

Seedance 2.0 是 ByteDance 的下一代 AI 视频生成模型,于 2026 年 3 月正式发布。它支持文本、图像、音频和视频输入,可同时使用最多 9 张图像、3 段视频和 3 段音频作为参考,面向导演级控制、运动稳定性与音视频联合生成设计。在 Artificial Analysis 当前的盲投票榜单中,Seedance 2.0 分别以 Elo 1269 和 1351 的分数,领跑无音频的文本转视频与图像转视频两个类别。
什么是 Seedance 2.0?
Seedance 2.0 是 ByteDance Seed 的新一代视频创作模型。官方介绍称,其基于统一的多模态音视频联合生成架构,接受文本、图像、音频与视频输入,被定位为具备异常广泛参考与编辑能力的创作工具。与 1.5 版本相比,Seedance 2.0 面向工业级内容工作流,在复杂运动场景中的物理准确性、真实感、可控性与稳定性更强。不同于早期主要聚焦文本转视频的模型,Seedance 2.0 引入了一个“完全统一的多模态生成管线”,支持:
- 文本转视频生成
- 图像转视频动画
- 视频转视频编辑
- 音频同步输出
这使其成为 2026 年可用的最“全面”的 AI 视频创作平台之一。
为什么这很重要?
多数视频生成器仍针对相对狭窄的流程进行优化:输入提示,导出片段。Seedance 2.0 更进一步,把视频生成视为导演的工作台。根据 ByteDance 的说法,它可以同时使用多种参考类型,保持主体一致性,更忠实地遵循详细指令,甚至以更“导演化”的方式规划镜头语言。这个组合之所以重要,是因为视频生成中最难的问题不仅是美学,还有跨时间的连贯性、运动一致性,以及对内容发生方式的控制。
Seedance 2.0 的新特性与关键功能有哪些?
统一的多模态生成
最重要的特性是模型能够对多种模态进行联合推理。Seedance 2.0 支持最多 9 张图像、3 段视频与 3 段音频作为参考,结合自然语言指令,最多可生成 15 秒的视频。实际意义在于,你不仅能引导主体与场景,还能在一次生成中控制运动风格、镜头运动、特效与音频提示。
导演级控制
Seedance 2.0 还围绕 ByteDance 所描述的导演级控制构建。创作者可以用参考图像、音频和视频来塑造表演、光线、阴影与镜头运动。该模型可保持稳定的主体身份,准确复现复杂脚本,并以体现内置“剪辑逻辑”的方式选择镜头语言。对创作者而言,这远超基础的文本转视频。
