

作為一名人工智慧創造者,我很高興向你介紹 奈米香蕉 — 俏皮的暱稱 Gemini 2.5 Flash 影像 — Google 最新的高保真圖像生成和編輯模型。在本篇深入講解中,我將解釋它是什麼、如何使用它(應用程式和 API)、如何有效地提示它,並提供具體範例、包含可運行的程式碼,並逐步講解 七種富有創意的實用用途 您今天就可以開始申請。
什麼是 Gemini 2.5 Flash 映像(Nano Banana)?
Gemini 2.5 Flash Image 是 Gemini 系列中全新的影像生成與編輯模型。它擴展了 Gemini 2.5 Flash 系列的功能,使其能夠生成和編輯圖像(而不僅僅是文字),並結合了 Gemini 的多模態推理、世界知識和提示驅動控件,可以根據文字和/或圖像輸入創建或修改圖像。團隊和開發者文件明確將其稱為“Gemini 2.5 Flash Image”,並註明了內部暱稱。 奈米香蕉.
在公告中,Gemini 2.5 Flash Image 層級的公佈價格為 每 30 萬個輸出代幣 1 美元,每張圖片的成本示例如下 1290 輸出代幣 ≈ 每張圖片 $0.039。該模型目前提供預覽版(開發者/預覽版 ID 如下 gemini-2.5-flash-image-preview) 並且已經透過選定的合作夥伴 (CometAPI) 和 Google 自己的開發者平台提供。
Gemini 2.5 Flash Image 有哪些突出特色?
編輯過程中的人物和風格一致性
其中一項核心改進是 角色一致性:該模型經過精心調校,能夠確保同一主題(人物、寵物或產品)在多次編輯和不同語境下保持視覺一致性——這是早期圖像模型長期以來的弱點。這改進了需要保持一致的品牌資產、在敘事中反覆出現的角色或自動生成多鏡頭產品照片的工作流程。
基於提示的本地化編輯
您可以提供一張圖片以及自然語言指令,例如“去除襯衫上的污漬”、“換成藍色夾克”或“模糊背景並增加主體亮度”,模型會執行有針對性的局部編輯,在大多數情況下無需手動遮罩。這使得迭代式對話式編輯變得切實可行。
多影像融合與風格轉換
Gemini 2.5 Flash Image 可以拍攝多張影像,並且 撰寫 將它們合併到一個場景中,或將樣式/紋理從一個圖像轉移到另一個圖像。這樣就可以實現產品模型(將產品放入場景中)、家具展示,或用於行銷和電子商務的組合圖像。
本土世界知識
由於該模型建立在 Gemini 系列之上,因此它利用世界知識(例如,理解道具、環境或上下文正確的物件關係),這有助於構建逼真的場景和語義連貫的編輯(而不僅僅是美學上合理的輸出)。
低延遲和成本效益
與更大的推理層相比,Gemini 的「Flash」系列旨在實現低延遲和經濟高效的使用。開發者公告強調了速度以及在眾多實際用例中實現的良好性價比。
內建出處:SynthID 浮水印
使用該模型建立/編輯的所有圖像都包含 隱形的 SynthID 數位浮水印 因此,這些影像之後可以被驗證是 AI 生成還是 AI 編輯的。這是 Google 針對濫用和來源追蹤的產品級緩解措施的一部分。
1)如何為長期連載的漫畫或品牌活動創造一致的角色?
為什麼這樣做
Nano Banana 經過專門訓練,能夠在不同的剪輯和新情境中保持相同的角色外觀——當你需要在不同的劇集、縮圖或主圖之間保持相同的面孔、服裝或吉祥物時,這非常有用。開發人員稱之為「角色一致性」。
如何提示
- 從捕捉身分特徵(年齡範圍、臉部特徵、特徵標記、服裝元素)的描述性區塊開始。
- 新增“一致性標記”指令,例如“在所有輸出中使用相同的字元 - 不要更改識別標記”。
- 對於多影像輸出,提供一個或多個參考影像作為輸入以鎖定相似性。
如何促使編輯保持一致
- 首先描述您想要保留的核心身分屬性:年齡、髮色、顯著特徵(例如「左臉頰上有一顆小痣」)和衣著風格。
- 編輯時使用兩部分提示:先描述一下 必須的, 保持不變,然後描述 改變 你想要的。例如:“保留:28歲的東亞女性,黑色短髮,左臉頰有一顆小痣。修改:將她放在一家1970世紀XNUMX年代的餐館裡,身穿紅色皮夾克,面帶微笑,燈光為溫暖的鎢絲燈。”
- 進行多步驟編輯時,在提示中包含一個小的參考標記,如“(KEEP_ID:A)”,並重複使用它來在提示之間發出相同的主題信號。
示例提示
「創造逼真的肖像 阿米娜一位28歲的漫畫小說家,留著不對稱的短髮,左臉頰上長著一顆月牙形的痣,有著一雙溫暖的棕色眼睛,身穿綠色皮夾克。請在以下6個場景提示中保留阿米娜的識別特徵:「阿米娜在早晨的咖啡店」、「阿米娜在公園寫生」…。每個場景都使用相同的人物肖像。
程式碼片段(Python,產生多張圖片)
此範例使用 Google 文件中顯示的 Gemini API 用戶端 - 傳遞您的描述性提示和循環場景變體。
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client()
base_description = (
"Photorealistic portrait of Amina: 28yo graphic novelist, short asymmetrical haircut, "
"crescent mole on left cheek, warm brown eyes, green leather jacket. Keep likeness identical across scenes."
