

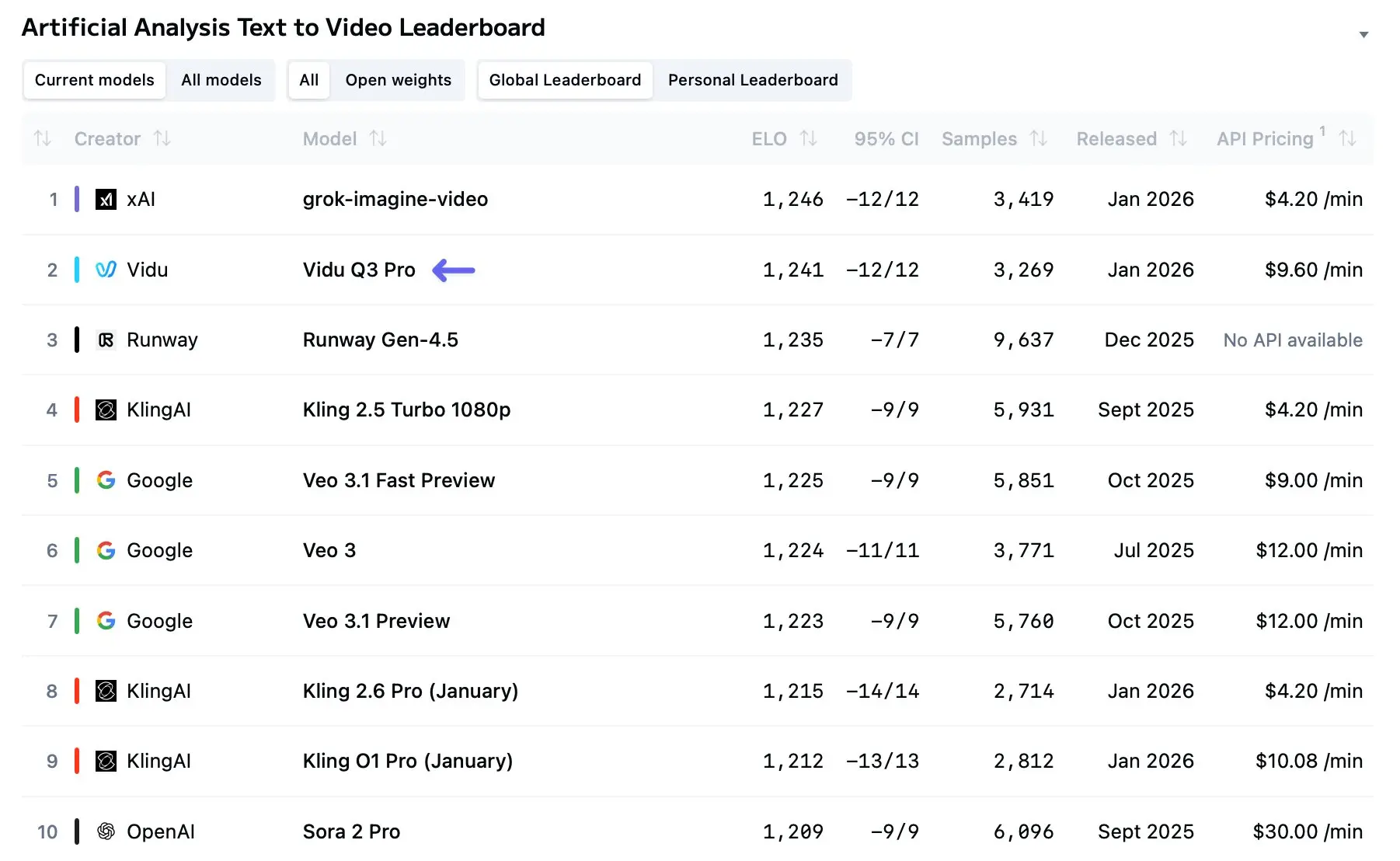
Vidu Q3 于 2026 年初进入讨论,成为最明确的信号之一:AI 驱动的视频生成正在从短、猎奇的片段转向真正具有叙事性、多镜头的故事讲述。自广泛发布以来的数月里,Vidu Q3 已成为创作者工作流、研究试点与商业试点的常用工具——理由很充分:它在时长、视听集成与多镜头一致性方面比多数早期模型走得更远,同时还提供面向开发者的 API 以便程序化使用。
什么是 Vidu Q3?
