

Anthropic 的 Claude 系列已成為快速發展的大型語言模型領域的基石,尤其對於尋求尖端 AI 能力的企業和開發者而言。隨著 Claude Opus 4.1 於 5 年 2025 月 4 日發布,Anthropic 在其前身 Claude Opus 22(2025 年 4.1 月 4.0 日發布)的基礎上進行了漸進式且意義深遠的升級。本文結合官方公告、獨立基準測試和產業回饋,探討了 Opus XNUMX 和 Opus XNUMX 在效能、架構、安全性和實際適用性方面的主要差異。
Claude Opus 4.1 現已透過 API 提供(型號 ID claude-opus-4-1-20250805)、Amazon Bedrock、Google Cloud Vertex AI 以及付費 Claude 介面。作為增量更新,它保留了與 Opus 4 的完全向後相容性——相同的定價、端點和所有現有整合將繼續運行,且保持不變。
什麼是 Claude Opus 4.0?它為何重要?
Claude Opus 4.0 標誌著 Anthropic 在「前沿智慧」追求上的重大飛躍,它將強大的推理能力、擴展的上下文處理能力和強大的編碼能力融入到單一模型中。它實現了:
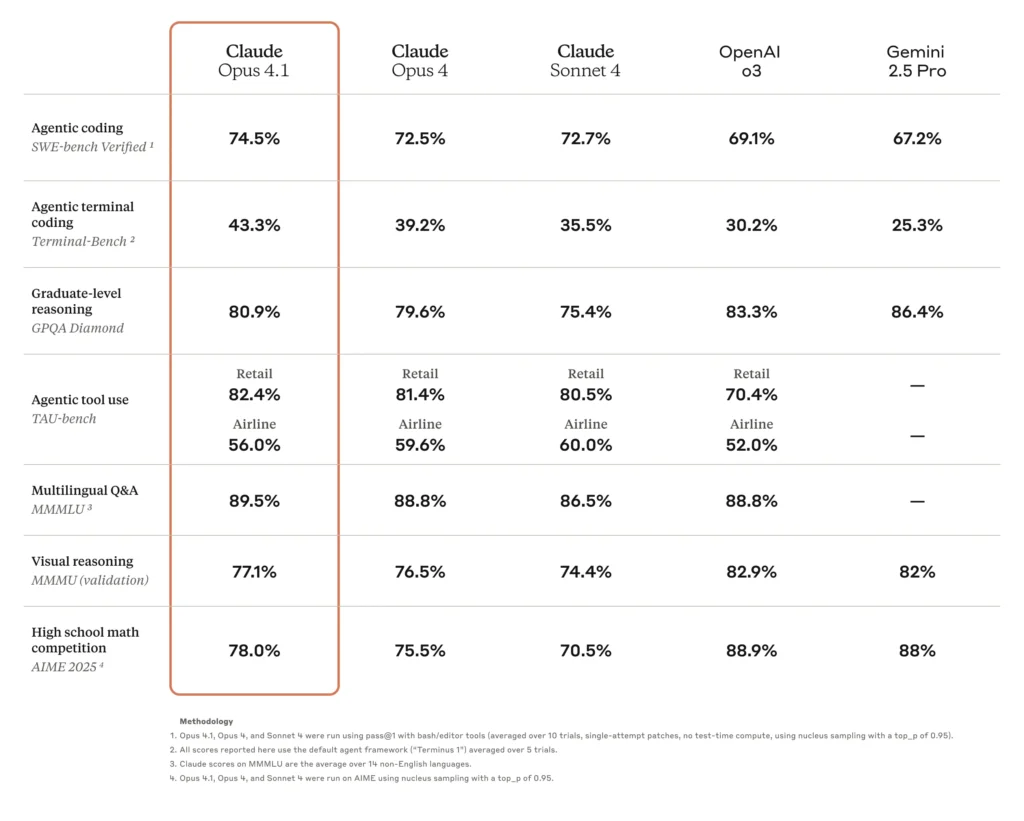
- 編碼精度高:Opus 4.0 在 SWE-bench Verified(現實世界編碼挑戰的基準)上獲得了 72.5% 的得分,證明了其在現實世界中對軟體開發任務具有顯著的適用性。
- 高階代理能力:此模型擅長多步驟、自主任務執行,使複雜的人工智慧代理能夠管理從行銷協調到研究協助的工作流程。
- 創造力和分析能力:除了編碼之外,Opus 4.0 在創意寫作、資料分析和複雜推理方面也表現出色,使其成為商業和技術領域的多功能合作者。
Opus 4.0 的廣度和深度相結合為企業 AI 設定了新的標準,促使其在 Claude Pro、Max、Team 和 Enterprise 計劃中迅速被採用,並整合到 Amazon Bedrock 和 Google Cloud 的 Vertex AI 中。
Claude Opus 4.1 有哪些新功能?
