
Gemini 2.5 Flash API 是 Google 最新的多模態 AI 模型,專為高速、經濟高效的任務而設計,具有可控的推理能力,允許開發人員透過 Gemini API 開啟或關閉高級「思考」功能。最新模型是 gemini-2.5-flash.
Gemini 2.5 Flash 概述
Gemini 2.5 Flash 旨在提供快速響應,同時不影響輸出品質。它支援多模式輸入,包括文字、圖像、音頻和視頻,適用於各種應用。該模型可透過 Google AI Studio 和 Vertex AI 等平台訪問,為開發人員提供無縫整合到各種系統所需的工具。
基本資訊(特徵)
Gemini 2.5 Flash 引入了幾個突出的 功能 在 Gemini 2.5 系列中脫穎而出:
- 混合推理:開發人員可以設定 思考預算 參數來精細控制模型在輸出之前用於內部推理的標記數量。
- 帕累托前沿:位於 最佳性價比點在 2.5 款機種中,Flash 提供了最佳的性價比。
- 多式聯運支援:流程 文本, 圖片, 視頻和 音頻 原生地實現更豐富的對話和分析能力。
- 1 萬個令牌上下文:無與倫比的上下文長度允許在單一請求中進行深入分析和長文件理解。
模型版本控制
Gemini 2.5 Flash 已通過以下關鍵 版本:
- gemini-2.5-flash-lite-preview-09-2025:增強工具易用性:提升複雜、多步驟任務的效能,SWE-Bench Verified 分數提升 5%(從 48.9% 提升至 54%)。提升效率:啟用推理功能時,可以使用更少的 token 獲得更高品質的輸出,從而降低延遲和成本。
- 預覽 04-17:具有「思考」功能的早期版本,可透過以下方式取得 gemini-2.5-flash-預覽-04-17.
- 穩定通用版本 (GA):截至 17 年 2025 月 XNUMX 日,穩定端點 gemini-2.5-flash 取代預覽版,確保生產級可靠性,且與 20 月 XNUMX 日預覽版相比 API 沒有任何變化。
- 預覽版棄用:預覽端點計畫於 15 年 2025 月 XNUMX 日關閉;使用者必須在此日期之前遷移到 GA 端點。
截至 2025 年 2.5 月,Gemini XNUMX Flash 現已公開發布且穩定(與 gemini-2.5-flash-預覽-05-20 )。如果您使用 gemini-2.5-flash-preview-04-17,現有預覽版定價將持續到 15 年 2025 月 XNUMX 日模型端點計畫停用(屆時將關閉)。您可以遷移到正式發布的模型“gemini-2.5-flash“。