)
scenes = [
"Amina at a morning coffee shop, reading a sketchbook, warm golden hour light.",
"Amina sketching in the park, windy afternoon, soft bokeh background.",
# add more scenes...
]
for i, scene in enumerate(scenes, start=1):
prompt = f"{base_description} Scene: {scene}"
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=,
)
parts = response.candidates.content.parts
for part in parts:
if part.inline_data:
img = Image.open(BytesIO(part.inline_data.data))
img.save(f"amina_scene_{i}.png")
2)Nano Banana 如何加速電子商務產品攝影和 A/B 影像?
為什麼這具有創造性和實用性
產品團隊在多鏡頭拍攝、燈光設定和變化(顏色、背景)上投入了大量資源。 Nano Banana 的 多影像融合 精確的快速編輯讓您可以快速產生一致的產品變體和生活方式合成物(用於目錄鏡頭、生活方式場景和社交資產),從而縮短迭代時間和生產成本。
如何提示產品變體
- 提供簡短的產品規格(尺寸、材質、調色板)和攝影風格(例如“工作室白色背景、45° 角、柔和陰影”)。
- 對於變體:“製作 4 種不同版本的藍牙耳機:黑色、粉紅色、帶有橙色耳罩的灰色和帶有藍色閃光的灰色 - 所有這些都具有相同的燈光、相同的攝影機角度和在白色的房間裡。”
- 使用多圖像融合將產品放入不同的場景:“在黃金時段將這個背包放在淺景深的野餐毯上。”
範例提示(產品)
圖 A(產品參考):高級皮革背包。創建三個目錄變體,背景為白色——森林綠、棕褐色、炭灰色——以 45° 角拍攝,自然柔和的陰影,ISO 設定為 100。
程式碼片段:快速 Python 生成(目錄變體)
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client(api_key="YOUR_API_KEY")
product_image = open("backpack_ref.png","rb").read()
prompt = ("Make 4 variations of this Bluetooth headset: black, pink, gray with orange ear caps, and gray with blue glint – all with the same lighting, same camera angle, and in a white room.")
