

2025 年 6 月 17 日,总部位于上海的 AI 领军企业 MiniMax(也称 Xiyu Technology)正式发布 MiniMax‑M1(下称“M1”)——全球首个开放权重、规模化、混合注意力推理模型。M1 将专家混合(Mixture‑of‑Experts,MoE)架构与创新的 Lightning Attention 机制相结合,在面向生产力的任务上实现行业领先性能,与顶级闭源系统相媲美,同时保持出色的成本效益。本文将深入探讨 M1 是什么、如何运作、其核心特性,以及访问与使用该模型的实用指南。
什么是 MiniMax‑M1?
MiniMax‑M1 是 MiniMaxAI 针对可扩展、高效注意力机制研究的成果。基于 MiniMax‑Text‑01 基础,M1 迭代将 Lightning Attention 与 MoE 框架集成,在训练与推理阶段都实现前所未有的效率。该组合使模型在处理超长序列时仍能保持高性能——这对于涉及庞大代码库、法律文档或科学文献的任务至关重要。
核心架构与参数化
MiniMax‑M1 的核心采用混合式 MoE 系统,动态将令牌路由至部分专家子网络。尽管模型总参数为 456 billion,但每个令牌仅激活 45.9 billion,从而优化资源使用。该设计借鉴了早期 MoE 的实现,但在路由逻辑上进行了优化,以尽可能减少分布式推理时 GPU 之间的通信开销。
Lightning Attention 与长上下文支持
MiniMax‑M1 的标志性特性是 Lightning Attention 机制,可显著降低长序列自注意力的计算负担。通过结合局部与全局核对注意力矩阵进行近似,模型在处理 100K 令牌序列时,相较传统 Transformer 可将 FLOPs 降低最多 75%。这种效率不仅加速推理,还使处理高达一百万令牌的上下文窗口成为可能,而无需过于昂贵的硬件要求。
MiniMax‑M1 如何实现计算效率?
MiniMax‑M1 的效率提升源于两项主要创新:其混合专家(MoE)架构与训练中采用的全新 CISPO 强化学习算法。二者共同减少训练时间与推理成本,使快速实验与部署成为可能。
混合专家(MoE)路由
MoE 组件包含 32 个专家子网络,每个专家专长于不同的推理维度或领域任务。在推理过程中,学习到的门控机制会为每个令牌动态选择最相关的专家,仅激活处理输入所需的子网络。这种选择性激活大幅削减冗余计算并降低内存带宽需求,使 MiniMax‑M1 相比单体 Transformer 模型在成本效率上具备显著优势。
CISPO:一种全新的强化学习算法
为进一步提升训练效率,MiniMaxAI 开发了 CISPO(Clipped Importance Sampling with Partial Overrides),这是一种将基于重要性采样的裁剪替代令牌级权重更新的 RL 算法。CISPO 缓解了大规模 RL 设置中常见的权重爆炸问题,加速收敛,并在多样化基准上确保策略稳定改进。由此,MiniMax‑M1 在 512 块 H800 GPU 上完成完整 RL 训练仅需三周,成本约为 $534,700——仅为可比 GPT‑4 训练成本的一小部分。
MiniMax‑M1 的性能基准如何?