更快、更便宜、更聰明:
- 設計目標:低延遲+高吞吐量+低成本;
- 推理、多模式處理和長文本任務的整體加速;
- Token使用量減少20–30%,大幅降低推理成本。
技術規格
輸入上下文視窗:最多 1 萬個標記,允許廣泛的上下文保留。
輸出令牌:每次回應最多可產生 8,192 個令牌。
支援的形式:文字、圖像、音訊和視訊。
整合平台:可透過 Google AI Studio 和 Vertex AI 取得。
定價:基於代幣的競爭性定價模式,促進具有成本效益的部署。
技術細節
Gemini 2.5 Flash 的底層是 基於變壓器的 基於網路、程式碼、圖像和視訊資料混合訓練的大型語言模型。關鍵 技術 規格包括:
多模式訓練:經過訓練可以對齊多種模式,Flash 可以無縫地將文字與 圖片, 視頻, 或者 音頻,對於視訊摘要或音訊字幕等任務很有用。
動態思維過程:實作內部推理循環,其中模型 計劃 分解複雜的提示 最終輸出之前。
可配置思維預算:“ 思考預算 可以從 0 (無需推理)最多 24,576令牌,允許在延遲和答案品質之間進行權衡。
工具集成:支持 Google 搜尋基礎, 代碼執行, URL 上下文和 函數呼叫,直接從自然語言提示實現現實世界的操作。
基準性能
在嚴格的評估中,Gemini 2.5 Flash 表現出 行業領先 性能:
- LMArena 硬提示:得分 僅次於 2.5 Pro 在具有挑戰性的 Hard Prompts 基準測試中,展現了強大的多步驟推理能力。
- MMLU分數為0.809:超過平均模型性能 0.809 MMLU 的準確性,反映了其廣泛的領域知識和推理能力。
- 延遲和吞吐量:實現 271.4 個令牌/秒 解碼速度 0.29 秒第一個令牌時間,使其成為延遲敏感型工作負載的理想選擇。
- 性價比領導者:在 $0.26/1萬代幣,Flash 在關鍵基準上與許多競爭對手匹敵甚至超越它們,同時削弱了它們。
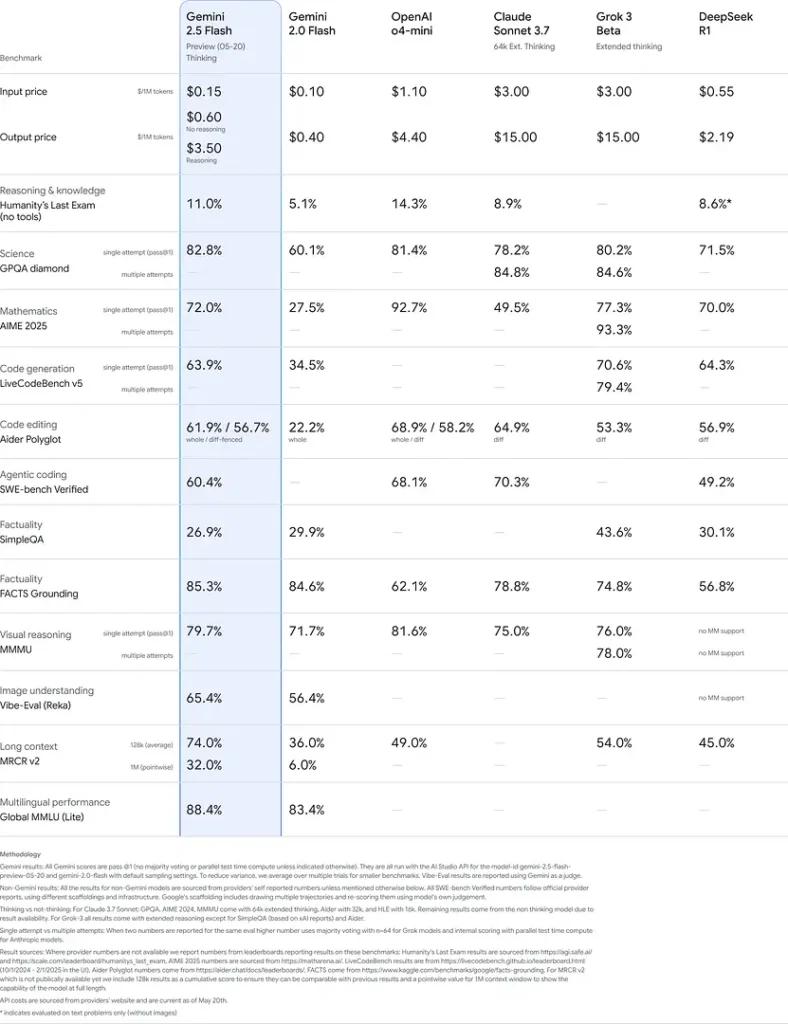
這些結果表明 Gemini 2.5 Flash 在推理、科學理解、數學問題解決、編碼、視覺解釋和多語言能力方面具有競爭優勢:
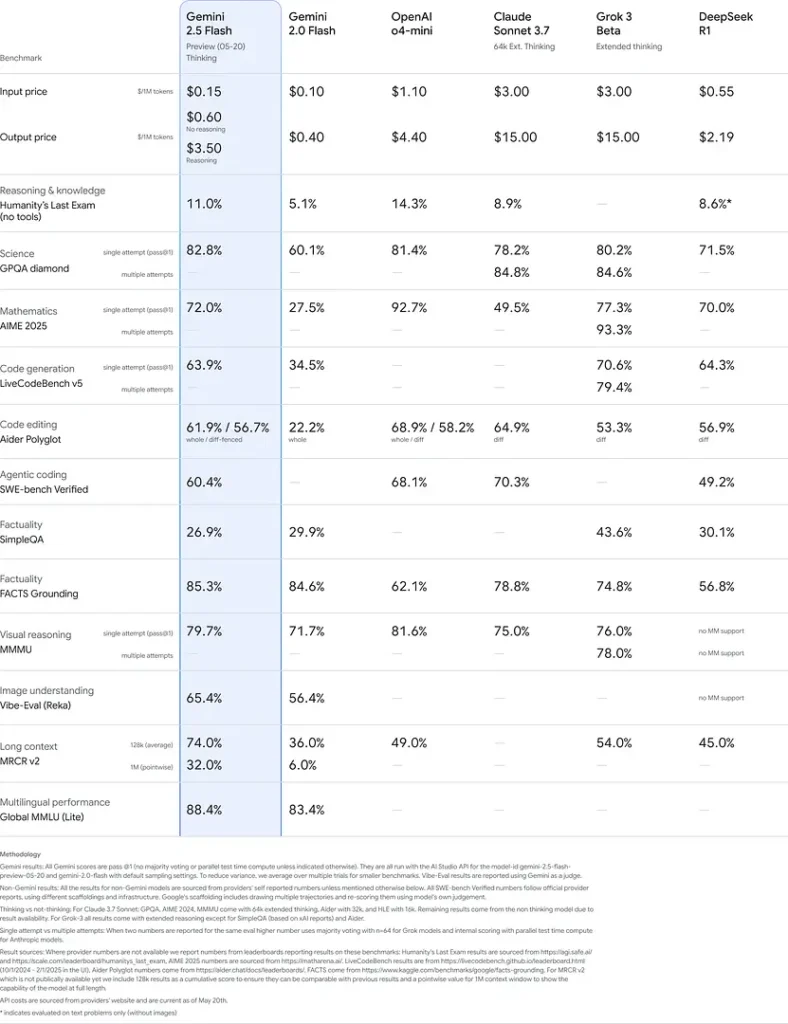
限制
Gemini 2.5 Flash 雖然功能強大,但還是存在一些 限制:
- 安全風險:該模型可以展示 “說教”語氣 並且可能會產生看似合理,但實際上不正確或有偏差的輸出(幻覺),尤其是在處理邊緣查詢時。嚴格的人工監督仍然至關重要。
