

代理程式編碼-使用自主人工智慧的實踐 代理 軟體規劃、編寫、測試和迭代——從研究演示階段到 2024-2025 年,將逐步轉變為實際的開發工作流程。隨著 2025 年 10 月 克勞德俳句 4.5,Anthropic 提供了一個明確優化的模型 代理的 工作負載:快速、經濟高效,並針對子代理程式編排和「電腦使用」任務(例如,駕駛工具、編輯器、命令列介面 (CLI))進行了調整。本指南整合了最新資訊、功能說明、實用技巧和治理最佳實踐,以便開發人員和工程領導者能夠在 2025 年負責任且有效地採用代理程式設計。
什麼是「代理編碼」(編排、子代理)?
代理編碼 指的是LLM的使用模式,其中模型不僅編寫程式碼,還能協調操作、呼叫工具、處理中間結果,並作為更大工作流程的一部分自主管理子任務。實際上,這意味著模型可以像一個「程式設計師代理」一樣,規劃一系列步驟,將工作委託給子代理程式/工具,並使用它們的輸出來產生最終的成果。 Anthropic和其他公司正在明確地建立支持這種風格的模型和工具框架。
編排與子代理
- Orchestrator的:控制器(可以是人工、類似 Sonnet 4.5 的專用代理模型或精簡程序)負責將複雜任務分解為離散的子任務,並將它們分配給子代理,最後將結果整合在一起。協調器負責維護全域狀態並執行策略(例如安全性、預算)。
- 子代理:小型、專注的工作者(通常是像 Haiku 4.5 這樣的輕量級模型,甚至是確定性程式碼模組)處理單一子任務 - 例如摘要、實體提取、編碼、API 呼叫或驗證輸出。
使用 Claude Haiku 4.5 作為子代理(編碼器)並使用更強大的推理模型作為編排器是一種常見且經濟高效的設計:編排器進行規劃,而 Haiku 快速且廉價地實現許多小型、可並行的操作。
為什麼現在很重要
多種因素共同作用,使得代理編碼在 2025 年變得實用:
- 已調整的模型 電腦使用,為工具呼叫、測試和編排提供更好的可靠性。
- 延遲和成本的改進使得能夠並行運行多個代理實例。
- 工俱生態系統(API、沙箱、CI/CD 整合)讓代理程式以受控、可觀察的方式運作。
Claude Haiku 4.5 明確定位於利用這些趨勢,透過提供適合子代理編排的速度、成本和編碼能力的平衡。
心智模式(常見模式): 規劃者 → 工作者 → 評估者。規劃者將目標分解為任務;工作者子代理程式運作任務(通常並行);評估者進行驗證並接受或要求改進。
Claude Haiku 4.5 — 開發人員的新功能
Anthropic 於 2025 年 10 月發布了 Claude Haiku 4.5,這是一個高吞吐量、經濟高效的模型,針對編碼、電腦使用和代理任務進行了最佳化。這個版本專注於提升速度和單位令牌成本,同時保留強大的編碼和多步驟推理效能——這對於實際的代理工作流程至關重要,因為在實際工作流程中,許多短小的工具呼叫和循環是常態。 Haiku 4.5 被定位為 Anthropic Haiku 層中最經濟的選擇,同時在程式碼和代理任務方面擁有重要的任務級效能。該模型已透過 API 提供,使開發人員能夠將其整合到 CI 系統、IDE 內建工具和伺服器端編排器中。
基準和實際性能
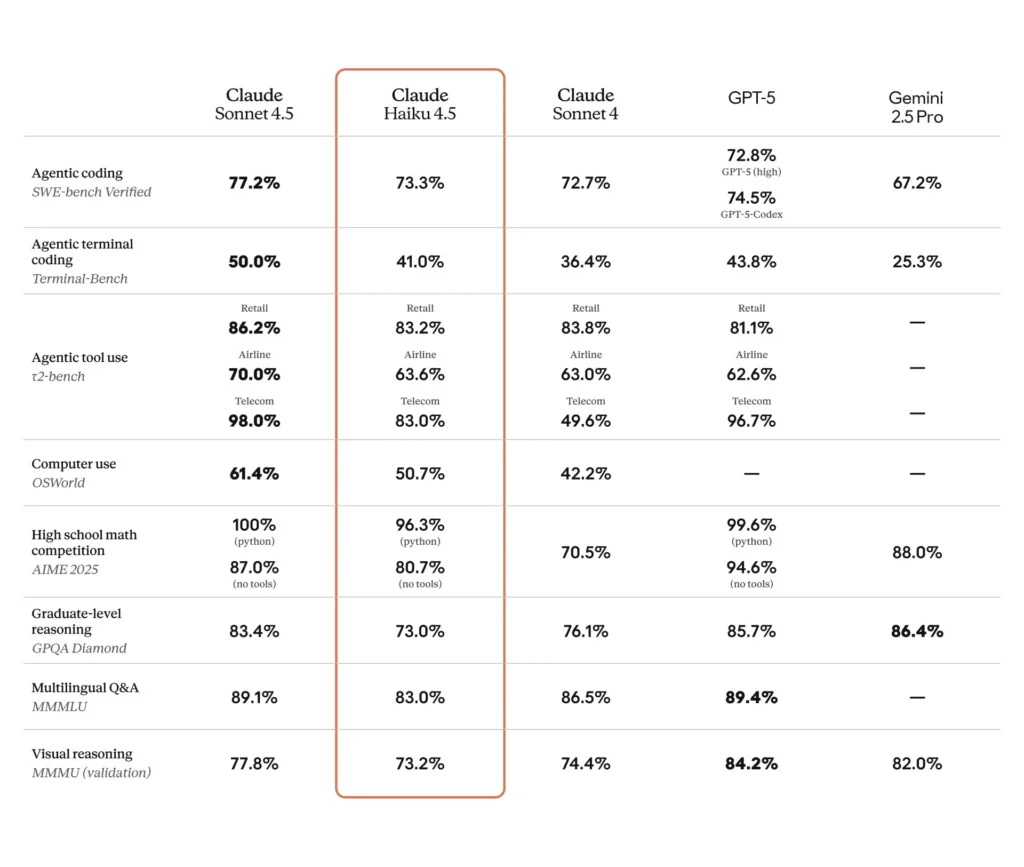
主要指標包括:Claude Haiku 4.5 在 SWE-bench Verified 等編碼基準測試中取得了優異的成績(在 Anthropic 材料中報告的準確率約為 73.3%),並且在“計算機使用”(工具驅動的任務)方面相比之前的 Haiku 版本表現出顯著的改進。 Claude Haiku 4.5 在許多開發任務上與 Sonnet 4 不相上下,同時在成本/性能方面也進行了權衡,使其對規模化的代理系統具有吸引力。