Vidu Q3 是 ShengShu Technology 的大型视频模型(LVM)架构的最新旗舰版本。不同于其前代(Vidu 1.0 和 1.5)需要分别进行视觉生成与音频后期处理,Vidu Q3 是一款“全合一”的生成引擎。
Vidu Q3 的核心突破在于能够同时生成高清视觉与高保真音频。[ 通过同时理解声音与光的物理特性,模型消除了竞争产品中常见的音画不同步所带来的“怪诞感”。它支持一次性连续生成最长约 16 秒的原生 1080p 分辨率内容,使其成为短片、商业广告与叙事性故事创作的可投入制作的工具。
Vidu Q3 的底层工作原理是什么?
尽管核心架构细节是专有的,Vidu 构建在 U-ViT 融合扩散模型与 Transformer 之上——该设计以在视频生成中平衡一致性、时间连续性与表现力而著称。
这种混合架构使模型能够在更长序列中对运动、声音与叙事上下文进行推理。
Vidu Q3 的 6 个亮点特性
1. 扩展时长生成——它能持续多久?
Vidu Q3 的头号特性之一是更长的单次生成时长。许多早期生成模型聚焦于“微短片”;Q3 刻意延长片段长度,以便在不强迫创作者拼接大量微小片段的情况下,允许简单的故事弧和多镜头序列。平台文档与合作伙伴门户宣称一次可原生生成最长约 ~16 s(具体格式与质量选项可能因服务商和 API 套餐而异)。这很重要,因为从 4–8 s 提升到 16 s 会改变创作者规划场景、编写节拍与安排音频提示的方式。
2. 视觉保真度与时间一致性
独立评估与早期基准显示,Vidu Q3 输出的画面更清晰、帧级失真更少,优于早期的消费级模型。架构与数据增强的改进似乎降低了闪烁现象,并改善了 10–16 s 以内片段的运动连续性。不过,模型在密集的多主体场景(人群、复杂物理交互)中仍可能遇到挑战,此类遮挡与细微运动需要更强的物理推理。比较排行网站与模型榜单已将 Vidu Q3 列在 T2V(文本到视频)榜单的前列,但排名会因基准与数据集而异。
3. 原生音视频一体生成
不同于只生成静音画面并将音频留给后期的系统,Vidu Q3 在模型内集成了音频生成。结果包括口型同步的对白、定时的音效(SFX),以及与画面同时生成的可选背景音乐。在模型层面集成声音能减少对齐误差(口型同步漂移、节拍错位),并缩短用于演示、预览与许多成片格式短内容的制作周期。
4. 智能镜头控制与多镜头叙事
Q3 的“智能相机”功能可根据提示语理解镜头运动(摇镜、推轨、跟踪)与多镜头序列。模型不再只生成单一静态视角,而是能够生成计划好的剪切与转场,让输出读起来像一段有导演意图的场景。对创作者而言,这将输出从“一个会动的构图画面”转变为“一个包含多个镜头的短场景”。这提升了可观看性,并在一次生成中实现更丰富的视觉叙事。
5. 多参考一致性与角色保真
Vidu(作为平台)在“参考到视频”与多参考一致性系统上投入较多,允许创作者上传多张参考图以锁定角色在各帧的身份。Q3 将这些能力扩展到在多个镜头角度与剪切中保持角色外观与道具的一致性——这是实现连贯叙事输出的基本且关键要求。这对动漫或风格化项目尤其有用,因为保持一致的角色美术至关重要。
6. 面向开发者的准备:API 与工作流
包括 Q3 在内的 Vidu 模型套件可通过网页 UI 与程序化的 REST API 使用。开发者可以向推理端点提交文本到视频或图像加文本的任务,收到任务 ID 并轮询获取结果(典型异步任务模式)。API 提供参数,如分辨率、纵横比、时长、运动幅度,以及音频生成开关。这使 Q3 可用于自动化、批处理工作流,并与编辑管线集成。
Vidu Q3 与 Sora 2 和 Veo 3.1 如何比较?
