

Kling O1 作為 Kling AI “Omni” 發布週的一部分推出,定位為單一的統一多模態視頻基礎模型,可在同一請求中接收文本、圖像和視頻,並能在導演級別的迭代工作流程中生成和編輯視頻。 Kling 團隊稱 O1 為「全球首個統一的多模態視訊大規模模型」。 Kling 的內部測試表明,O1 在性能上顯著優於 Google 的 Veo 3.1 和 Runway Aleph。
Kling O1是什麼?
Kling O1(通常以…的名義銷售) 影片 O1 or 全能一號Kling AI 新推出的影片基礎模型 O1,將文字、圖像和影片的生成和編輯統一到一個以提示驅動的框架內。與將文字轉影片、影像轉影片和影片編輯視為獨立流程不同,Kling O1 接受單一提示中的混合輸入(文字 + 多張影像 + 可選參考影片),進行推理,並產生連貫的短片或對現有素材進行精細控制的編輯。該公司將此次發布定位為“全面發布”的一部分,並將 O1 描述為“多模態視頻引擎”,它基於多模態視覺語言 (MVL) 範式和思維鏈 (CoT) 推理路徑構建,用於解讀複雜的多部分創意指令。
Kling 的訊息傳遞方式強調三種實用工作流程:(1) 文字 → 影片產生;(2) 影像/元素 → 影片(使用明確的參考進行合成和主體/道具替換);(3) 影片編輯/鏡頭延續(重新樣式化、新增/移除物件、起始影格/結束影格控制)。該模型支援多元素提示(包括用於指定參考圖像的“@”語法),並具有導演風格的控制功能,例如起始幀/結束幀錨定和視頻延續,以構建多鏡頭序列。
Kling O1 的 5 個核心亮點
1)真正的統一多模態輸入(MVL)
Kling O1 的旗艦功能是將文字、靜態影像(多張參考影像)和影片作為一級同步輸入。使用者可以提供多張參考圖像(或一段簡短的參考影片片段)。 自然語言指令;模型會將所有輸入解析在一起,產生或編輯出連貫的輸出。這減少了工具鏈的摩擦,並支持諸如「使用主題來自」之類的工作流程。 @image1將它們放置在環境中 @image2使動作與 ref_video.mp4並應用電影級色彩分級 X。 」這種「多模態視覺語言」(MVL)框架是克林提案的核心。
為什麼它的事項: 真正的創意工作流程通常需要整合各種參考資料:例如,一個素材中的角色、另一個素材中的鏡頭動作、一段文字敘述。將這些輸入統一起來,可以實現一次性生成,並減少手動合成步驟。
2) 在一個模型中編輯+生成(多元素模式)
以往大多數的系統都將影片生成(文字→影片)與幀級精確編輯分開。 O1 則有意將二者合而為一:同一個模型既可以從零開始創建視頻片段,也可以編輯現有素材——替換物體、重新設計服裝、移除道具或延長鏡頭——所有操作均可透過自然語言指令完成。這種整合極大地簡化了製作團隊的工作流程。
O1模型的核心在於實現多種視訊任務的深度整合:
- 文字轉影片生成
- 圖像/主題參考生成
- 影片剪輯與修復
- 影片風格重塑
- 下一個/上一鏡頭世代
- 關鍵影格約束影片生成
設計的最大意義在於:以往需要多個模型或獨立工具才能完成的複雜流程,現在可以在單一引擎內完成。這不僅顯著降低了創建和計算成本,而且為開發「統一的視訊理解和生成模型」奠定了基礎。
3)影片生成的連貫性
身分一致性: O1 模型增強了跨模態一致性建模能力,在生成過程中保持了參考對象結構、材質、光照和風格的穩定性:
- 它支援用於主體建模的多視圖參考影像;
- 它支援跨鏡頭主體一致性(角色、物件和場景特徵在不同的鏡頭中保持連續性);
- 它支援多主體混合參考,可產生集體肖像和建立互動式場景。
該機制顯著提高了視訊生成的連貫性和“身份一致性”,使其適用於對一致性要求極高的場景,例如廣告和電影級鏡頭生成。
記憶力提升: O1 模型還具備「記憶」功能,可防止因情境過長或指令變更而導致輸出風格不穩定。它甚至可以:
- 同時記住多個字元;
- 允許不同的角色在影片中互動;
- 保持風格、衣著和姿態的一致性。
4) 使用“@”語法和起始/結束幀控制進行精確合成
Kling 引入了一種合成簡寫方式(據報導為「@」提及系統),以便您可以在提示中引用特定的圖像(例如, @image1, @image2能夠可靠地為素材分配角色。結合明確的起始幀和結束幀規範,這使得導演可以對生成的片段中元素的過渡、移動或變形進行精細控制——這一以製作為中心的特性使 O1 區別於許多面向消費者的生成器。
5)高保真、較長的輸出和多任務堆疊
據報道,Kling O1 可產生電影級 1080p (30fps) 輸出,並且憑藉之前的 Kling 版本奠定的基礎,該公司宣稱其能夠生成更長的視頻片段(最近的產品評測中提到最長可達 2 分鐘)。它還支援在單一請求中疊加多個創意任務(生成影片、添加主體、調整光線和編輯構圖)。這些特性使其足以與更高階的文字轉視訊引擎相媲美。
為什麼它的事項: 更長、更高品質的影片片段以及合併剪輯的功能減少了將許多短影片片段拼接在一起的需求,簡化了端到端的製作流程。
Kling O1 的架構是怎麼樣的?其底層機制為何?