支援代理編碼的關鍵 Claude Haiku 4.5 功能
針對循環和工具呼叫調整速度和成本概況:代理循環通常涉及多個短模型呼叫(規劃 → 工具呼叫 → 評估 → 重新規劃)。 Haiku 4.5 強調吞吐量和更低的代幣成本,讓您能夠以經濟實惠的方式運行更多迭代。當您的編排器產生用於測試、linting 或建立實驗分支的子代理程式時,這一點至關重要。
更強大的短格式編碼和“計算機使用”: Haiku 4.5 經過調優,在編碼基準測試和模擬計算機執行的任務(運行 Shell 命令、編輯文件、解釋日誌)中表現出色。這使得它對於自動化腳本(LLM 讀取輸出、確定後續步驟並發出後續命令)更加可靠。使用此功能可以自動化分類、建造鷹架和測試修復週期。
API 和生態系統可用性: Haiku 4.5 可透過 API 存取(例如 彗星API ) 以及透過雲端合作夥伴(例如 Vertex AI 和 Bedrock 清單)進行集成,從而簡化與現有 CI/CD 管線、容器化編排器和雲端服務的整合。穩定的程式介面可以減少脆弱的膠水程式碼,並實現一致的速率限制、重試和可觀察性。
與 Haiku 4.5 完美相容的多代理編排模式
當 Haiku 4.5 成為您廉價、快速的工作器時,幾種經過驗證的編排模式脫穎而出。
1)分層編排(主/從)
運作方式: 高階規劃器(Sonnet)→中階調度器(Haiku 編排器)→工作池(Haikus + 確定性程式碼)。功能更強大的編排器(例如 Sonnet 4.5)產生計劃,並將步驟指派給多個 Haiku 4.5 工作器。主節點匯總結果並執行最終推理或驗收檢查。
何時使用: 複雜任務需要偶爾進行前沿推理(例如設計、策略決策),但需要大量例行執行。 Anthropic 明確推薦這種高效能模式。
2)任務農場/工人池
運作方式: 一組相同的 Haiku 工作器從佇列中提取任務並獨立運作。協調器監控進度並重新分配失敗的任務。
何時使用: 高吞吐量工作負載,例如批次文件摘要、資料集標記或跨多個程式碼路徑執行單元測試。此模式充分利用了 Haiku 的速度和低成本。
3)管道(分階段轉換)
運作方式: 資料流經有序的階段-例如,資料收集 → 規範化(俳句)→ 豐富(外部工具)→ 合成(十四行詩)。每個階段都很小,各有專長。
何時使用: 多步驟 ETL 或內容生成,其中不同的模型/工具適用於不同的階段。
4)MapReduce/MapMerge
運作方式: Map:多個 Haiku 工作器處理不同的輸入分片。 Reduce:協調器(或更強大的模型)合併並解決衝突。
何時使用: 大型文本語料庫分析、大規模問答或多文檔合成。當您希望保留本地編碼以實現可追溯性,但需要偶爾使用更昂貴的模型計算全域摘要或排名時,此功能非常有用。
5)評估循環(QA + 修訂)
運作方式: Haiku 產生一個輸出;另一個 Haiku 工作者或 Sonnet 評估者根據清單對其進行檢查。如果輸出失敗,則循環傳回。
何時使用: 品質敏感的任務,其中迭代細化比僅使用前沿模型更便宜。
系統架構:務實 代理編碼 使用 Haiku 進行設置
緊湊的參考架構(組件):
- API 網關/邊緣: 接收使用者請求;進行授權/速率限制。
- 預處理器(俳句): 清理、規範化、提取結構化字段,並返回編碼的任務對象(JSON)— 代理編碼.
- Orchestrator(Sonnet/更高級的車型或輕量級規則引擎): 使用編碼任務並決定產生哪些子任務,或是否處理請求本身。
- 工作池(Haiku 實例): 並行 Haiku 代理執行指派的子任務(搜尋、總結、產生程式碼、簡單工具呼叫)。