简短回答:Vidu Q3 在 10–20 s 场景的较长叙事输出与音视频一体生成方面竞争力强;Sora 2 擅长物理可信的单镜头写实与社交集成;Veo 3.1 则在像素级精致度、多帧连续性工具与企业级 API 集成方面领先。下面我们从实用维度展开差异。
哪个模型在写实与物理方面更强:Sora 2 还是 Vidu Q3?
Sora 2(OpenAI) 明确以物理可信性与世界模拟为训练目标——其公开说明强调先进的物理行为、精确的物体交互与高度写实的运动轨迹。Sora 2 还提供同步音频与社交应用集成(包括客串与移动应用),使其在逼真、物理连贯的场景中表现出色。如果你的需求强调在短、完整的镜头中实现准确碰撞、逼真动力学或照片级人类运动,Sora 2 往往更优。
Vidu Q3 则更像是一个叙事引擎:更长片段、多镜头序列与导演式镜头控制。这并不意味着 Vidu 牺牲写实性,但它的主要优势在于叙事连续性与视听一体的输出,而非纯粹的物理模拟。对于电影化的短叙事(例如包含剪切与旁白的 16 s 产品演示),Q3 的工作流通常更快更简洁。
哪个模型在电影化打磨与高保真方面更好:Veo 3.1 vs Vidu Q3?
Veo 3.1(Google / DeepMind / Gemini) 被定位为高保真、企业级选项,具备强连续性控制、原生音频生成,以及在 Google 云/Vertex/Gemini 生态中的支持。Veo 3.1 引入了先进的“素材到视频”功能、原生竖版(9:16)支持,并可升尺度到高分辨率(某些流程包括 4K 能力)。对于需要最高像素质量、精确色彩和谐度与严密企业级 API 的项目,Veo 3.1 往往是不二之选。
Vidu Q3 则通过聚焦“延长时长 + 多镜头故事一致性”以及以创作者为中心的产品化(快速网页试验、参考多图编排)来保持竞争力。如果你的优先级是生成含多个镜头运动与集成音频提示的人导短场景(且更看重长度,而非绝对像素精致度),Vidu Q3 很有吸引力。就原始照片级写实度而言,Veo 3.1 通常略胜一筹。
截至 2026 年初,AI 视频“三巨头”包括 OpenAI 的 Sora 2、Google 的 Veo 3.1 以及 Vidu Q3。以下是它们的直接对比:
| Feature | Vidu Q3 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| Max Single Clip Duration | ~16 s | Up to ~25 s (Pro) | 8 s (with narrative stitching features) |
| Native Audio Generation | Yes (integrated) | Yes (experimental) | Yes (advanced) |
| Cinematic Camera Control | Yes (shot aware) | Limited presets | Yes (multi-shot consistency) |
| Multi-shot Narrative | Yes | Yes | Yes |
| Text Rendering in Frames | Yes | Varies | Varies |
| Resolution | 1080p | 1080p | 1080p / 4K in special cases |
| Primary Use Case | Narrative Storytelling, Animation | High-Budget Concept/Film | Youtube Shorts / TikTok |
分析:
- 对比 Sora 2: Sora 2 仍是纯视觉保真与超现实想象(“好莱坞级品质”)的重量级选手。然而,Vidu Q3 在工作流效率上更胜一筹,得益于 16 秒限制与更优的音频集成。对需要“一次就完成”的片段的创作者而言,Q3 更快。
- 对比 Veo 3.1: Google 的 Veo 3.1 在更短、面向社交媒体的片段(4–8 s)上具备速度优势,并与 YouTube 深度集成。Vidu Q3 瞄准价值链更高处,面向需要更长、连续剪切(而 Veo 难以稳定维持)的专业动画师与电影人。
Vidu Q3 可实现哪些实际应用?
