveCodeBench 的成绩体现了这些优势。取得 SWE-Bench Verified 测试 71.3% 的分数意味着它能正确完成 70% 以上的真实世界软件修复任务。
它还在 LiveCodeBench V6 竞赛环境中展现出稳定表现,体现了其算法实现与优化能力。

技术本质:
- 采用“语义解析 + AST 级重构 + 自动验证”的流程;
- 通过执行层的工具调用实现代码运行与测试;
- 实现从理解代码 → 诊断错误 → 生成补丁 → 验证成功的闭环自动化开发。
代理式写作
区别于纯粹的创意散文,代理式写作是结构化、面向目标的文档生产,可能需要外部研究、引用、表格生成与迭代润色(例如生成草稿 → 事实核查 → 修订)。K2 Thinking 的长上下文与工具编排使其非常适合多阶段写作工作流(研究简报、法规摘要、多章节内容)。模型在 Arena 风格测试中的开放式胜率与长文写作指标支持这一结论。
技术本质:
- 通过代理式思考规划自动生成文本片段;
- 通过推理 token 在内部控制文本逻辑;
- 可同时调用搜索、计算与图表生成等工具,实现“多模态写作”。
今天你如何使用 K2 Thinking?
访问方式
K2 Thinking 通过开源发布(模型权重与检查点)以及平台端点与社区枢纽(Hugging Face、Moonshot 平台)提供。你可以在具备足够算力时自托管,或使用 CometAPI 的 API/托管界面以更快上手。其还文档化了一个 reasoning_content 字段,在启用时会向调用方暴露内部思考 token。
使用实用建议
- 从代理式积木开始:先暴露一小组可判定的工具(搜索、Python 沙盒以及可信的事实数据库)。提供清晰的工具 schema,让模型能够解析/校验调用。
- 调优测试时算力:在困难问题求解中,允许更长的思考预算与更多的工具调用轮次;衡量质量相对于延迟/成本的提升。Moonshot 倡导将 test-time scaling 作为首要杠杆。
- 使用 INT4 模式以提升成本效率:K2 Thinking 支持 INT4 量化,能带来有意义的加速;但请在你的任务上验证边界情况行为。
- 谨慎暴露推理内容:暴露内部思维链有助于调试,但也会增加接触原始模型错误的风险。将内部推理视为诊断性而非权威性;与自动化验证配对使用。
结论
Kimi K2 Thinking 是对下一时代 AI 的一次刻意工程化回应:不仅是更大的模型,而是能够思考、行动与验证的代理。它将 MoE 扩展、测试时算力策略、原生低精度推理与显式工具编排结合起来,实现持续的多步问题求解。对于需要多步问题解决并具备将代理式系统集成、沙盒化并监控的工程能力的团队而言,K2 Thinking 是一个重大且可用的进步——也是对业界与社会如何治理日益强大的行动型 AI 的重要压力测试。
开发者可通过 Kimi K2 Thinking API 访问 Kimi K2 Thinking,最新模型版本 始终与官网保持同步更新。入门可在 Playground 探索模型能力,并查阅 API 指南 获取详细说明。开始使用前,请确保已登录 CometAPI 并获取 API key。CometAPI 提供远低于官方价格的方案,帮助你完成集成。
准备好了吗?→ 立即注册 CometAPI!