- 評估器/品質門(十四行詩或俳句): 驗證輸出並在必要時請求改進。
- 工具層: 連接到資料庫、搜尋、程式碼執行沙箱或外部 API。
Haiku 4.5 改進了「子代理編排」行為,使其非常適合這種組合:其響應速度和成本特性允許運行多個並發工作器,以並行探索不同的實現。此設定將 Haiku 視為 快速代理編碼器和執行器,減少延遲和成本,同時保留 Sonnet 進行重量級規劃/評估。
工具和計算考慮因素
- 沙盒計算機使用:為代理程式提供受控的 shell 或容器化環境,用於運行測試和建置工件。限製網路存取並僅掛載必要的程式碼庫。
- 出處:每個代理操作都應產生簽章日誌和差異,以保持可解釋性並允許回溯。
- 排比:啟動多個工作者可以增加覆蓋範圍(不同的實作),但需要協調以協調衝突的修補程式。
- 資源預算:使用 Haiku 4.5 進行「內部循環」(快速迭代),並在必要時保留較重的模型以進行最終程式碼審查或架構分析。
工具包裝器和功能適配器
切勿將原始系統 API 直接暴露給模型提示。請將工具封裝在功能狹窄、明確的轉接器中,以驗證輸入並淨化輸出。適配器職責範例:
- 驗證允許操作的命令
- 執行資源/時間限制
- 將低階錯誤轉換為評估器所需的結構化 JSON
最小工作範例 — Python(非同步)
下面是一個最小的, 實際的 Python 範例示範 層次模式:Sonnet 作為規劃器,Haiku workers 作為執行器。它使用官方 Anthropic Python SDK 進行訊息傳遞呼叫(請參閱 SDK 文件)。替換 ANTHROPIC_API_KEY 與您的環境變數一起使用。您也可以使用 CometAPI 的 API: 克勞德俳句 4.5 API 克勞德十四行詩 4.5 APICometAPI呼叫價格為官方價格的20折。 CometAPI呼叫價格為官方價格的20折。您只需將Key替換為 您獲得的 CometAPI KEY 打電話。
注意:為了清晰起見,本範例特意設計得比較短,並且混合了同步/非同步。在生產環境中,您將新增強大的錯誤處理、重試、機密管理和任務佇列(例如 Redis/RQ、Celery 或 AWS SQS)。
# minimal_haiku_orchestrator.py
# Requires: pip install anthropic aiohttp asyncio
import os
import asyncio
from anthropic import AsyncAnthropic
ANTHROPIC_KEY = os.environ.get("ANTHROPIC_API_KEY")
if not ANTHROPIC_KEY:
raise RuntimeError("Set ANTHROPIC_API_KEY in env")
# Model names (adjust if Anthropic changes exact IDs)
PLANNER_MODEL = "claude-sonnet-4-5-20250929" # high-capability planner
WORKER_MODEL = "claude-haiku-4-5" # fast, cheap worker
client = AsyncAnthropic(api_key=ANTHROPIC_KEY)
async def plan(user_request: str) -> list:
prompt = f"""You are a planner. Break the user's request into an ordered list of small executable steps.