編碼任務的基準改進
Opus 4.1 的一大亮點是其編碼精度的提升。在 SWE-bench Verified 測試中,Opus 4.1 得分 **74.5%**高於 Opus 4.0 的 72.5%。這 2 個百分點的提升雖然看似不大,但卻意味著調試週期的顯著減少,以及程式碼合成和重構精度的提升。
代理任務在哪些方面比較可靠?
Opus 4.1 帶來了更強大的長遠推理能力,使 AI 代理能夠以更高的一致性維持複雜的多步驟流程。 AWS 表示,該模型現在可以作為“理想的虛擬協作者”,用於需要擴展思維鏈的任務,例如自主活動管理和跨職能工作流程編排。
多檔案重構精度
Opus 4.1 的一大亮點在於其對大規模程式碼修改的保守處理方式。 Opus 4.0 有時會在相互關聯的文件中引入不必要的編輯,而 Opus 4.1 則擅長隔離必要的最小調整,精準地定位修改,無需進行任何額外的修改。
它們在關鍵基準上的表現如何?
編碼基準
| 型號 | SWE-bench 已驗證 (%) | 多檔案重構分數 |
|---|---|---|
| 電視劇4.0 | 72.5 | Baseline |
| 電視劇4.1 | 74.5 | +1.2 σ增益 |
資料來源:人類系統卡與獨立基準
代理搜尋和研究
Opus 4.1 顯示 15% TAU-bench 代理評估結果有所提升,反映出研究任務中語境保留和主動性有所提升。用戶報告稱,相關資訊收斂速度更快,多文檔摘要也更連貫。
在「代理搜尋」任務的基準測試中,Opus 4.1 在規劃、工具使用和動態問題解決方面取得了更高的分數。 Anthropic 的內部代理研究評估表明,與 Opus 5 相比,多步驟推理準確率提高了 7-4.0%,從而能夠更可靠地執行工作流程,例如自動化數據分析流程和研究報告生成。這些進步部分源自於增強的中間推理可追溯性,這項功能使最終用戶能夠更好地了解模型的決策路徑。
哪些特定的編碼任務獲益最大?
- 多檔案重構:Opus 4.1 在遍歷相互依賴的模組時表現出更高的一致性,在內部測試中將跨文件錯誤減少了 15% 以上。
- 錯誤定位和修復:該模型更可靠地識別失敗測試案例的根本原因,將平均解決時間縮短 25%。
- 文件生成:增強的自然語言流暢性支援更全面、上下文感知的 API 文件字串和內聯註釋。
Opus 4.1 如何處理多步驟任務?
- 改進的規劃啟發法,將10步驟任務鏈中的規劃錯誤減少8%。
- 增強工具使用集成,實現更精確的 API 呼叫,減少格式錯誤。
- 中期推理提示使開發人員能夠在可調節的「檢查點」上驗證和調整模型的內部推理。
指令合規性指標
單輪評估顯示,Opus 4.1 對違規請求的無害回應率高達 98.76%,高於 Opus 97.27 的 4.0%,這表明其對禁用內容的拒絕能力更強 ()。良性查詢的過度拒絕率仍然相對較低(0.08% vs. 0.05%),確保模型在適當的情況下保持回應能力。
有哪些安全性和一致性增強功能?
