

Google 及其研究部門 DeepMind 已經悄然(接著不再那麼悄然)在 Gemini 路線圖上推進了另一個重大步驟:Gemini 3.1 Pro。這次發佈透過面向消費者的介面 CometAPI 推出,定位為 Gemini 3 系列的性能與推理升級——承諾顯著更強的長篇推理能力、改進的多模態理解,以及更佳的可擴展性以適配真實世界的應用。
Google 最新的模型——什麼是 Gemini 3.1 Pro?
Gemini 3.1 Pro 是 Gemini 3 系列中的首個增量更新,定位為「最強能力」的推理模型,針對多步驟、多模態與代理(agentic)任務進行優化。該模型於 2026 年 2 月中旬進入公開預覽(預覽於 2026 年 2 月 19–20 日宣佈),明確瞄準需要持續思維鏈、工具使用與長上下文理解的場景——例如:大規模研究綜合、協調工具與系統的工程代理,以及混合文本、圖像、音訊與影片的多模態文件分析。
從高層概述,開發者將 Gemini 3.1 Pro描述為:
- 天生具備多模態能力——能夠接收並推理文本、圖像、音訊與影片。
- 為長上下文而建——支援超大上下文窗口,適合整個程式碼庫、多文件資料集或長篇逐字稿。
- 針對可靠推理與代理工作流程進行優化,意味著它能在多步任務中進行規劃、呼叫工具並驗證輸出。
為何此刻重要:組織與開發者正在從「良好的對話助手」轉向「高風險的決策支援與研究代理」(法律撰寫、研發綜合、多模態文件理解)。Gemini 3.1 Pro 就是為此通道而設計——以降低幻覺、產生可追溯的推理,並與 CometAPI 整合以同時支持原型與生產。
Gemini 3.1 Pro 的技術亮點與功能有哪些?
原生多模態與極致上下文窗口
Gemini 3.1 Pro 延續 Gemini 系列對多模態的聚焦。根據模型卡與產品說明,該模型在同一管線中接收並推理文本、圖像、音訊與影片——此能力簡化了數據類型混合的工作流程(例如同時包含音訊+逐字稿+掃描件的法律證詞)。值得注意的是,模型支援1,000,000 個 token的上下文窗口,且可生成長輸出(已發佈的說明表示輸出上限非常大,適合長篇任務)。此規模使其適用於分析整個程式碼倉庫、多章節文件或長篇逐字稿而無需切分。
###「動態思考」:改進的推理與逐步規劃
Google 表示 3.1 Pro 的「思考」有所提升——也就是更好的內部思維鏈處理,並能依據任務複雜度動態選擇推理策略。模型在需要時會啟動顯式的多步規劃,且在此過程中保持 token 使用效率。實務上,這轉化為在複雜、逐步的問題上更少幻覺,並在多步推理基準上提高事實一致性。
代理工作流程與工具使用
3.1 Pro 的主要設計重點之一是代理性能:協調工具、啟用網絡錨定或搜尋、撰寫與執行程式碼片段,並透過二次檢查來驗證輸出。Google 已將 3.1 Pro 整合到以代理為先的產品中(例如 Antigravity 開發環境),讓模型能運行涉及編輯器、終端與瀏覽器的任務——並記錄螢幕截圖與瀏覽器錄影等工件以驗證進度。這些功能旨在縮小「提供建議」的模型與能可靠執行多工具工作流程的模型之間的差距。
專用子模式(Deep Research、Deep Think)
Google 為 3.1 Pro 配對了「Deep Research」,並提及即將推出的「Deep Think」變體。這些子模式分別針對高召回的研究任務與最大推理深度(需要額外運算成本與延遲)。它們旨在服務需要更審慎、更高品質輸出而非最快、最便宜回應的分析師、研究人員與開發者。
Gemini 3.1 Pro 在基準測試上的表現如何?