广告与短营销内容
品牌可更快完成端到端的广告原型:写脚本、生成带同步旁白与音效的 16 秒画面、在措辞与镜头构图上迭代,并通过提示语言变体生成多语言配音。对于社交创意的 A/B 测试,缩短的周转时间是显著的业务收益。平台发布的案例显示,营销人员使用 Vidu Q3 制作微型广告与产品预告。
影视分镜与前期可视化
导演与剪辑师使用短 AI 片段作为前期可视化(previz),用于调度走位、测试镜头运动与提案方案。Vidu Q3 的多镜头序列与智能镜头控制在此尤其有用:创意团队可在不进行外景拍摄的情况下迭代走位与对白。虽然 AI 前期可视化不能替代现场导演,但它能缩短早期决策周期。
电子学习与解说视频
教育与企业培训团队可生成简洁的动画解说片段,包含同步解说与注释音效。对于标准化内容(产品培训、入职引导),这可降低对昂贵制作公司的依赖,并加速本地化版本。发布速度与原生音频能力使 Vidu Q3 在这些用例中颇具吸引力。
游戏、概念美术与独立制作
独立开发者与游戏团队使用短 AI 电影化片段进行预告片、NPC 对话样片或风格探索。Vidu Q3 对参考图与角色一致性的支持有助于在原型预告片中保持游戏 IP 的视觉识别。该模型也用于制作提案材料以争取融资或发行方兴趣。
无障碍与快速本地化
由于音频为原生生成,Vidu Q3 简化了多语言版本制作:用不同语言提示生成同一镜头,或要求不同的声线。这让营销内容或培训资产的快速本地化成为可能,同时保持足以满足许多短内容场景的口型近似(尽管广播级的顶级唇形匹配仍可能需要人工微调)。
Vidu Q3 是 2026 年最好的 AI 视频模型吗?
宣称一个“最佳”模型缺乏细致性:赢家取决于用例。
- 对于照片级、物理扎实的输出与保守的安全处理, OpenAI 的 Sora 2 常被视为首选。它强调写实与稳健审核,使其对高端制作与风险规避型企业具有吸引力。
- 对于平台集成度高、格式优化的短内容, Veo 3.1 的原生竖版输出与 Google 的应用集成(YouTube Shorts、Google Photos)让其独具便捷性。
- 对于快速的音视频原型、强多镜头叙事控制与均衡的故事能力, Vidu Q3 表现突出——尤其当迭代速度与音频集成比绝对写实更重要时。早期基准与厂商报告将 Vidu Q3 排在 T2V 榜单前列,其特性使其成为营销人员、独立创作者与工作室进行新点子原型的务实选择。
限制与注意事项?
尽管 Vidu Q3 是一次突破,它也有取舍:
- 片段时长 仍有上限(约 ~16 s),更长叙事需要拼接或多次提示。
- 资源成本 会随高清生成与复杂音频而增加。
- AI 工具仍需 编辑判断 将输出打磨成成品。
因此:Vidu Q3 是 2026 年的一线竞争者,尤其适合优先考虑原生音频工作流与多镜头叙事的创作者。是否为“最佳”取决于你的具体制作需求、监管约束与分发管线。
结论
Vidu Q3 在 2026 年脱颖而出,作为能够生成叙事就绪、音视频一体的片段的领先 AI 视频模型,兼顾创意与制作需求。与 Sora 2 的强叙事凝聚 和 Veo 3.1 的电影化写实 相比,Vidu Q3 提供了为讲述者、内容创作者与商业工作流量身打造的均衡工具包。
随着基准显示其高性能与集成特性,Vidu Q3 代表了生成式视频 AI 的一个转折点——让复杂的视听制作更加易得与高效。
开发者可通过 CometAPI 访问 Vidu Q3、Veo 3.1 和 Sora 2,文中列出的最新模型以发布时为准。开始之前,可在 Playground 中探索模型能力,并查阅 API guide 获取详细说明。访问前,请确保已登录 CometAPI 并获得 API 密钥。CometAPI 提供远低于官方价格的方案,帮助你集成。
准备好了吗?→ 立即注册开启视频生成!