

透過 CometAPI 使用 Gemini 2.5 Flash-Lite,您將有機會利用當今最具成本效益、低延遲的生成式 AI 模型之一。本指南結合了 Google DeepMind 的最新公告、Vertex AI 文件的詳細規範以及使用 CometAPI 的實用整合步驟,幫助您快速有效地啟動並運行。
什麼是 Gemini 2.5 Flash-Lite 以及為什麼要考慮它?
Gemini 2.5系列概述
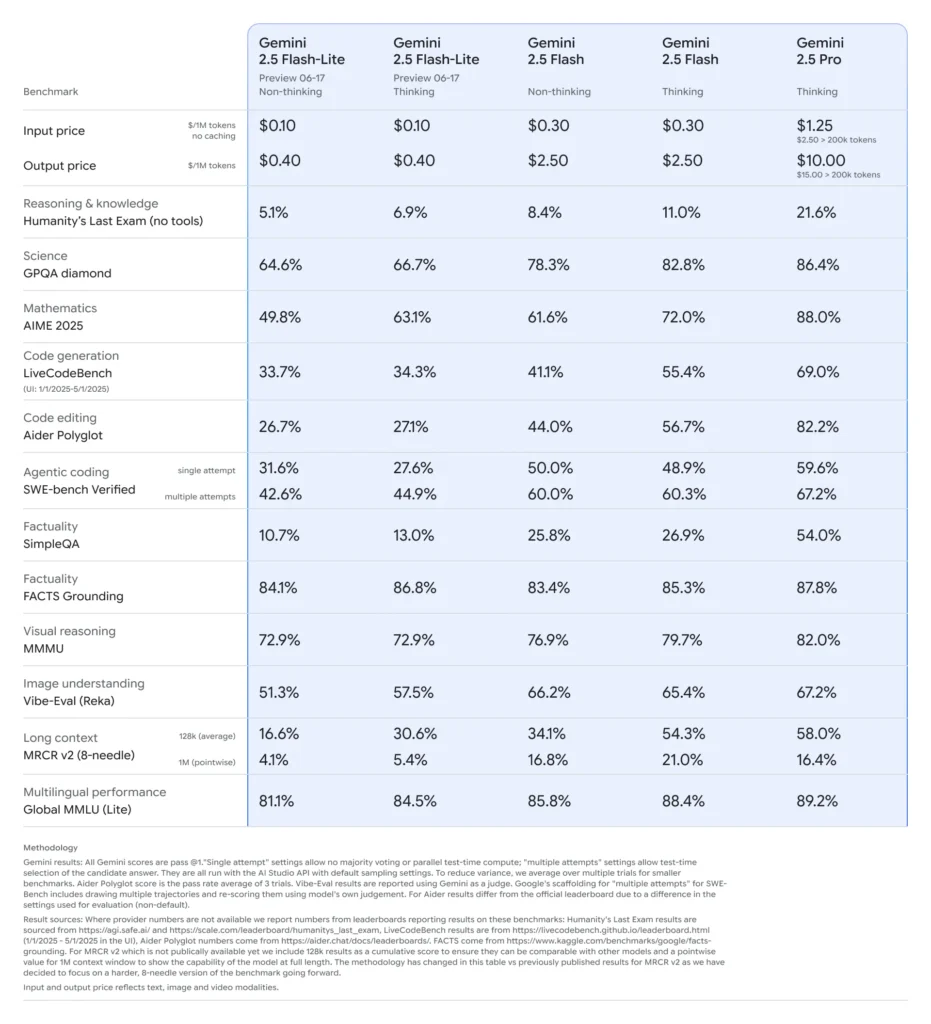
2025年2.5月中旬,Google DeepMind 正式發表了 Gemini 2.5 系列,包括 Gemini 2.5 Pro 和 Gemini 2.5 Flash 的穩定 GA 版本,以及全新輕量級版本 Gemini 2.5 Flash-Lite 的預覽版。 XNUMX 系列旨在平衡速度、成本和效能,體現了 Google 致力於滿足廣泛用例的需求——從繁重的研究工作到大規模、成本敏感的部署。
Flash-Lite 的主要特性
Flash-Lite 的獨特之處在於其以極低的延遲提供多模式功能(文字、圖像、音訊、視訊),其上下文視窗支援多達一百萬個令牌,並整合了包括 Google 搜尋、程式碼執行和函數呼叫在內的工具。至關重要的是,Flash-Lite 引入了「思考預算」控制,允許開發人員透過調整內部代幣預算參數來權衡推理深度與回應時間和成本。
在車型陣容中的定位
與同類產品相比,Flash-Lite 的性價比處於帕累托前沿:預覽版價格約為每百萬輸入令牌 0.10 美元,每百萬輸出令牌 0.40 美元,低於 Flash(0.30 美元/2.50 美元)和 Pro(1.25 美元/10 美元),同時保留了 Flash 的大部分多模式功能和函數支援。這使得 Flash-Lite 成為高容量、低複雜度任務的理想選擇,例如摘要、分類和輕量級對話代理。
為什麼開發人員應該考慮 Gemini 2.5 Flash-Lite?