Gemini 3.1 Pro 相較先前的 Gemini 3 Pro 結果取得強勁提升,經常在多步推理與多模態的廣泛指標上領先——但在某些專門任務上仍落後於部分競品(尤其是特定高階編碼或專家級問題集)。簡言之:在專項基準上呈現整體提升、少數對手具狹窄優勢。
主要基準主張與重點數字
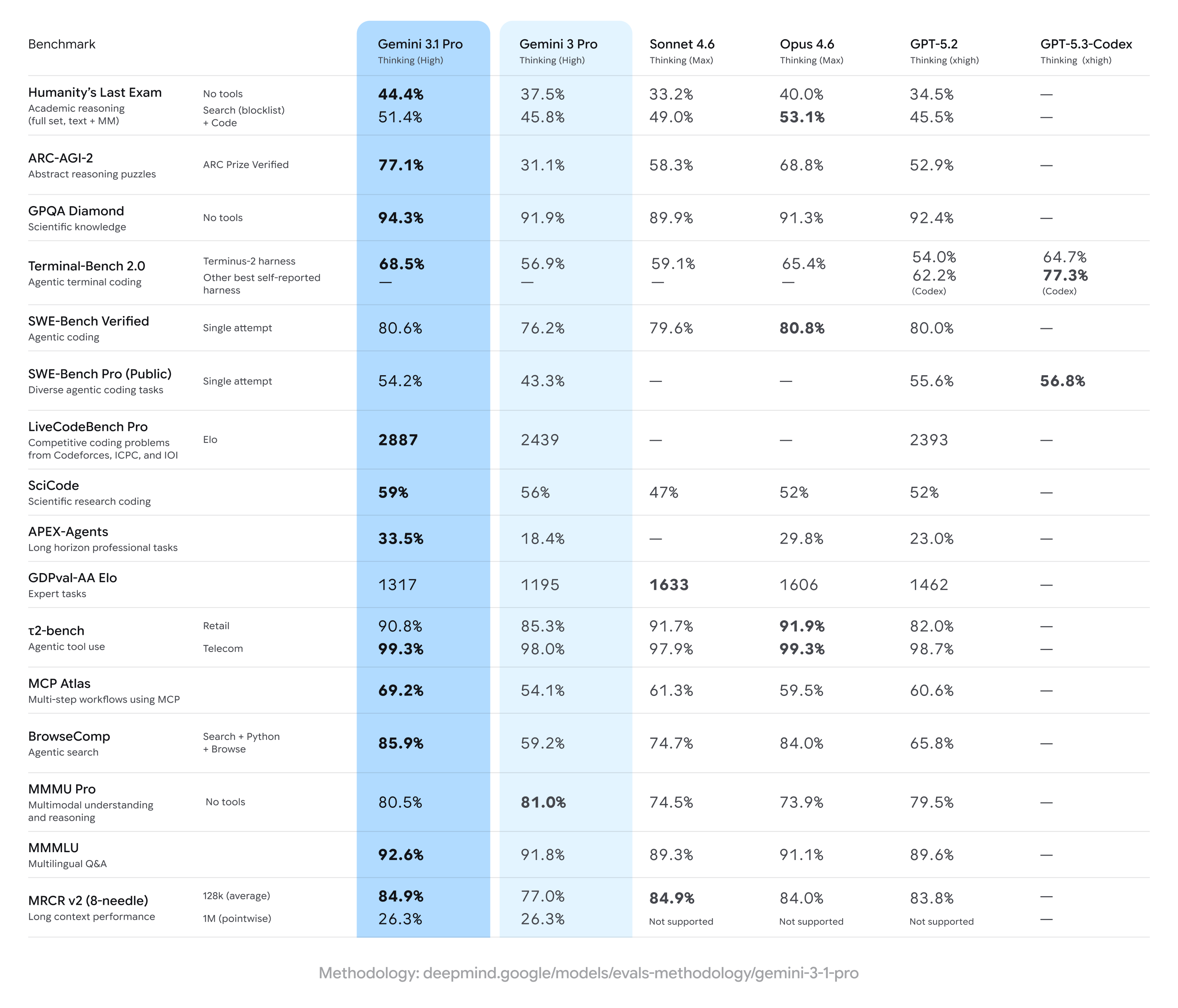
- ARC-AGI-2(抽象推理/多步科學謎題): 報告顯示 Gemini 3.1 Pro 相比先前的 Gemini 3 Pro 版本有大幅提升;某社群測試套件在短且聚焦的測試中指示相較前代基準達到超過兩倍的改善。具體報告(社群測試)將 Gemini 3.1 Pro 在部分 ARC 風格匯總上置於約77.1%(公開報告)。
- GPQA Diamond 與研究所層級科學基準: 報告數據顯示 Gemini 3.1 Pro 在 GPQA Diamond(研究所層級的科學問答基準)上創下新高,超越早期 Gemini 模型,並在獨立執行中為該系列設定了新的高水位。這些增益反映模型在思維鏈與逐步推理調校上的改進。
- 「Humanity’s Last Exam」在工具啟用情境(多工具、錨定推理): 與 Anthropic 的 Claude Opus 4.6 的正面比較中,Claude 在這個複雜的工具啟用基準上取得53.1%,而 Gemini 3.1 Pro 在同輪測試中達到51.4%——顯示 Gemini 緊追在後,但在該特定多工具考核上並非居首。
- 編碼與終端基準(Terminal-Bench 2.0、SWE-Bench Pro): 專業編碼基準顯示更大差異。在使用特定框架的 Terminal-Bench 2.0 中,GPT-5.3-Codex 變體約得分 77.3%,相比之下 Gemini 3.1 Pro 約為 ~68.5%。在 SWE-Bench Pro 的公開結果中,Gemini 3.1 Pro 約為 ~54.2%,而 GPT-5.3-Codex 為 56.8%——差距較小,但在那些執行中 OpenAI 的 Codex 家族在專門程式任務上仍保有優勢。
- GDPval-AA Elo(專家任務評級): 在針對專家任務的 Elo 式聚合排名中,Claude Sonnet/Opus 變體得分更高(例如 ~1606–1633 點),而某公開報告將 Gemini 3.1 Pro 在同一數據集上置於 ~1317 點——顯示在特定狹窄的專家領域仍有改進空間。
真實世界試用結果與實測
分析師親測的寫作表明,Gemini 3.1 Pro 尤其擅長:
- 長上下文摘要與多文件綜合,1M token 窗口避免了易產生瑕疵的切分。
- 多模態理解任務,其中圖像+文本的錨定提升了事實抽取的準確性。
- 代理式自動化(例如協調簡單工具鏈)——在 Antigravity 的試用中展示出多代理任務編排可行,且能以工件記錄每一步。
Gemini 3.1 Pro 仍落後之處(數字所指)
沒有任何模型在各方面都最佳。獨立評論與社群測試突顯了特定差距:
- 軟體工程與程式碼維護基準(SWE-Bench Pro 等)——在測試實務軟體工程能力的任務上(大型重構、凌亂程式碼庫中的缺陷分流與某些類型的自動程式修復),Gemini 3.1 Pro 落後於某競品(Anthropic 的 Claude Opus 4.6)。換言之,對於日常工程維護工作,在某些測試集上專門模型仍具優勢。
