

克勞德十四行詩 4.5 (通常短接至 克勞德 4.5) 是 Anthropic 於 2025 年 9 月 29 日發布的前沿版本,專注於長遠的代理工作、編碼和「電腦使用」(跨工具自動執行多步驟任務)。它在自主編碼時長、工具使用和協同行為方面實現了大幅提升,同時保持與上一版 Sonnet 相同的單幣定價。對於建立代理工作流程、開發人員生產力堆疊和受監管企業應用程式的團隊來說,Claude 4.5 是一個極具吸引力且成本合理的選擇。
事件 克勞德十四行詩 4.5 is
Claude Sonnet 4.5 是 Anthropic 的下一個主要 Claude 模型迭代版本(品牌為「Sonnet 4.5」),旨在運行更長、更複雜的多步驟任務,代表用戶操作軟體工具,並為企業客戶進行生產級編碼和推理。此版本強調代理能力(能夠跨多個步驟和工具自主運行的模型)、更嚴格的一致性/安全性,以及更豐富的應用程式內功能,例如程式碼執行和文件創建(電子表格、投影片、文件)。
關鍵突破和特點
1. 持續、長期運作的代理能力
Anthropic 報告 Claude Sonnet 4.5 可以保持專注、多步驟操作 超過30小時 處理複雜任務—這對於需要人工智慧協調眾多子任務並處理長期不斷變化的環境的工作流程來說是一個重大變革。這對於 Anthropic 所瞄準的「代理」用例至關重要。
2. 最先進的編碼和電腦使用性能
Claude 4.5 在 SWE-Bench Verified(行業編碼基準)上取得了最高成績,並顯示出該模型在實際執行以下任務的能力方面取得了重大進步: 使用電腦 (執行工具呼叫、管理終端/IDE 工作流程、建置應用程式)。人類學和獨立媒體將其描述為編碼任務的領先模型,並在多項軟體工程指標上被評為「世界最佳」。這包括對自主程式碼產生、偵錯和持續程式碼執行會話的改進。
3. 改進的工具編排、上下文管理和內存
為了支援代理長時間運行,Claude Sonnet 4.5 引入了更強大的上下文管理工具(自動「上下文編輯」功能,用於清除過時的工具輸出),以及一個基於檔案的記憶體工具,允許模型跨會話持久化和檢索狀態。這些系統功能可以減少情境膨脹,並幫助代理商在長時間的工作流程中保持「專注於任務」。
4. 更好的系統/作業系統交互
在 Anthropic 描述並由媒體報道的內部測試中,新的 Claude Sonnet 4.5 變體在系統使用基準測試中表現出顯著的提升(例如,Anthropic 報告稱,操作系統基準測試任務的熟練度從約 40% 躍升至約 60%),這意味著該模型在與其他軟體交互的提升。當您希望模型能夠可靠地操作工具(編輯檔案、運行建置、呼叫 API)時,這一點非常有價值。
5. 開發人員工具和集成
Anthropic 正在與 Claude Sonnet 4.5 一起發布面向開發人員的工具:Claude Agent SDK、原生 VS Code 集成、終端/IDE 工作流程以及產品集成,例如推出到 GitHub Copilot(Copilot Pro/Enterprise 預覽版)。這些整合縮短了工程團隊從原型到生產的路徑。
6. 校準和安全改進
Anthropic 稱 Claude Sonnet 4.5 為其發布的「最一致的前沿模型」;它部署在 人工智慧安全等級 3(ASL-3) 保護措施,包括改進的分類器和防禦措施(例如,防止立即註射),並減少了 Anthropic 報告的問題行為。
性能基準-數字的涵義
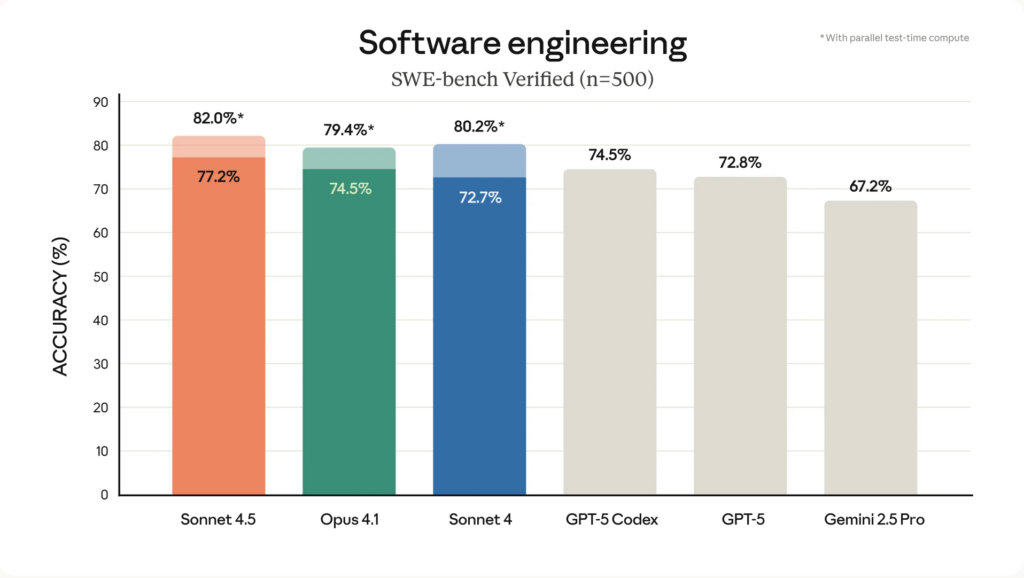
Anthropic 的公告發布了幾項重要數據(SWE-bench、OSWorld、內部終端/代理基準測試)。 Anthropic 發布的主要數據如下:
- SWE-bench 已驗證: 77.2% (200萬思考預算,鷹架+工具); 78.2% 在 1M 上下文中; 82.0% 報告了「高計算」候選人選拔制度。
- OSWorld(電腦任務): 61.4% 對於 Sonnet 4.5 和 42.2% 十四行詩 4(四個月前)。
- 自主長度(內部測試): >30 小時連續自主編碼/代理操作(上一代約 7 小時)。
- 作業系統/工具基準測試: Anthropic 報告稱,在作業系統互動基準測試中,該版本躍升至約 60%,而前代版本則為約 40%——表明模型控制軟體時的可靠性有所提高。
定價(開發者/API)
人類學列出了 十四行詩4.5 開發人員定價與 Sonnet 4 一致: 每百萬輸入代幣 3 美元 每百萬輸出代幣 15 美元 (透過快速快取和批次可獲得標準節省)。 Sonnet 4.5 可透過 Claude API 和 Claude 應用程式取得。企業和大量折扣/產品等級(Pro/Max/Team/Enterprise)可透過 Anthropic 的商業管道取得。
為什麼選擇 Claude Sonnet 4.5?它有哪些亮點?