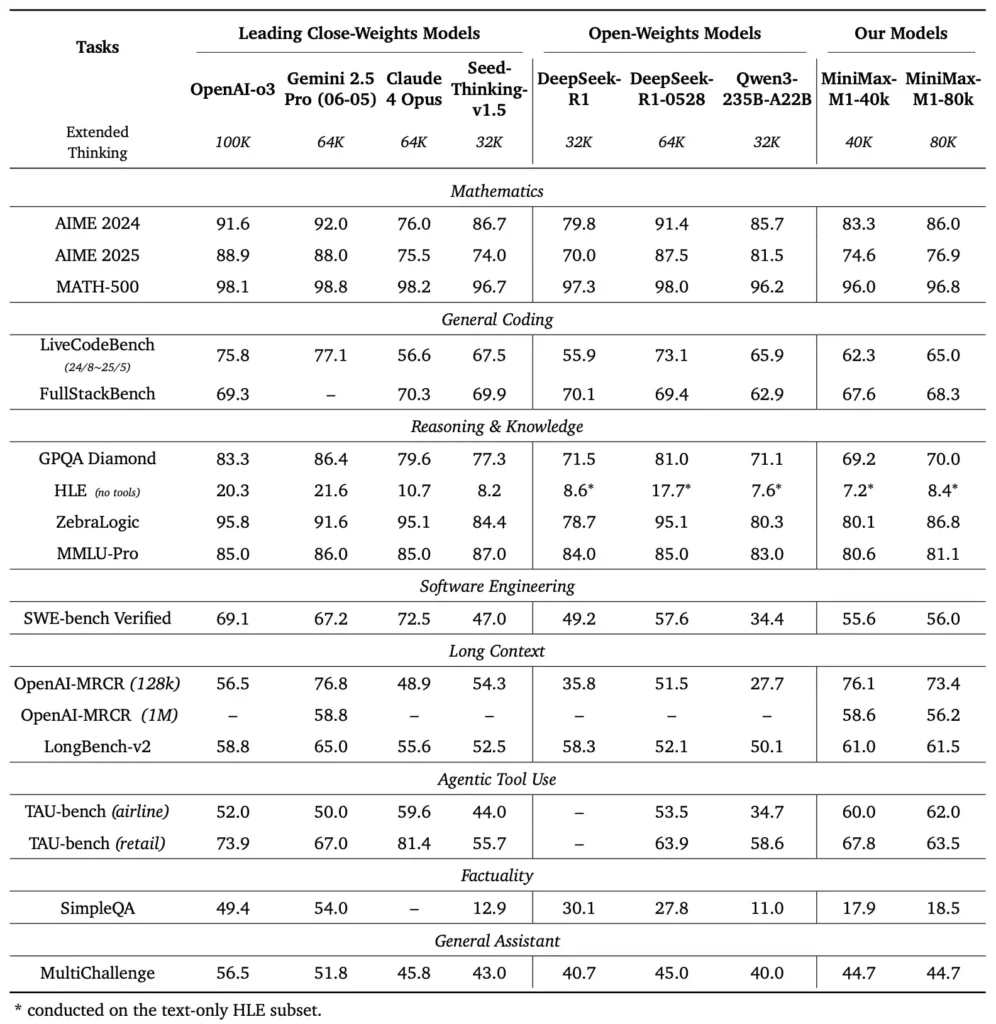
MiniMax‑M1 在多种标准与领域基准上表现优异,展现出处理长上下文推理、数学问题求解与代码生成的强大能力。
长上下文推理任务
在广泛的文档理解测试中,MiniMax‑M1 能处理高达 1,000,000 令牌的上下文窗口,在最大上下文长度上相较 DeepSeek‑R1 高出 8 倍,并在处理 100K 令牌序列时将计算需求减半。于 NarrativeQA 扩展上下文评估等基准中,模型取得了最先进的理解分数,得益于 Lightning Attention 对局部与全局依赖的高效捕获。
软件工程与工具使用
MiniMax‑M1 在大型 RL 的沙盒化软件工程环境中进行专项训练,能以极高准确率生成与调试代码。在 HumanEval 与 MBPP 等编码基准中,模型的通过率可与 Qwen3‑235B 与 DeepSeek‑R1 相当或更高,尤其是在多文件代码库和需要跨引用长代码片段的任务上。此外,MiniMaxAI 的早期演示展示了该模型与开发者工具的集成能力,从生成 CI/CD 流水线到自动文档化工作流。
开发者如何获取 MiniMax‑M1?
为促进广泛采用,MiniMaxAI 以开放权重形式免费提供 MiniMax‑M1。开发者可通过官方 GitHub 访问预训练检查点、模型权重与推理代码。
在 GitHub 上开放权重发布
MiniMaxAI 在 GitHub 上以宽松的开源许可发布了 MiniMax‑M1 的模型文件及配套脚本。感兴趣的用户可克隆 https://github.com/MiniMax-AI/MiniMax-M1 仓库,其中提供 40K 与 80K 令牌预算变体的检查点,以及与常见 ML 框架(如 PyTorch 与 TensorFlow)的集成示例。
API 端点与云集成
除本地部署外,MiniMaxAI 还与主要云提供商合作,提供托管 API 服务。开发者可通过 RESTful 端点调用 MiniMax‑M1,并使用提供的 Python、JavaScript 与 Java SDK。API 支持配置上下文长度、专家路由阈值与令牌预算等参数,使用户能针对自身用例定制性能,同时实时监控算力消耗。
如何在实际应用中集成并使用 MiniMax‑M1?