性能基準和實際測試
在面對面的比較中,Flash-Lite 表現出:
- 吞吐量提高 2 倍 在分類任務上比 Gemini 2.5 Flash 表現更好。
- 節省 3 倍成本 用於企業規模的摘要管道。
- 競爭性準確度 在邏輯、數學和程式碼基準測試中,配對或超越了早期的 Flash-Lite 預覽版。
理想用例
- 大容量聊天機器人:為數百萬用戶提供一致、低延遲的對話體驗。
- 自動化內容生成:規模化文件摘要、翻譯、微文案創作。
- 搜尋和推薦管道:利用快速推理實現即時個人化。
- 大量資料處理:以最小的計算成本註釋大型資料集。
如何透過 CometAPI 取得和管理 Gemini 2.5 Flash-Lite 的 API 存取?
為什麼要使用 CometAPI 作為您的網關?
CometAPI 將超過 500 個 AI 模型(包括 Google 的 Gemini 系列)聚合到統一的 REST 端點下,從而簡化了跨提供者的身份驗證、速率限制和計費。您無需處理多個基礎 URL 和 API 金鑰,而是將所有請求指向 https://api.cometapi.com/v1,在有效載荷中指定目標模型,並透過單一儀表板管理使用情況。
先決條件和註冊
- 登錄到 cometapi.com。如果您還不是我們的用戶,請先註冊
- 取得介面的存取憑證API key。在個人中心的API token處點選“新增Token”,取得Token金鑰:sk-xxxxx並提交。
- 取得此網站的 URL: https://api.cometapi.com/
管理您的代幣和配額
CometAPI 的儀表板提供統一的令牌配額,可在 Google、OpenAI、Anthropic 和其他模型之間共用。使用內建的監控工具設定使用量警報和速率限制,確保您不會超出預算分配或產生意外費用。
如何設定您的開發環境以進行 CometAPI 整合?
安裝所需的依賴項
對於 Python 集成,請安裝以下軟體包:
pip install openai requests pillow
- openai:與 CometAPI 通訊的相容 SDK。
- 請求:用於下載影像等HTTP操作。
- 枕頭:用於發送多模式輸入時的影像處理。
初始化 CometAPI 用戶端
使用環境變數將您的 API 金鑰保留在原始程式碼之外:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
此客戶端實例現在可以透過指定其 ID 來定位任何受支援的模型(例如, gemini-2.5-flash-lite-preview-06-17) 在您的請求中。
配置思想預算和其他參數
發送請求時,您可以包含可選參數:
- 溫度/top_p:控制生成中的隨機性。
- 候選數量:備選輸出的數量。
- 最大令牌數:輸出令牌上限。
- 思想預算:Flash-Lite 的自訂參數,用於在深度、速度和成本之間進行權衡。
透過 CometAPI 向 Gemini 2.5 Flash-Lite 發出的基本請求是什麼樣的?
