

谷歌正式發布了其首個生產級文本嵌入模型, gemini-嵌入-001這標誌著該公司在推進自然語言理解和表達方面邁出了關鍵一步。如今,這項先進的模型已透過 Gemini API、Google AI Studio 和 Vertex AI 廣泛向開發者開放,預計將重新定義語義搜尋、推薦系統以及一系列下游 AI 應用。
主要特性和功能
- 多語言支持: gemini-embedding-001 原生支援處理超過 100 種語言,可實現真正的全球部署和跨語言檢索任務。
- 上下文長度: 模型接受最多 2,048 個標記的輸入,可容納長格式文件、程式碼片段和多句子段落(無需截斷)。
- 動態輸出尺寸: 利用 Google 專有的 Matryoshka 表徵學習 (MRL) 技術,開發人員可以靈活地調整嵌入大小(預設為 3072 維,可選擇減少到 1536 或 768),以優化儲存和運算成本,同時保持高保真度。
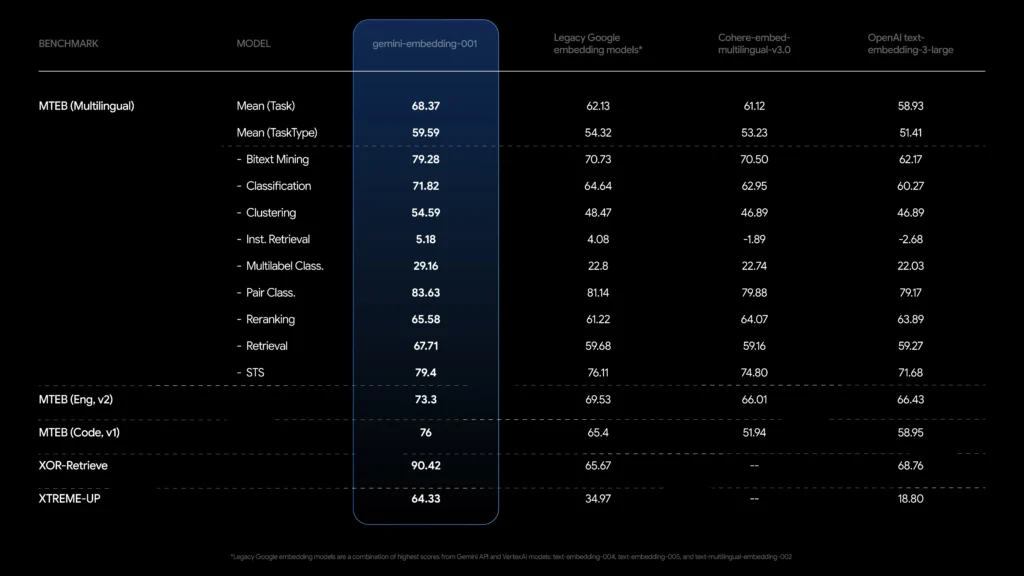
基準性能
gemini-embedding-001 已經在 **海量文字嵌入基準測試(MTEB)**在多語言和單語言評估中,它的平均任務得分為 68.32超越了 Mistral 和基於 Qwen 的嵌入等領先競爭對手。值得注意的是,它在配對分類任務中得分 85.13,在檢索任務中得分 67.71,在重排序任務中得分 65.58——這些指標凸顯了它在各種文本處理場景中的多功能性。
如何使用
為了鼓勵實驗和採用,Google 提供了 免費和付費等級 適用於 gemini-embedding-001。免費套餐配額用完後,使用費用按 每百萬輸入令牌 0.15 美元,使其在業界具有競爭力的價格。速率限制旨在適應一系列用例,從輕量級開發原型到企業規模部署。
開發人員可以訪問 gemini-embedding-001 今天透過現有的 embed_content Gemini API 中的端點。與 Google AI Studio 和 Vertex AI 的整合確保了流暢的入門體驗。 Python 中的使用範例非常簡單:
from google import genai
client = genai.Client()
result = client.models.embed_content(
model="gemini-embedding-001",
contents="What is the meaning of life?"
)
print(result.embeddings)
對於那些從實驗過渡的人來說 gemini-embedding-exp-03-07 或傳統嵌入模型(embedding-001, text-embedding-004),Google宣布棄用時間表:實驗版本和舊版本 embedding-001 將於 2025 年 8 月 14 日,而 text-embedding-004 計劃於 2026 年 1 月 14 日建議儘早遷移到 gemini-embedding-001,以確保服務不會中斷並獲得最新的效能改進。
展望未來,Google計劃擴展 Gemini Embedding 的功能,包括 批量API 支援非同步、經濟高效的處理,以及涵蓋更廣泛模態的未來嵌入模型。憑藉強大的多語言覆蓋範圍、可調節的維度和極具競爭力的價格,gemini-embedding-001 已準備好為下一代 AI 驅動的應用提供支援。
入門
CometAPI 提供了一個統一的 REST 接口,在一致的端點下聚合了數百個 AI 模型,並具有內建的 API 金鑰管理、使用配額和計費儀表板。而不需要處理多個供應商 URL 和憑證。
開發人員可以訪問 Gemini 2.5 Pro 預覽版 維奧 3 通過 彗星API,列出的最新型號版本截至本文發布之日。並使用 Google 的 Gemini CLI 在 CometAPI 上!首先,探索模型的功能 游乐场 並諮詢 API指南 以獲得詳細說明。造訪前請確保您已經登入CometAPI並取得API金鑰。 彗星API 提供遠低於官方價格的價格,幫助您整合。
最新整合的 gemini-embedding-001 很快就會出現在 CometAPI 上,敬請期待!在我們完成 gemini-embedding-001 模型上傳的同時,您可以在模型頁面上探索我們的其他模型,或在 AI Playground 中嘗試它們。