User request: \"\"\"{user_request}\"\"\"
Return JSON array of step objects with "id" and "instruction"."""
resp = await client.messages.create(
model=PLANNER_MODEL,
messages=,
max_tokens=800,
)
text = resp.content.strip()
# naive parse: planner is expected to return JSON
import json
try:
steps = json.loads(text)
except Exception:
# fallback: ask Haiku to reformat if planner returned text
steps = [{"id": i+1, "instruction": line.strip()}
for i, line in enumerate(text.splitlines()) if line.strip()]
return steps
async def worker_execute(step):
# Haiku-heavy fast worker; returns a dict with result and metadata
system = f"You are a fast worker. Execute this single instruction and return JSON with fields: id, output, status."
prompt = f"Instruction: {step}\nReturn JSON with fields: id, output, status"
resp = await client.messages.create(
model=WORKER_MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": prompt},
],
max_tokens=512,
)
# parse one-line JSON or fallback to raw
import json
txt = resp.content.strip()
try:
data = json.loads(txt)
except Exception:
data = {"id": step, "output": txt, "status": "ok"}
return data
async def evaluate_and_merge(results):
# Use Sonnet again to do final synthesis/QA
combined = "\n\n".join(} -> {r.get('output','')}" for r in results])
prompt = f"Given the partial results below, produce a concise final answer and mark pass/fail if any step failed.\n\n{combined}"
resp = await client.messages.create(
model=PLANNER_MODEL,
messages=,
max_tokens=600,
)
return resp.content.strip()
async def orchestrate(user_request: str):
steps = await plan(user_request)
# run workers in parallel (bounded parallelism recommended)
sem = asyncio.Semaphore(8) # at most 8 concurrent Haiku workers
async def guarded(step):
async with sem:
return await worker_execute(step)
results = await asyncio.gather(*)
final = await evaluate_and_merge(results)
return final
if __name__ == "__main__":
import sys
req = " ".join(sys.argv) or "Summarize the latest design doc and list 5 follow-ups."
out = asyncio.run(orchestrate(req))
print("FINAL OUTPUT:\n", out)
簡而言之,它的作用是:
Sonnet 負責規劃工作(JSON 步驟)。 Haiku 並發運行每個步驟。然後,Sonnet 會合成/驗證結果。這是規範的 計劃人員→工作人員→評估人員 循環。程式碼使用 Anthropic Python SDK (anthropic),其範例和非同步客戶端顯示相同 messages.create 接口。
如何存取 Claude Haiku 4.5 API
CometAPI 是一個統一的 API 平台,它將來自領先供應商(例如 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等)的 500 多個 AI 模型聚合到一個開發者友好的介面中。透過提供一致的身份驗證、請求格式和回應處理,CometAPI 顯著簡化了將 AI 功能整合到您的應用程式中的過程。無論您是建立聊天機器人、影像產生器、音樂作曲家,還是資料驅動的分析流程,CometAPI 都能讓您更快地迭代、控製成本,並保持與供應商的兼容性——同時也能充分利用整個 AI 生態系統的最新突破。
開發人員可以訪問 克勞德俳句 4.5 API 透過 CometAPI, 最新型號版本 始終與官方網站同步更新。首先,探索該模型的功能 游乐场 並諮詢 API指南 以獲得詳細說明。造訪前請確保您已經登入CometAPI並取得API金鑰。 彗星API 提供遠低於官方價格的價格,幫助您整合。
準備出發了嗎? → 立即註冊 CometAPI !
如果您想了解更多有關 AI 的提示、指南和新聞,請關注我們 VK, X 不和!
結論
運用 克勞德俳句 4.5 作為快速代理編碼器/工作器,可以解鎖低延遲、經濟高效的多智能體系統。實際的模式是讓更強大的模型進行編排和評估,同時讓數千個 Haiku 工作器並行執行日常繁重的工作。上面的最小 Python 範例應該可以幫助您入門——您可以根據自己的生產佇列、監控和工具集進行調整,以建立強大、安全且可擴展的代理管道。