- 延遲敏感的微任務——由於 Gemini 3.1 Pro 針對深度進行調校,要求超低延遲與高吞吐的任務(例如輕量對話式 UI 的微推理)可能更適合使用 Gemini 系列中的「Flash」或其他優化變體。
Gemini 3.1 Pro 的價格是多少?
你可以透過兩種方式使用 Gemini 3.1 Pro——消費者訂閱或開發者 API——兩者的定價不同。
- 消費者(Gemini 應用程式/Google AI Pro): 使用 Google AI Pro 訂閱即可存取 Gemini 3.1 Pro,在美國為每月 $19.99(Google 亦提供較低階的「AI Plus」與更高的「AI Ultra」方案)。Google。
- 開發者/API(按 token 計費): 若你透過 Gemini/AI 開發者 API 呼叫 Gemini 模型,定價採用按 token 計費。Gemini 3.x Pro 預覽的公開開發者價格大致為:標準(≤200k 提示)檔位 每 1M 輸入 token $2.00、每 1M 輸出 token $12.00——對於超大型上下文,較高階層(例如每 1M 分別 $4/$18)。(詳見 Gemini API 定價表與批量定價。)
- 若你透過 CometAPI 使用 Gemini 3.1 Pro:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$1.6/M; Output:$9.6/M | Input:$2/M; Output:$12/M |
消費者訂閱定價(Gemini 應用程式)
在 Gemini 應用程式內的終端使用者方案中,Google 以分級結構來控制對模型變體與額外功能的存取:Google AI Pro 與 Google AI Ultra。價格因市場與幣別而異;已公佈範例顯示Google AI Pro 為每月 $19.99(提供促銷試用),並在產品頁面顯示分幣別的分級定價(包含試用優惠與短期降價)。AI Ultra 則捆綁更高的存取(例如優先使用新創新、更高的影片生成額度),月費更高。這些消費者方案定價與其他高階消費者 AI 訂閱具有競爭力,旨在讓個人進階用戶或小型團隊在無需 API 整合的情況下獲得 3.1 Pro 的功能。
實用提示與用法建議(我的做法)
為獲得可靠、可重複的結果,請使用如下策略:
- 顯式步驟規劃
提示範式:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.這能利用 3.1 Pro 更強的逐步執行,並提供檢查點。 - 使用具模式的結構化輸出
要求以 JSON 並提供模式且strict: true。由於 3.1 Pro 更可靠地生成長且遵循模式的輸出,你能獲得更大的單次回應以供下游解析。 - 工具檢查三明治
在調用外部工具(API、程式碼執行器)時,要求模型輸出:計劃 → 精確的工具呼叫(可複製貼上) → 驗證步驟。然後在模型之外驗證這些步驟再繼續。 - 警惕單步信任
即使模型寫出看似完美的程式碼或命令,也要進行獨立驗證(測試、語法檢查、沙箱執行)——尤其是代理式/自動化行為。
Gemini 3.1 Pro 實測
試用案例 1:長上下文研究助理(NotebookLM/Deep Research)