不止于生成:编辑与续写
另一个显著升级是 Seedance 2.0 不止步于生成。它新增了视频编辑与视频续写能力,允许对特定场景、角色、动作或剧情点进行定向修改,并支持连续的跟拍镜头。开发者文章还解释,该模型可通过扩展片段来“继续拍摄”,而不用从头开始。这对于工作流效率很重要,因为无需为修复一段而重生成整场戏。
复杂运动场景处理更出色
在多主体、交互与复杂运动的场景中,Seedance 2.0 显著更强。相较 1.5 版本,生成质量大幅提升,物理准确性、真实感与可控性更好。在其内部评估框架中,Seedance 2.0 在困难运动场景下的可用率达到业界 SOTA 水平,同时也承认在细节稳定性、真实感与生动性方面仍需进一步改进。
性能基准
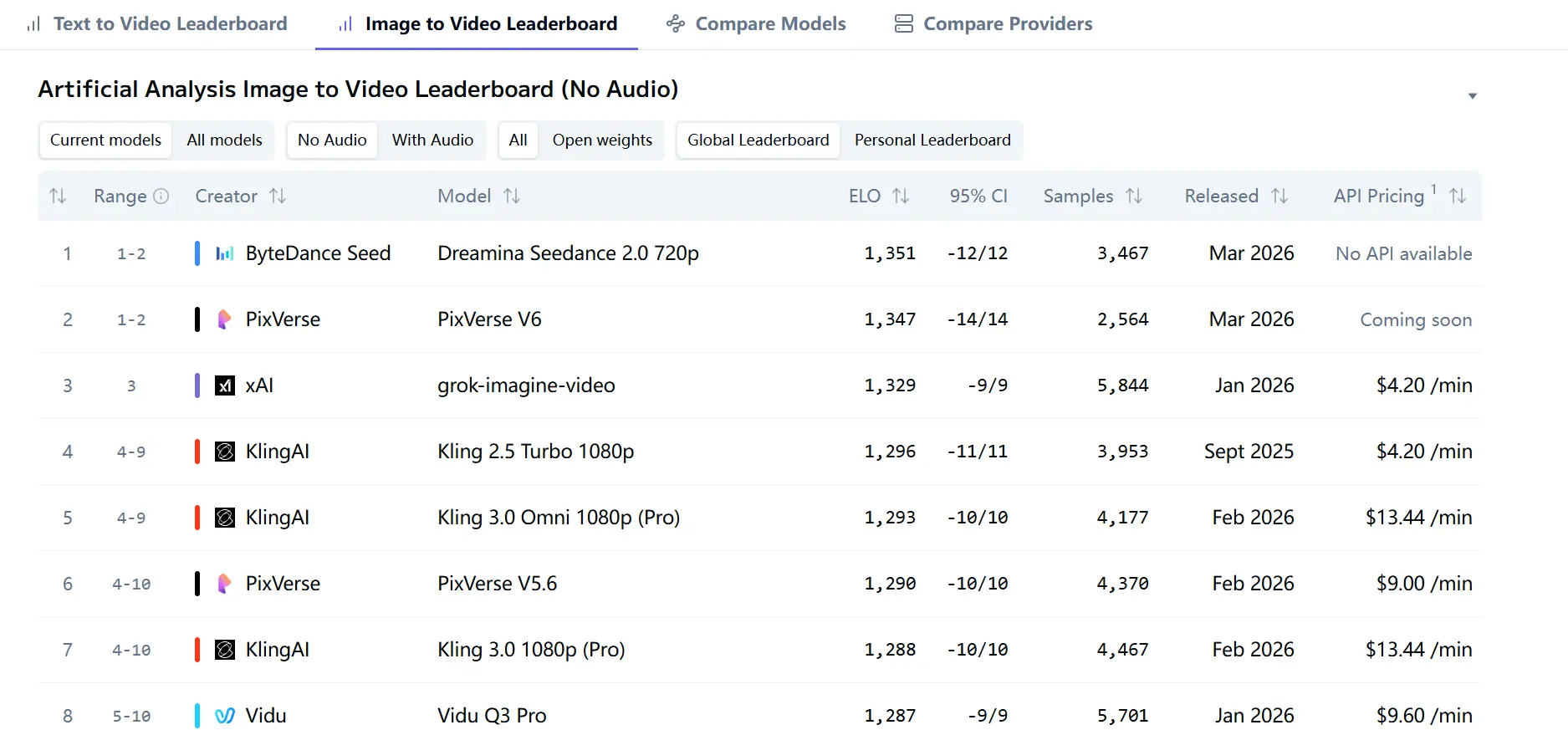
在所述来源中,最强的第三方信号来自 Artificial Analysis 的 Video Arena。当前的排行榜页面显示,Dreamina Seedance 2.0 720p 在“无音频图像转视频”中以 Elo 1351 领先,在“无音频文本转视频”中以 Elo 1269 领先。排行榜页面还注明排名来自“用户盲投票”,这很重要,因为它衡量的是规模化的人类偏好,而非仅仅模型内部指标。
这很重要,因为这意味着 Seedance 2.0 不仅被宣传为很强,它目前在两个主要擂台的正面对比测试中也更受用户青睐。在无音频文本转视频中,它领先 Kling 3.0 1080p (Pro)、SkyReels V4、PixVerse V6 和 Kling 3.0 Omni 1080p (Pro)。在无音频图像转视频中,它以微弱优势领先 PixVerse V6 和 grok-imagine-video。

Seedance 2.0 性能快照
| 指标 | Seedance 2.0 |
|---|---|
| 图像转视频排名 | 全球前15名 |
| ELO 分数 | ~1258 |
| 文本转视频排名 | 前25名 |
| 成本 | ~$1.56/min |
| 优势 | 成本-性能平衡 |
👉 解读:
- 原始画质不一定总是第 1
- 但具备优秀的性价比
Seedance 2.0 到底有多强?