純文字範例
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
此呼叫在 200 毫秒內傳回簡潔的摘要,非常適合聊天機器人或即時分析管道。
多模態輸入範例
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite 可處理高達 7 MB 的影像並傳回上下文描述,使其適用於文件理解、UI 分析和自動報告。
如何利用流和函數呼叫等高階功能?
即時應用程式的串流回應
對於聊天機器人介面或即時字幕,請使用串流 API:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
這樣可以在部分輸出可用時進行交付,從而減少互動式 UI 中可感知的延遲。
結構化資料輸出的函數調用
定義 JSON 模式以強制執行結構化回應:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
這種方法保證了符合 JSON 的輸出,簡化了下游資料管道和整合。
使用 Gemini 2.5 Flash-Lite 時如何優化效能、成本與可靠性?
思想預算調整
Flash-Lite 的思考預算參數可讓您設定模型所需的「認知投入」。較低的預算(例如 0)優先考慮速度和成本,而較高的預算值則會以延遲和代幣為代價,以實現更深層的推理。
管理令牌限制和吞吐量
- 輸入令牌:每個請求最多 1,048,576 個令牌。
- 輸出代幣:預設限制為 65,536 個令牌。
- 多模態輸入:影像、音訊和視訊資產最多 500 MB。
針對大容量工作負載實施客戶端批次處理,並利用 CometAPI 的自動擴充功能來處理突發流量,無需人工幹預。
成本效益策略
- 在 Flash-Lite 上集中處理低複雜度任務,同時保留 Pro 或標準 Flash 來處理繁重的工作。
- 使用 CometAPI 儀表板中的速率限制和預算警報來防止失控的支出。
- 透過模型 ID 監控使用情況,比較每個請求的成本並相應地調整路由邏輯。
初始整合後的最佳實踐和後續步驟是什麼?
監控、日誌記錄和安全
- 記錄:擷取請求/回應元資料(時間戳、延遲、令牌使用情況)以進行效能稽核。
- 通知:在 CometAPI 中設定錯誤率或成本超支的門檻通知。
- 安全性:定期輪換 API 金鑰並將其儲存在安全的保險庫或環境變數中。
常見使用模式
- 聊天機器人:使用 Flash-Lite 進行快速使用者查詢,並傳回 Pro 進行複雜的後續操作。
- 文件處理:以較低的預算設定隔夜進行批量 PDF 或影像分析。
- 實時分析:透過串流 API 傳輸財務或營運數據以獲得即時洞察。
進一步探索
- 嘗試混合提示:結合文字和圖像輸入以獲得更豐富的內容。
- 透過將向量搜尋工具與 Gemini 2.5 Flash-Lite 相集成,原型 RAG(檢索增強生成)。
- 與競爭對手的產品(例如 GPT-4.1、Claude Sonnet 4)進行基準測試,以驗證成本和效能的權衡。
生產規模擴大
- 利用 CometAPI 的企業層獲得專用配額池和 SLA 保證。
- 實施藍綠部署策略來測試新的提示或預算,而不會幹擾即時使用者。
- 定期檢視模型使用指標,以確定進一步節省成本或改善品質的機會。
入門
CometAPI 提供了一個統一的 REST 接口,在一致的端點下聚合了數百個 AI 模型,並具有內建的 API 金鑰管理、使用配額和計費儀表板。而不需要處理多個供應商 URL 和憑證。
開發人員可以訪問 Gemini 2.5 Flash-Lite(預覽版)API(模型: gemini-2.5-flash-lite-preview-06-17)通過 彗星API,列出的最新模型截至本文發布之日。首先,探索模型在 游乐场 並諮詢 API指南 以獲得詳細說明。造訪前請確保您已經登入CometAPI並取得API金鑰。 彗星API 提供遠低於官方價格的價格,幫助您整合。
只需幾步,即可透過 CometAPI 將 Gemini 2.5 Flash-Lite 整合到您的應用程式中,解鎖速度、經濟實惠和多模態智慧的強大組合。遵循上述指南(涵蓋設定、基本請求、進階功能和最佳化),您將能夠為使用者提供下一代 AI 體驗。經濟高效、高吞吐量 AI 的未來已來:立即開始使用 Gemini 2.5 Flash-Lite。