

2026 年 3 月 3 日,Google 發布了 Gemini 3.1 Flash-Lite,這是 Gemini 3 家族中最新的成員,專為開發者與企業工作負載設計,定位為高吞吐量、低延遲、具成本效率的引擎。Google 將 Flash-Lite 定位為 Gemini 3 系列中“最快且最具成本效率”的模型:一款輕量級變體,旨在以遠低於 Pro 系列的價格點,提供串流互動、大規模後台處理與高頻率生產任務(例如翻譯、抽取、UI 生成與大批量分類)。
以下將解析 Flash-Lite 是什麼。
什麼是 Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite 是 Google Gemini 3 家族的一員,刻意以部分最高階推理深度換取速度與成本效率。它在 Gemini 系列中原生支援多模態(可接受文字、影像與其他模態輸入),但針對需要快速、反覆推理而非極致認知深度的工作負載,特別調校與部署為每秒 token 數最大化與大幅降低每個 token 計費。該模型被描述為源自 3.1 Pro 架構,但針對吞吐量、延遲與成本進行最佳化。
關鍵設計取捨
“Lite” 名稱表明了該模型的工程重點:
- 以吞吐量優先於重負載推理: Flash-Lite 有意降低每個 token 的計算量,以提供更快的 Time-to-First-Token(TTFT)與持續輸出速度。這使其非常適合每個請求必須快速、規模化服務的管線(例如安全過濾、即時助理與高容量生成)。
- 面向高規模的成本效率: 藉由降低每個 token 的計算量,模型可以以更低的每百萬 token 價格提供服務,從而在大規模應用(例如每月數百萬至數十億 token)中降低邊際成本。Google 的預覽定價顯示與 Pro 等級之間存在顯著差距。
- 針對務實任務調校的品質: 根據早期評分摘要,Flash-Lite 在標準分類、多語言與許多多模態任務上維持了穩健表現,但在對推理深度要求更高的最複雜多步推理或程式碼生成基準上,並未定位為要超越 Pro。
這些工作負載需要可靠輸出與高吞吐,但不一定需要旗艦模型的複雜多步推理能力。
Gemini 3.1 Flash-Lite 的關鍵特性
1. 低延遲與快速首個 token 時間
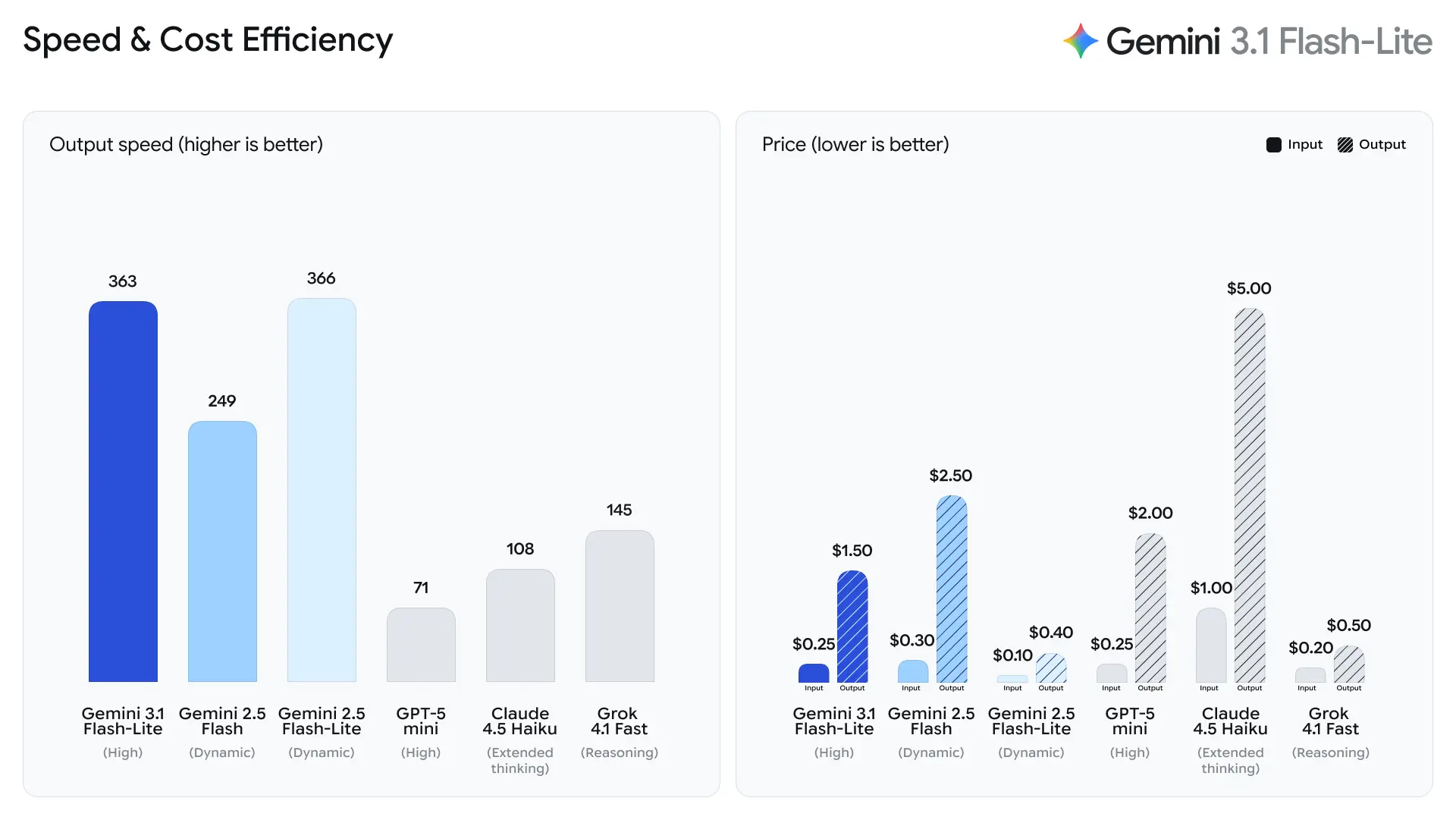
Google 將首個答案 token(time-to-first-answer token)視為 Flash-Lite 的主要指標。官方稱其相較 Gemini 2.5 Flash 的首個 token 時間快約 2.5 倍,輸出生成速度最高快 45%——這些改進直接影響終端使用者的回應體驗與後端系統的吞吐成本。這些提升使 Flash-Lite 非常適合需要高互動性的功能(例如嵌入應用的聊天機器人)與對微秒級延遲敏感的高 QPS 管線。