最突出的优势
Seedance 2.0 的优势非常明显:它比许多视频模型更擅长处理复杂运动,支持多种参考模态,提供编辑与续写能力,并且在当前最受关注的公开擂台上(无音频文本转视频与图像转视频)位居前列。物理准确性、真实感和可控性的改进,恰恰是模型从玩具级演示走向专业工作流时最重要的属性。
当前的局限
ByteDance 并未将 Seedance 描述为完美。细节稳定性、真实感与运动生动性仍有提升空间,并指出在多主体一致性、文字渲染精度与复杂编辑效果方面仍存在挑战。
我的评估
基于所查阅的来源,Seedance 2.0 与其说是一次小幅升级,不如说是向面向生产的视频系统迈出的严肃一步。它的最佳卖点不是单个花哨的演示,而是更广泛的多模态输入栈、直接的编辑控制、片段续写,以及可信的公开排行榜领先地位的组合。这使它成为当下最重要的视频模型之一,尤其适合同样重视可控性与电影级画质的团队。
Seedance 2.0 vs Sora 2 vs Veo 3.1
对比表(2026 年 AI 视频领先者)
| 特性 | Seedance 2.0 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| 开发方 | ByteDance | OpenAI | |
| 输入类型 | 文本、图像、音频、视频 | 文本 | 文本 + 图像 |
| 音频生成 | ✅ 原生 | ❌ 受限 | ✅ |
| 最长视频时长 | 15–20 sec | ~25 sec | ~8 sec(可延长) |
| 编辑能力 | ⭐ 高级(基于参考) | 中等 | 中等 |
| ELO 排名 | 前 15–25 名 | 高 | 高 |
| 成本效率 | ⭐ 高 | 中 | 中 |
| 商用 | 是 | 受限(水印) | 是 |
| 独特优势 | 多模态编辑 | 长篇叙事 | 视觉保真度 |
关键要点
- Seedance 2.0 = 最强编辑能力 + 多模态灵活性
- Sora 2 = 最佳叙事长度
- Veo 3.1 = 最佳图像转视频保真度
在当前 Artificial Analysis 的文本转视频排名中,Seedance 2.0 720p 在无音频类别领先 Veo 3.1 与 Sora 2 Pro。这并不能终结所有关于质量的讨论,因为这些模型在工作流、安全约束与产品包装上各有不同,但它确实表明 Seedance 2.0 已进入与最受瞩目的西方产品同一梯队。
Seedance 2.0 最明显的优势是输入广度。ByteDance 表示它可以联合处理文本、图像、音频与视频,并可同时使用多达 9 张图像、3 段视频和 3 段音频。相较之下,OpenAI 的 Sora 2 文档列出文本与图像为输入,视频与音频为输出,通过 Sora 应用与 sora.com 访问;Sora 2 Pro 也可通过网页端的 ChatGPT Pro 使用。Google 的 Veo 3.1 介于二者之间:它围绕图像引导创作与富音频视频生成构建,支持最多 3 张参考图像、场景扩展与首尾帧控制。
如何访问与对比
如果你想在同一平台上同时访问 Sora 2、Veo 3.1 和 xx,我推荐使用 CometAPI。CometAPI 的 Playgoud 只需一个简单的命令或若干参考图片,就能直接进行视频生成。如果你想以编程方式配置自己的视频生成 API,那么 CometAPI 更值得考虑。它为 Sora 2、Veo 3.1 等提供 API,目前价格享受 20% off。
如何在 CometAPI 上使用 Seedance 2.0
文本转视频生成
输入你场景的描述。越具体越好——包括镜头运动、光线、氛围与风格。Seedance 2.0 的强提示遵循性意味着输出能高度贴合你的意图,使其更适合内容生产而非反复试错。
在 CometAPI Playground 中,你可以直接输入提示,用 Seedance 2.0 模型生成视频。这对社媒内容(Reels、TikTok、YouTube Shorts)、品牌视频与短叙事片段尤其有用。
操作步骤:
- 打开 CometAPI
- 选择 Seedance 2.0 模型
- 输入你的提示词
- 调整参数(时长、分辨率、纵横比)
- 运行生成任务并等待输出
使用 CometAPI 的图像转视频
上传一张静态图像——例如产品照片、概念插画或设计稿——并通过 CometAPI 使用 Seedance 2.0 的图像转视频能力对其进行动画化。
结果是从你的视觉输入中生成平滑、具备上下文意识的运动。这非常适合已经拥有设计素材、希望不经完整制作流程即可转换为视频的团队。
操作方式:
- 使用
input_reference(或 Playground 中对应的文件上传字段) - 添加以运动为重点的提示,描述场景该如何运动
示例提示:
"镜头缓慢推进至产品,柔和棚拍光效,细腻反射,高级商业质感"
一次性音视频联合生成
与先生成视频再单独添加音频不同,CometAPI 支持 Seedance 2.0 的原生音视频联合生成管线。
通过在单条提示中同时描述画面与声音,你可以一步生成同步的视频与音频。这样能得到更协调且有意图的结果,同时减少后期编辑时间。
示例提示:
"宁静的海滩日出,海浪轻拍,暖金色光线,伴随海洋声的柔和氛围音乐"
输出包括:
- 生成的视频
- 同步的背景音频
- 自然对齐的节奏与情绪
为什么为 Seedance 2.0 使用 CometAPI
- 通过 API 或 Playground 直接访问
- 轻松控制参数(时长、分辨率、格式)
- 同时支持 文本转视频 与 图像转视频 工作流
- 内置异步视频生成的任务处理
结论
Seedance 2.0 看起来是 AI 视频生成领域的一次真正跃进:一个将文本、图像、音频与视频输入结合起来的多模态系统;在文本转视频与图像转视频两大擂台上领跑的模型;以及一个为导演式控制而非随意玩乐而打造的模型。如果你只关心原始感知质量,现有证据表明它表现出色。
立即在 CometAPI 上使用 Seedance 2.0 开始创作。