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=,
)
# Save images from response parts (example)
for i, part in enumerate(response.candidates.content.parts):
if part.inline_data:
img = Image.open(BytesIO(part.inline_data.data))
img.save(f"backpack_variant_{i}.png")
此程式碼片段反映了 Google 記錄的使用模式,是自動化產品變體創建的良好起點。
輸出影像:

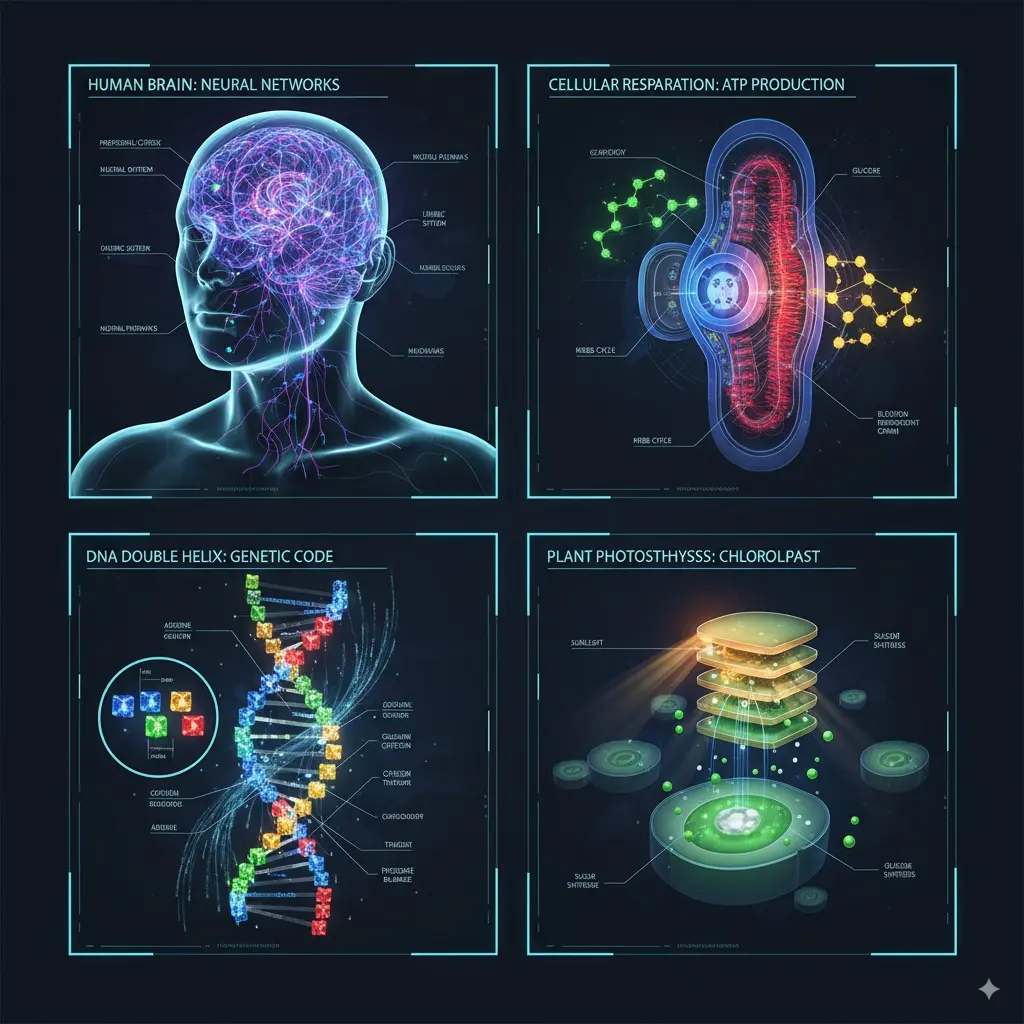
3)如何創建結合照片和圖表的教育插圖?
為什麼這樣做
Nano Banana 集成 世界知識 (Gemini 的多模態推理)因此它可以解釋手繪圖表、註釋圖像或從照片和文字說明的混合中創建解釋視覺效果——這對於電子學習、技術文件和互動式導師來說非常方便。
如何提示
- 提供圖像(例如,物理實驗的照片)和提示,例如「用標籤和箭頭註釋此圖像以解釋關鍵組件,並建立第二張顯示系統橫截面的圖像」。
示例提示
生成四幅知識圖解:人腦的神經網絡,細胞修復的ATP生成,DNA雙螺旋的遺傳密碼,葉綠體的光合生理
輸出影像:
4) 如何將真實照片轉變為品牌行銷變體(服裝、燈光、背景)?
為什麼這樣做
該模型支持 定向轉型 並透過自然語言表達本地編輯:更換服裝、調整燈光、替換背景或移除物體——它會盡力保留主體身份和整體真實感。這使得快速行銷變體(季節性服裝、在地化場景)成為可能。
如何提示
- 提供原始照片作為輸入。
- 要求 針對性的編輯 並附上明確的說明,例如“將夾克換成紅色羊毛大衣,將背景改為黃昏時分的城市街道,添加溫暖的邊緣光。”
示例提示
“從上傳的照片開始,用剪裁合身的紅色羊毛大衣替換藍色牛仔夾克,將背景設置為傍晚的城市街道,並添加柔和的邊緣光以將主體與背景分離。”
提示
- 如果您需要迭代控制,請進行多輪編輯:要求進行第一次編輯,然後進行細化(“移除帽子”,“現在提高色溫”)。
5)動畫創作者和預視團隊如何製作場景和分鏡的原型?
為什麼它有用
導演和攝影指導可以快速製作燈光設定、服裝和攝影機取景的原型。 Nano Banana 可以輸出包含一致角色的故事板,這有助於規劃和預覽。 ()
H3:範例提示
There is a tree house in the forest at night with colorful lights hanging on the trees
輸出影像:

6)奈米香蕉如何用於概念藝術、遊戲資產和一致的遊戲角色?