這些改進顯著強化了即時應用,例如:
- 對話式 AI
- AI 驅動的搜尋助理
- 互動式聊天機器人
- 即時翻譯服務
較低延遲透過縮短等待時間並使互動更流暢,改善了使用者體驗。
2. 具成本效率的 token 計價
AI 推理成本常以每個 token 計價,因此對大規模部署而言,定價是關鍵因素。
Gemini 3.1 Flash-Lite 引入了極具競爭力的定價:
| Token 類型 | 價格 |
|---|---|
| 輸入 tokens | $0.25 每 1M tokens |
| 輸出 tokens | $1.50 每 1M tokens |
這相較於先前的 Flash 模型有所降低,對於運行大規模工作負載的組織更具吸引力。
作比較:
| 模型 | 輸入價格 | 輸出價格 |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
這一策略讓開發者可以在不大幅增加營運成本的情況下規模化運行 AI。
如果你在尋找更優惠的價格,則 Gemini Flash-Lite 在 CometAPI 上提供 20% 折扣。
3. 「思考層級」(可控的推理深度)
Gemini 3.1 Flash-Lite 提供 「思考層級(thinking levels)」 能力——開發者可配置旋鈕,指示模型在簡單任務偏向更快、更淺層處理,而在難題時進行更深層推理。這在實務上很重要,因為可在不切換模型的情況下,針對每個請求動態調整成本/延遲取捨。
開發者可以配置模型的推理深度,使其匹配任務複雜度。思考層級:支援四個層級:Minimal、Low、Medium 與 High。
這種動態方式讓應用能優化資源使用,並在關鍵之處維持品質。實務策略大致如下:
- Minimal/Low:適合高併發但邏輯簡單的任務,例如翻譯、分類與情緒分析,優先最大速度與最低成本。
- Medium:適合多數生產任務,在品質與效率之間取得平衡。
- High:適合需要深度推理的任務,例如生成使用者介面、建立模擬與執行複雜指令。
4. 輕量足跡下的多模態能力
雖然 Flash-Lite 針對速度與成本最佳化,但仍保留 Gemini 3 系列的多模態基礎:在需要時可接受影像輸入以進行分類或輕量多模態推理——但開發者應預期其經濟化設計更偏好短且邊界明確的多模態操作,而非超大規模、影像密集的工作流程。與其他 Gemini 模型一樣,Gemini 3.1 Flash-Lite 支援多模態輸入,使開發者能處理不同類型的資料。
支援的輸入包括:
- 文字
- 圖像
- 影片
- 音訊
- PDFs
模型分析多種資訊型態的能力,解鎖了新的用例,例如:
- 自動化文件處理
- 視覺資料抽取
- 多媒體摘要
更早的 Gemini 模型也曾在視覺與知識基準上展現出色的多模態推理能力。
效能基準——真實數據與其意涵