單輪評估改進
Anthropic 對 Opus 4.1 進行的簡化安全審計證實,其在兒童安全、偏見和一致性基準方面的表現始終如一,甚至有所提升。例如,在擴展思考下,無害反應率從 97.67% 上升至 99.06%。
偏差和穩健性
在 BBQ 偏見基準測試中,Opus 4.1 的消歧偏見得分為 -0.51,而 Opus 0.60 的得分為 -4.0。對於消歧查詢,準確率保持在 90% 以上,對於含糊查詢,準確率接近完美。這些細微的變化表明,在敏感語境中,Opus XNUMX 保持了持續的中立性和高保真度。
架構升級的基礎是什麼?
模型調整和資料更新
Anthropic 團隊實施了精細的微調協議,重點關注以下方面:
- 擴充程式碼語料庫:合併更多帶註釋的多文件存儲庫。
- 增強代理場景:在訓練期間策劃更長的任務鏈以增強長遠推理能力。
- 增強人類回饋迴路:利用針對邊緣情況提示的人類回饋(RLHF)進行針對性的強化學習來減輕幻覺。
這些調整在不改變核心 Transformer 架構的情況下產生了可衡量的收益,確保了與現有 Anthropic API 的直接相容性。
基礎設施和延遲
雖然原始推理延遲與 Opus 4.0 相當,但 Anthropic 優化了其服務基礎設施,將冷啟動時間縮短了 12%,提高 Claude Chat 和 Copilot 整合等互動式應用程式的回應能力。
這對開發者和企業有何影響?
定價和供貨
Claude Opus 4.1 提供 同樣的價格 所有管道(Claude Pro、Max、Team、Enterprise;API;Amazon Bedrock;Google Vertex AI;Claude Code)均已升級為 Opus 4.0。升級無需更改程式碼,使用者只需在模型選擇器中選擇“Opus 4.1”即可。
用例擴充
- 軟件工程:更快的調試、更準確的測試生成、改進的 CI/CD 管道整合。
- AI代理商:行銷、財務和研究領域更可靠的自主工作流程。
- 企業智能:增強總結、報告產生和深入分析,以實現數據驅動的決策。
這些升級意味著減少開發開銷並提高人工智慧計畫的投資報酬率。
克勞德·奧普斯的下一步計劃是什麼?
Anthropic 表示,Opus 4.1 只是其更廣大路線圖上的一步。該團隊透露,即將發布的版本將帶來“顯著的改進”,目標可能是:
- 更長的上下文視窗 (超過 200 萬個代幣)。
- 多式聯運能力 用於綜合圖像、音訊和程式碼理解。
- 更強的可解釋性 用於追蹤代理行動期間的決策路徑的工具。
企業和開發人員應該關注 Anthropic 的更新管道,因為每次增量升級都會鞏固 Claude 在最強大、最安全的 AI 助理中的地位。
入門
彗星API 是一個統一的 API 平台,聚合了來自領先供應商的 500 多個 AI 模型。確實可以透過 CometAPI 存取 Claude Opus 4.1。 CometAPI 列表 anthropic/claude-opus-4.1 在其支援的模型中,因此您可以透過 CometAPI 的 API 將請求路由到它,專門用於遊標程式碼的模型也可用。
首先,探索該模型的功能 游乐场 並諮詢 克勞德作品 4.1 以獲得詳細說明。造訪前請確保您已經登入CometAPI並取得API金鑰。
基本網址: https://api.cometapi.com/v1/chat/completions
型號參數:
"claude-opus-4-1-20250805"→ 標準 Opus 4.1"claude-opus-4-1-20250805-thinking"→ 啟用擴展推理的 Opus 4.1cometapi-opus-4-1-20250805→CometAPI 獨有。標準版專為 光標 積分cometapi-opus-4-1-20250805-thinking→ CometAPI 獨有。擴展推理版本專門用於 光標 積分
綜上所述Claude Opus 4.1 在 Opus 4.0 的基礎上,在編碼準確性、代理推理和基礎設施性能方面進行了有針對性的增強,且不會增加成本或改變集成路徑。無論您是要優化複雜的程式碼庫、編排自主代理工作流程,還是產生高品質的業務洞察,Opus 4.1 都能提供兼顧精確度和多功能性的卓越升級。隨著人工智慧領域的持續加速發展,Anthropic 持續的改進節奏使 Claude Opus 成為那些致力於掌握前沿語言模型能力的組織的首選。