- 速率限制:API 使用受到速率限制(預設層級上為 10 RPM、250,000 TPM、250 RPD)的約束,這可能會影響批次或大容量應用程式。
- 智慧樓層: 雖然對於 閃光 模型,其準確率仍低於 2.5臨 在最苛刻的代理任務上,如高級編碼或多代理協調。
- 成本權衡:雖然提供最好的 性價比,廣泛使用 思維 模式增加了整體代幣消耗,並提高了深度推理提示的成本。
結論
Gemini 2.5 Flash 證明了 Google 致力於推動人工智慧技術的承諾。憑藉其強大的性能、多模式功能和高效的資源管理,它為尋求在營運中利用人工智慧力量的開發人員和組織提供了全面的解決方案。
如何致電 Gemini 2.5 Flash 來自 CometAPI 的 API
Gemini 2.5 Flash CometAPI 中的 API 定價,比官方價格便宜 20%:
- 輸入代幣:0.24 美元/百萬個代幣
- 輸出代幣:0.96 美元/百萬代幣
所需步驟
- 登錄到 cometapi.com。如果您還不是我們的用戶,請先註冊
- 取得介面的存取憑證API key。在個人中心的API token處點選“新增Token”,取得Token金鑰:sk-xxxxx並提交。
- 取得此網站的 URL: https://api.cometapi.com/
使用方法
- 選擇“
gemini-2.5-flash「端點發送 API 請求並設定請求體。請求方法和請求體可從我們網站的 API 文件取得。為了方便您使用,我們網站也提供了 Apifox 測試。 - 代替使用您帳戶中的實際 CometAPI 金鑰。
- 將您的問題或請求插入內容欄位 - 這是模型將會回應的內容。
- 。處理 API 回應以取得產生的答案。
有關 Comet API 中的模型啟動信息,請參閱 https://api.cometapi.com/new-model.
有關 Comet API 中的模型價格信息,請參閱 https://api.cometapi.com/pricing.
API 使用範例
開發人員可以與 gemini-2.5-flash 透過CometAPI的API,可以整合到各種應用程式中。下面是一個 Python 範例:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
此腳本向 Gemini 2.5 Flash 模型並列印產生的回應,示範如何利用 Gemini 2.5 Flash 以獲得複雜的解釋。