Google 的公告與產品文件給出了多個基準數據點,旨在協助買家理解 Flash-Lite 在生態系中的位置。
面向開發者的速度指標
- 首個答案 token 時間快 2.5 倍,相較 Gemini 2.5 Flash(Google 內部比較說法)。
- 輸出生成快 45%,相較 Gemini 2.5 Flash。
這些屬於效能工程指標,而非人工評分的品質指標;它們反映了執行時微架構、批次與推理堆疊優化,帶來對短回覆的延遲降低。更快的首個 token 時間可減少互動式應用的感知延遲,並提高每台伺服器的總體吞吐量,從而在相同 QPS 下降低總計算成本。
tokens-per-second(t/s)與吞吐量
根據 Artificial Analysis 的測試數據,3.1 Flash-Lite 的輸出速度達到每秒 388.8 tokens(相同價位模型的中位數僅 96.7 tokens/second)。這一速度在同級模型中屬於頂尖水準。
然而,Artificial Analysis 也指出一個問題:3.1 Flash-Lite 的首個 token 延遲(TTFT)為 5.18 秒,對於同價位的推理模型而言相對較高(中位數為 1.82 秒)。此外,該模型在評估過程中共生成了 53 million tokens,明顯高於平均的 20 million。這意味著若你的場景對首個 token 延遲極為敏感,或對輸出精簡度有嚴格要求,可能需要調整思考層級與提示詞以優化。
推理與事實性基準分數
Google 的跨模型比較顯示,Gemini 3.1 Flash-Lite 在綜合推理/事實任務上相較同儕與先前的 Gemini 變體展現了強勢表現:
- Arena.ai Elo 分數: 據報 Gemini 3.1 Flash-Lite 在 Arena 評估排行榜上取得 Elo 1432——這是基於對戰的綜合排名,顯示在直接比對情境中的競爭力。
- GPQA Diamond: 86.9%(衡量問答穩健度)。
- MMMU Pro: 76.8%(部分實驗室內外使用的多模態/多任務指標)。
- LiveCodeBench(程式能力):72.0%
- CharXiv Reasoning(圖形化推理):73.2%
- Video-MMMU(影片理解):84.8%
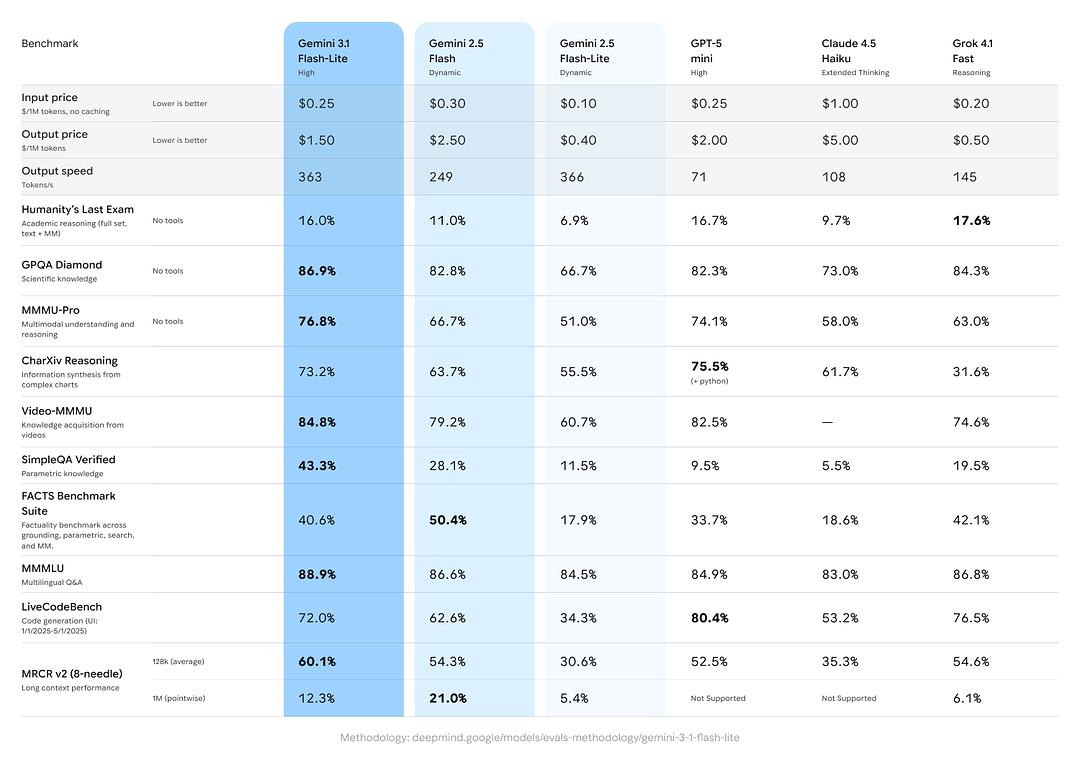
Gemini 3.1 Flash-Lite 在其中多項指標上超越更早的 Gemini 2.5 Flash,同時提供更佳的速度/成本表現。
適合 Gemini 3.1 Flash-Lite 的用例
Gemini 3.1 Flash-Lite 圍繞一組明確、務實的工作負載而設計,其中高吞吐與較低的每個 token 成本是關鍵:
高頻對話代理與串流式 UI