要充分发挥 MiniMax‑M1 的能力,需要理解其 API 模式、长上下文提示的最佳实践,以及工具编排策略。
基本 API 用法示例
一次典型的 API 调用会发送包含输入文本与可选配置覆盖项的 JSON 负载。例如:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
响应会返回结构化 JSON,其中包含生成文本、令牌使用统计与路由日志,便于对专家激活进行精细化监控。
工具使用与 MiniMax Agent
除核心模型外,MiniMaxAI 推出了处于测试阶段的 MiniMax Agent——一种可在底层调用外部工具的代理框架,范围涵盖代码执行环境到网络爬虫等。开发者可以实例化一个代理会话,将模型推理与工具调用串联,例如用于获取实时数据、执行计算或更新数据库。该代理范式简化了端到端应用开发,使 MiniMax‑M1 可在复杂工作流中充当编排器。
最佳实践与注意事项
- 长上下文的提示工程:将输入拆分为连贯片段,在逻辑间隔处嵌入摘要,采用“先总结后推理”策略以保持模型聚焦。
- 算力与性能权衡:针对低时延应用,可尝试较低的专家阈值或缩减思考预算(如 40K 变体)。
- 监控与治理:使用路由日志与令牌统计审计专家利用情况,确保符合成本预算,尤其是在生产环境中。
遵循这些指南,开发者即可充分发挥 MiniMax‑M1 的优势——超大上下文处理与高效推理——同时降低大规模模型部署带来的风险。
如何使用 MiniMax‑M1?
安装完成后,可通过简单的 Python 脚本或交互式笔记本调用 M1。
基本推理脚本是什么样的?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
上述示例调用了 40k 预算变体;切换为 "MiniMax-AI/MiniMax-M1-80k" 可解锁完整的 80k 推理预算 ()。
如何处理超长上下文?
对于超出典型缓冲区大小的输入,M1 支持流式分词。在分词器中使用 stream=True 标志按块馈送令牌,并利用检查点重启式推理,在百万令牌序列上保持性能。
如何微调或适配 M1?
尽管基础检查点已能满足大多数任务需求,研究者仍可使用仓库中的 CISPO 代码进行 RL 微调。通过提供自定义奖励函数——从代码正确性到语义保真——实践者可将 M1 适配到特定领域工作流。
结论
MiniMax‑M1 以突破性的 AI 模型形态脱颖而出,推动长上下文语言理解与推理的边界。凭借其混合 MoE 架构、Lightning Attention 机制与 CISPO 支持的训练流程,模型在法律分析到软件工程等任务上实现高性能,同时显著降低计算开销。得益于开放权重发布与云端 API,MiniMax‑M1 面向广泛开发者与组织开放,为构建新一代 AI 应用提供可能。随着 AI 社区持续探索大上下文模型的潜力,MiniMax‑M1 的创新势必影响未来的研究与产品发展。
入门
CometAPI 提供统一的 REST 接口,将数百个 AI 模型(包括 ChatGPT 系列)聚合到一致的端点之下,内置 API Key 管理、使用配额与计费仪表板。无需在多个供应商的 URL 与凭证之间来回切换。
首先,可在 Playground 体验模型能力,并查阅 API guide 获取详细说明。在访问前,请确保已登录 CometAPI 并获取 API Key。
最新的 MiniMax‑M1 API 集成即将上线 CometAPI,敬请期待!在我们完成 MiniMax‑M1 模型上传期间,欢迎在 Models page 浏览其他模型,或在 AI Playground 试用。CometAPI 上 MiniMax 的最新模型为 Minimax ABAB7-Preview API 与 MiniMax Video-01 API,参考如下:
