GPT-4o 音訊 API: 統一的 /chat/completions 端點擴展,接受 Opus 編碼的音訊(和文字)輸入並傳回具有可設定參數的合成語音或文字記錄(模型=gpt-4o-audio-preview-<date>, speed, temperature) 進行批量和串流語音互動。
GPT-4o Audio 的基本訊息
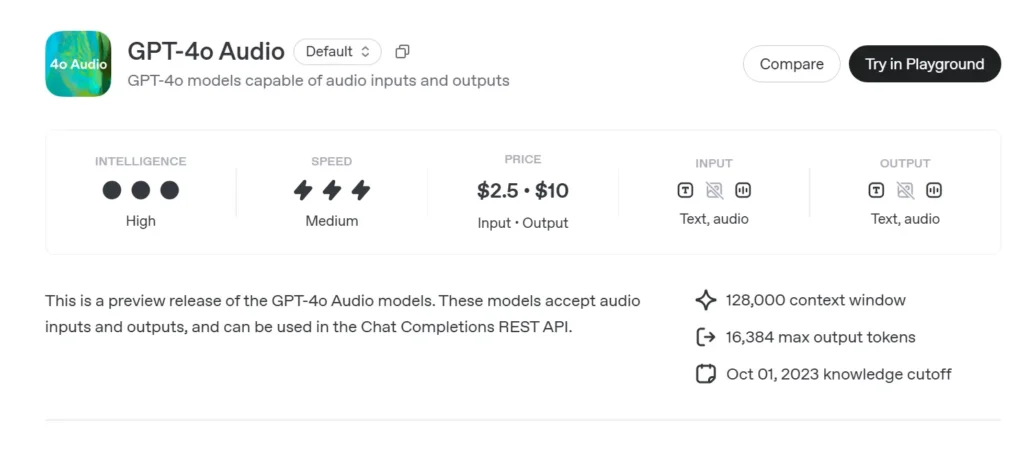
GPT-4o 音訊預覽 (gpt-4o-audio-preview-2025-06-03) 是 OpenAI 最新的 以語音為中心的大型語言模型 透過標準提供 聊天完成 API 而不是超低延遲即時通道。該變體與 GPT-4o 一樣,建立在相同的“全能”基礎上,專注於 高保真語音輸入和輸出 適用於回合製對話、內容建立、輔助工具以及無需毫秒計時的代理工作流程。它繼承了 GPT-4 類別模型的所有文本推理優勢,同時添加了 端對端語音到語音(S2S) 管道,確定性 函數呼叫和新的 speed 參數 用於語音速率控制。
GPT-4o 音訊的核心功能集
• 統一語音轉語音處理 – 音訊直接轉換為語義豐富的標記,經過推理,並重新合成,無需外部 STT/TTS 服務,從而產生 一致的音色、韻律和語境保留.
• 改進指令遵循 – 2025 年 XNUMX 月調整交付 +19 pp 傳球-1 與 2024 年 4 月的 GPT-XNUMXo 基準相比,語音命令任務的成績有所提高,減少了客戶支援和內容起草等領域的幻覺。
• 穩定工具調用 – 模型輸出 結構化 JSON 符合 OpenAI 函數呼叫模式,支援觸發後端 API(搜尋、預訂、支付) 論證準確率 >95%.
• speed 參數(0.25–4×) - 開發人員可以調節語音播放,以實現慢節奏學習、正常敘述或快速「可聽瀏覽」模式, 無 在外部重新合成文字。
• 中斷感知輪流 – 雖然不像即時版本那樣受延遲驅動,但預覽支持 部分串流媒體:令牌在計算後立即發出,以便用戶在必要時儘早中斷。
GPT-4o的技術架構
• 單堆變壓器 與所有 GPT-4o 衍生產品一樣,音訊預覽採用 統一編碼器-解碼器 其中文本和聲學標記通過相同的注意力塊,促進跨模式基礎。
• 分層音訊標記化 – 原始 16 kHz PCM → log-mel 補丁 → 粗聲學代碼 → 語意標記。這種多級壓縮實現了 頻寬減少 40–50 倍 同時保留細微差別,實現每個上下文視窗的多分鐘剪輯。
• NF4 量化權重 – 推理發生在 4 位正常浮點數 精度,與 fp16 相比,GPU 記憶體減少了一半,並且保持 70+ 串流 RTF(即時因素) 在 A100-80 GB 節點上。
• 串流注意力機制和鍵值緩存 – 滑動視窗旋轉嵌入可以在約 30 秒的語音中保持上下文,同時保持 O(L) 記憶體使用情況,非常適合播客編輯器或輔助閱讀工具。
版本控制與命名 — 帶有日期標記的預覽軌道
| 識別碼 | 渠道 | 目的 | 發布日期 | 穩定性 |
|---|---|---|---|---|
| GPT-4O-音訊預覽-2025-06-03 | 聊天完成 API | 回合製音訊互動、代理任務 | 六月03 2025 | 預覽 (鼓勵回饋) |
名稱中的關鍵要素:
- GPT-4O – 全方位多式聯運系列。
- 音頻 – 針對語音用例進行了最佳化。
- 預習 – API 合約可能會演變;尚未正式發布。
- 2025-06-03 – 訓練和部署快照以實現可重複性。
如何從 CometAPI 呼叫 GPT-4o Audio API
GPT-4o Audio API CometAPI 中的 API 定價:
- 輸入代幣:2 美元/百萬個代幣
- 輸出代幣:8 美元/百萬代幣
所需步驟
- 登錄到 cometapi.com。如果您還不是我們的用戶,請先註冊
- 取得介面的存取憑證API key。在個人中心的API token處點選“新增Token”,取得Token金鑰:sk-xxxxx並提交。
- 取得此網站的 URL: https://api.cometapi.com/
使用方法
- 選擇“
gpt-4o-audio-preview-2025-06-03「端點傳送請求並設定請求體。請求方法和請求體可從我們網站的API文件取得。為了方便您使用,我們網站也提供了Apifox測試。 - 代替使用您帳戶中的實際 CometAPI 金鑰。
- 將您的問題或請求插入內容欄位 - 這是模型將會回應的內容。
- 。處理 API 回應以取得產生的答案。
有關 Comet API 中的模型存取信息,請參閱 API 文件.
有關 Comet API 中的模型價格信息,請參閱 https://api.cometapi.com/pricing.
API 工作流程 — 使用音訊部分和功能掛鉤完成聊天
- 輸入格式 -
audio/*MIME 或base64嵌入的 WAV 區塊messages[].content. - 輸出選項 -
•mode: "text"→ 純文字字幕。
•mode: "audio"→ 返回 流 帶有時間戳記的 Opus 或 µ-law 酬載。 - 函數呼叫 -添加
functions:模式;模型發出role: "function"使用 JSON 參數;開發人員執行工具呼叫並可選擇將結果透過管道傳回。 - 速率控制 –設置
voice.speed=1.25加速播放;安全範圍 0.25–4.0。 - 令牌/音訊限制 – 啟動時有 128 k 個上下文(約 4 分鐘語音); 4096 個音訊標記 / 8192 個文字標記 以先到者為準。
範例程式碼和 API 集成
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- :
- 模型:
"gpt-4o-audio-preview-2025-06-03" - 音頻 鍵入 用戶 訊息發送二進位流
- 速度:控件 語音速率 介於慢(0.5)和快(2.0)之間
- 溫度: 餘額 創造力 與 一致性
技術指標 — 延遲、品質、準確性
| 公制 | 音訊預覽 | GPT-4o(純文字) | 三角洲 |
|---|---|---|---|
| 第一個令牌延遲(1 次) | 1.2小號 平均 | 0.35小號 | +0.85秒 |
| MOS(語音自然度,5分) | 4.43 | - | - |
| 指令合規性(語音) | 92% | 73% | +19個百分點 |
| 函數呼叫參數準確度 | 95.8% | 87% | +8.8個百分點 |
| 字錯誤率(隱式 STT) | 5.2% | 不承保 | - |
| GPU 記憶體/串流 (A100-80GB) | GB 7.1 | 14 GB(fp16) | −49% |
透過聊天完成流程執行的基準測試,批量大小 = 1。