目標: 評估模型將 10–50 份長文檔(例如報告、白皮書)綜合為多頁主管摘要,包含引文與行動項的能力。
設定: 輸入總計 200k–800k tokens 的文集;要求模型產出 2–4 頁摘要,包含明確引文與「下一步」建議。使用可重複的提示樣板並衡量時間、token 使用(成本)與事實準確性。
結果: 相比舊模型,端到端摘要更快、切分造成的瑕疵更少,引文準確度更高,且在大規模下的連貫性更佳——代價是顯著的 token 使用(因此需規劃預算)。基準與實測顯示,得益於 1M token 窗口,Gemini 3.1 Pro 在多文件綜合方面表現突出。
試用案例 2:代理式編碼助理(Antigravity+GitHub Copilot)
目標: 測量多步開發任務的完成時間縮減(例如在多檔案中實作功能、執行測試、修復失敗測試)。
設定: 在預覽中選擇 Gemini 3.1 Pro,使用 Antigravity 或 GitHub Copilot。定義可重現的任務(建立 issue → 實作 → 執行測試),記錄步驟與代理工件,並與純人工基準比較。
結果: 多步任務的編排更佳(工件記錄、補丁候選的自動建議),相較先前 Gemini 3 Pro 有更好的多檔案推理,且在常規功能工作上可測得時間節省。對於專門、低階系統除錯任務,社群結果顯示在某些終端基準上仍偏向某些 GPT-Codex 變體。
試用案例 3:多模態法律/醫療文件審閱
目標: 使用模型攝取混合語料(掃描 PDF、圖像、音訊逐字稿),抽取關鍵事實,並產出風險矩陣與優先行動。
設定: 提供包含掃描圖像與 OCR 文本的資料集,外加支援音訊。衡量命名實體抽取的精準度、誤報率,以及模型引用來源工件的能力。
結果: 在多模態間的整合推理更強,且輸出更可追溯(能指向支持主張的圖像/頁面/音訊時間戳)。長上下文窗口降低了手動切分與交叉參照的需求。然而,在受監管領域,輸出應由領域專家驗證,並使用錨定/驗證管線。
第一印象(有哪些不同)
- 更深的逐步推理。 過去需要多次往返的任務——例如多文件綜合、多步數學/邏輯——往往能在更少回合中完成,且呈現更清晰的思維鏈風格輸出(不會暴露內部指令文本)。這是 Google 強調的重點。
- 更長且更高品質的結構化輸出。 JSON 與長流程自動化更一致,且往往更長(有用戶回報輸出大小遠超 3.0)。這對需要單次大負載的生成工作非常友好。請預期更大的輸出與串流處理。
- 更高的 token/上下文效率。 在使用工具的場景中,更「錨定、事實一致」的行為與更少幻覺。這反映在短事實查詢中的表現。
最終結論:現在值得採用 Gemini 3.1 Pro 嗎?
Gemini 3.1 Pro 在 Gemini 系列上邁出了有意義的一步,在推理、編碼與代理基準上展現了可驗證的提升——由 Google 發佈的模型卡與獨立追蹤者引用的部分排行榜大幅躍升所支撐。對於需要先進推理、代理工具協調或長上下文多模態能力的團隊而言,3.1 Pro 是一個有吸引力的候選項。
開發者可透過 CometAPI 訪問 Gemini 3.1 Pro。開始之前,請先在 Playground 探索模型能力,並參考 API guide 取得詳細指引。存取前,請確保你已登入 CometAPI 並取得 API key。CometAPI 提供遠低於官方的價格,協助你完成整合。
準備好了嗎?→ Sign up fo Gemini 3.1 pro today!