代理自動化和編排
如果您需要執行長工作流程(數小時/數天)、跨步驟管理記憶體、協調子代理程式或自主操作工具(終端機、Web UI、電子表格)的模型,Sonnet 4.5 對持續一致性和專用 Agent SDK 的關注是一個主要優勢。
生產編碼和開發人員生產力
Anthropic 的基準測試和合作夥伴報告(例如 GitHub Copilot 整合)表明 Sonnet 4.5 可以處理多檔案程式碼庫編輯、測試和長時間調試會話——當開發人員需要一個可以在較少人工提示的情況下進行創作、測試和迭代的助手時,它非常有用。
受監管及企業環境
更強大的一致性和 ASL-3 部署能力,使得 Sonnet 4.5 對需要更高防護措施和記錄安全實踐的金融、法律、安全和醫療團隊極具吸引力。 Anthropic 明確將此模式定位於企業客戶。
成本敏感的生產用途
由於 Sonnet 4.5 保持了 Sonnet 級別的定價(每百萬個令牌約 3 美元/15 美元),因此與一些價格更高的前沿模型相比,高負載代理工作負載的成本/性能權衡看起來更有利——尤其是當你考慮到即時緩存和其他平台優化時
若出現以下情況,請考慮替代方案:
- 對於基本問答系統,您的首要任務是實現盡可能低的延遲或最便宜的每令牌推理;對於簡單的工作負載,更輕量級的模型或其他供應商的精簡模型可能更便宜/更快。 (定價和成本結構各不相同;比較每令牌輸出定價和快取策略。)
何時選擇 Claude Sonnet 4.5 — 實用指南
若符合下列條件,請選擇 Claude Sonnet 4.5:
- 你需要法學碩士學位 操作工具 在長序列上可靠地執行(代理編排、自動化管道、自主助手)。
- 您的主要工作量是 大規模軟體工程 (自動編碼、長時間偵錯會話、持續整合任務)—據報道,Sonnet 4.5 在 SWE-Bench 和相關程式碼基準測試中表現出色。
- 您在受監管或高風險領域(法律、金融、安全)工作,需要一個經過調整以實現更可預測、更可審計的行為和更安全的輸出的模型。 Anthropic 強調企業的可靠性和安全性。
若出現以下情況,請考慮替代方案:
對於基本問答系統,您的首要任務是實現盡可能低的延遲或最便宜的每令牌推理;對於簡單的工作負載,更輕量級的模型或其他供應商的精簡模型可能更便宜/更快。 (定價和成本結構各不相同;比較每令牌輸出定價和快取策略。)
如何訪問克勞德桑奈特 4.5
CometAPI 是一個統一的 API 平台,它將來自領先供應商(例如 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等)的 500 多個 AI 模型聚合到一個開發者友好的介面中。透過提供一致的身份驗證、請求格式和回應處理,CometAPI 顯著簡化了將 AI 功能整合到您的應用程式中的過程。無論您是建立聊天機器人、影像產生器、音樂作曲家,還是資料驅動的分析流程,CometAPI 都能讓您更快地迭代、控製成本,並保持與供應商的兼容性——同時也能充分利用整個 AI 生態系統的最新突破。
開發人員可以訪問 克勞德十四行詩 4.5 克勞德十四行詩 4 透過 CometAPI, 最新型號版本 始終與官方網站同步更新。首先,探索該模型的功能 游乐场 並諮詢 API指南 以獲得詳細說明。造訪前請確保您已經登入CometAPI並取得API金鑰。 彗星API 提供遠低於官方價格的價格,幫助您整合。
準備出發了嗎? → 立即註冊 CometAPI !
結論
Claude Sonnet 4.5 是一個有針對性的進化:它不僅僅是「聊天能力更強一點」。 Anthropic 將它設計成一個 可靠的代理建構器 它可以長時間執行任務,協調工具和程式碼,並處理領域繁重的工作流程(法律、財務、網路安全和工程)。如果您的生產用例需要強大的工具編排、擴展的上下文穩定性和頂級的編碼效能,並且您希望保持可預測的每代幣定價,那麼 Claude 4.5 值得在您的環境中進行正式的技術試用。