即時聊天機器人、逐字轉錄 + 翻譯串流,以及在生成過程中展示部分答案的協作式 UI,都能受益於 Flash-Lite 的串流 token 輸出與較低的首個 token 時間。
批次資料處理(RAG、轉換管線)
大規模文件匯入:實體抽取、後設資料標註、分類與翻譯,針對數百萬份文件執行——Gemini 3.1 Flash-Lite 在提供可接受準確度的同時,降低了推理成本,適合模板化或規則導向的輸出。
類邊緣或背景運算
持續處理進入的遙測或非結構化資料的工作負載(例如內容審核分類管線、自動化報告生成),是良好適配場景,因為 Gemini 3.1 Flash-Lite 將單位成本降至更低。
開發者工具與批次程式碼補全
針對多檔案腳手架、超大規模程式碼靜態檢查與模板批量生成等功能,Gemini 3.1 Flash-Lite 的速度優勢可降低延遲與成本,特別適合對極致推理深度要求不高的開發者體驗工具。
比較:Gemini 3.1 Flash-Lite 與其他 Gemini 模型及競品
在 Gemini 家族內
- Gemini 3.1 Pro: 在複雜推理與多步規劃方面具備最高能力;每個 token 成本更高、速度更慢,但更適合高度細緻的深度任務。
- Gemini 3.1 Flash(非 Lite): 在吞吐與能力之間取得中間地帶——Flash-Lite 進一步沿計算堆疊向吞吐量最佳化。
對比競爭對手的「快速」模型
Gemini 3.1 Flash-Lite 在許多吞吐與品質指標上超越或匹配多款快速/迷你模型——但獨立分析者提醒,直接對比高度受評估方法與資料集選擇影響。可預期 Gemini 3.1 Flash-Lite 在吞吐與成本上極具競爭力,同時在最高階的推理指標上位居中游。
結論——Flash-Lite 在 AI 堆疊中的定位
Gemini 3.1 Flash-Lite 是經過刻意工程設計的產品:作為 Gemini 3 家族中專注吞吐的高效率成員,它允許團隊以部分單例計算換取在延遲與成本上的大幅改善。對於建置高容量管線——翻譯、批次處理、串流式 UI 與中等複雜度代理任務——的企業與開發者而言,Flash-Lite 是合理的基準引擎。若組織需要絕對最高的推理保真度,Pro 系列仍是適當選擇。
如果你的工作負載以眾多短小、可重複的推理為主,或需要在大規模下快速串流輸出,Flash-Lite 值得試點。如果你的工作負載依賴深度多跳推理,請規劃混合路由:將吞吐導向流量交給 Flash-Lite,並將高價值、複雜查詢升級至 Pro 模型。
開發者現在即可透過 Gemini 3.1 Flash Lite 與 CometAPI 存取。開始之前,請在 Playground 體驗模型能力,並參閱 API guide 取得詳細說明。存取前,請先登入 CometAPI 並取得 API key。CometAPI 提供遠低於官方的價格,幫助你整合落地。
準備好了嗎?→ 今天就註冊 Gemini 3.1 Flash lite!