為什麼遊戲工作室和獨立開發者應該關注
創建藝術資產並迭代角色外觀通常需要藝術家反覆修改角色。 Nano Banana 的角色一致性使其能夠產生眾多姿勢、服裝和燈光設置,並忠實於單個角色的身份——這在前期製作和快速原型設計中節省了大量時間。
如何提示遊戲資產
- 在文中定義「規範」角色表:身高、體型、主要特徵、衣櫃必備品。
- 請求多個輸出:“產生三種具有相同面部特徵的戰鬥盔甲變體,每種變體都以正面、側面和¾姿勢顯示。”
- 對於環境藝術,使用多圖像融合:給出一張角色圖像和一張環境圖像並提示將它們融合。
範例提示(遊戲資產)
「為『風之遊俠凱爾』設計三種盔甲變體:保留臉部特徵(窄下巴,右眉上方有疤痕)。盔甲 A:皮革 + 青色布料;盔甲 B:鱗片 + 黃銅;盔甲 C:啞光黑色隱形盔甲。輸出全身正面、側面、¾。”

裝甲 C:隱形霧面黑

盔甲B:鱗片+黃銅

盔甲A:皮革+青色布
7)如何使用對話式多輪編輯來自動化照片修飾工作流程?
為什麼這樣做
Nano Banana 支援對話式多輪影像編輯:您可以要求編輯,檢查結果,並以自然語言提供更多後續指令。這非常適合建立人機互動的潤飾流程,其中編輯人員可以在多個流程中推動模型。
如何實施工作流程
- 上傳初始照片並要求基線修飾(燈光、去除瑕疵)。
- 每次將新編輯的影像連同下一個指令(「減少高光、增加陰影、裁剪為 4:5」)一起送回模型。
- 記錄每個步驟,以便您可以恢復或將相同的步驟應用於批次。
迷你工作流程片段(Python)
# 1) Initial retouch
prompt1 = "Remove small blemishes, even skin tone, slightly warm color grade"
response1 = client.models.generate_content(model="gemini-2.5-flash-image-preview", contents=)
# save response1 -> edited_v1.png
# 2) Follow-up tweak
prompt2 = "Crop to 4:5, increase local contrast on eyes, desaturate background slightly"
response2 = client.models.generate_content(model="gemini-2.5-flash-image-preview", contents=)
# save response2 -> edited_v2.png
如何讓 Nano Banana 獲得最佳效果?
我應該遵循哪些提示原則?
奈米香蕉最適合 描述性、敘述性的提示 解釋場景、視角、光線和氛圍,而不僅僅是一堆關鍵字。官方指南建議,照片寫實風格需提供相機、鏡頭、光線和風格提示,插畫風格需提供風格和配色提示。此外,還需明確提供約束條件(例如長寬比、背景、文字要求)。
我該如何建立一個強而有力的提示?
以下是簡短、可重複使用的範本:
- 逼真的模板:
A photorealistic of , , in , illuminated by , captured with , emphasizing . Aspect ratio: . - 風格轉換/構圖模板:
Combine Image A (style) with Image B (subject). Transfer the color palette of A, keep subject proportions of B. Final style:.
及時的工程提示(快速清單)
- 使用 一個清晰的敘述句子 而不是許多不連貫的標籤。
- 新增 相機細節 為了達到照片級真實感(例如,「85mm,淺景深」)。
- 為了在編輯過程中保持一致的角色,請參考先前的圖像和您希望保留的屬性(例如,「保留主體的雀斑和藍色圍巾,將髮型改為...」)。
- 編輯時,上傳來源圖像 準確描述要改變哪些區域或元素。
- 使用迭代、多輪編輯來細化微小的視覺細節(Nano Banana 支援對話細化)。
最後的說明
Nano Banana(Gemini 2.5 Flash Image)是一次創意飛躍:它讓創作者在保持角色和產品連續性的同時,還能進行大膽的全新編輯、融合多張圖片並進行快速迭代。使用它來加速故事敘述、減少製作摩擦並快速製作視覺效果原型——但這些優點也需要嚴格的審查和道德規範。
入門
CometAPI 是一個統一的 API 平台,它將來自領先供應商(例如 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等)的 500 多個 AI 模型聚合到一個開發者友好的介面中。透過提供一致的身份驗證、請求格式和回應處理,CometAPI 顯著簡化了將 AI 功能整合到您的應用程式中的過程。無論您是建立聊天機器人、影像產生器、音樂作曲家,還是資料驅動的分析流程,CometAPI 都能讓您更快地迭代、控製成本,並保持與供應商的兼容性——同時也能充分利用整個 AI 生態系統的最新突破。
開發人員可以訪問 Gemini 2.5 Flash 影像(奈米香蕉彗星API列表 gemini-2.5-flash-image-preview/gemini-2.5-flash-image 在其目錄中新增樣式條目。 )透過 CometAPI,列出的最新模型版本截至本文發布之日。首先,探索模型的功能 游乐场 並諮詢 API指南 以獲得詳細說明。造訪前請確保您已經登入CometAPI並取得API金鑰。 彗星API 提供遠低於官方價格的價格,幫助您整合。