O1 周圍 多模態視覺語言(MVL) 核心部分:此模型學習語言、影像和運動訊號(視訊幀和光流式特徵)的聯合嵌入,然後應用基於擴散或Transformer的解碼器來合成時間上連貫的幀。該模型的性能被描述為… 空調 透過對多個參考(文字;一對多影像;短影片片段)進行處理,產生潛在的影片表示,然後將其解碼為逐幀影像,同時透過跨幀注意力或專門的時間模組保持時間一致性。
1. 多模態 Transformer + 長上下文架構
O1 模型採用 Keling 自主研發的多模態 Transformer 架構,整合文字、影像和視訊訊號,並支援長時序情境記憶(多模態長上下文)。
這使得模型能夠理解視訊生成過程中的時間連續性和空間一致性。
2. MVL:多模態視覺語言
MVL是此架構的核心創新點。
它透過統一的語意中間層,在Transformer模型內部深度整合語言和視覺訊號,從而:
- 允許單一輸入框混合輸入多模態指令;
- 提高模型對自然語言描述的準確理解能力;
- 支援高度靈活的互動式視訊生成。
MVL 的引入標誌著視訊生成從「文字驅動」轉變為「語義視覺協同驅動」的。
3. 鍊式推理機制
O1 模型在影片生成階段引入了「思維鏈」推理路徑。
該機制允許模型在生成之前執行事件邏輯和時間推斷,從而保持影片中動作和事件之間的自然聯繫。
推理和編輯流程
- 代: feed: (文字 + 選用影像引用 + 選用影片引用 + 產生設定) → 模型產生潛在影片畫面 → 解碼為影格 → 可選的顏色/時間後處理。
- 基於指令的編輯: 來源:(原始影片 + 文字說明 + 選用影像參考)→ 模型內部將要求的編輯對應到一組像素空間變換,然後在保持內容不變的情況下合成編輯後的影格。由於所有內容都在同一個模型中,因此建立和編輯都使用相同的條件模組和時間模組。
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
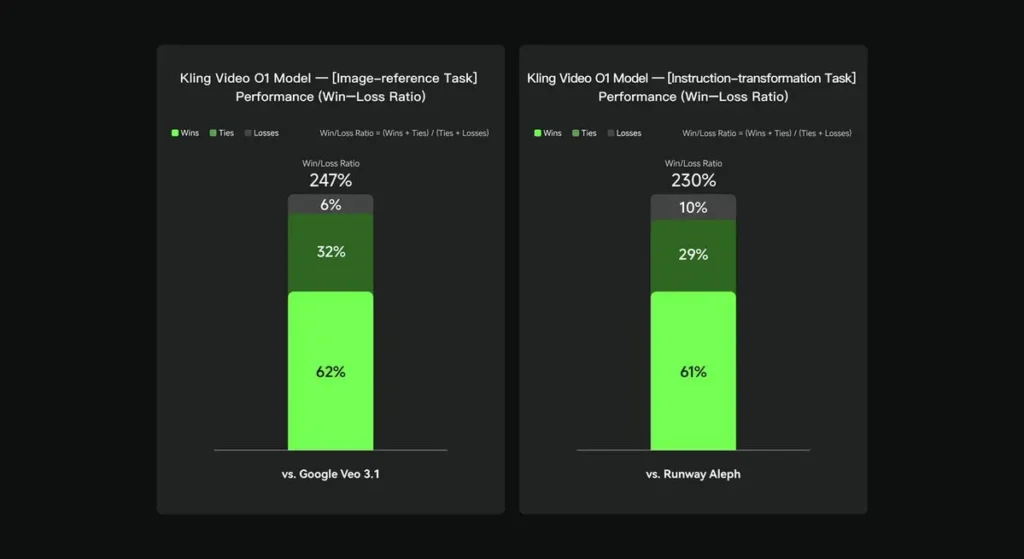
在內部評估中,科靈視訊O1在多個關鍵維度上顯著優於現有的國際同類產品。效能結果(基於科靈AI自建評估資料集):
- 「影像參考」任務:O1 整體優於 Google Veo 3.1,勝率為 247%;
- 「指令轉換」任務:O1 的表現優於 Runway Aleph,勝率為 230%。
競品概覽(功能層次對比)
| 能力/型號 | 克林 O1 | 谷歌維奧3.1 | Runway(Aleph / Gen-4.5) |
|---|---|---|---|
| 統一的多模態提示(文字+圖像+影片) | **是的(核心賣點)**單請求多模式流。 | 部分-文字→影片+參考資料存在;較少強調單一統一的MVL。 | Runway 專注於生成和編輯,但通常是作為單獨的模式;最新的 Gen-4.5 縮小了兩者之間的差距。 |
| 對話式/基於文字的像素編輯 | 可以 — 「像對話一樣編輯」(不戴口罩)。 | 部分功能-雖然存在編輯功能,但遮罩/關鍵影格工作流程仍然很常見。 | Runway 擁有強大的編輯工具;Runway 聲稱擁有強大的指令轉換功能(因版本而異)。 |
| 起始/結束畫面控制和攝影機參考 | 可以 — 明確描述了起始/結束畫面和參考攝影機運動。 | 有限/不斷發展 | Runway:改進了控制功能;使用者體驗並不完全相同。 |
| 長片段生成(高保真度) | 產品素材和社群貼文中最長可達約 2 分鐘(1080p,30fps); | Veo 3.1:一致性強,但早期版本的預設值較短;因型號/設定而異。 | Runway Gen-4.5:著重品質;長度/保真度各不相同。 |
總結:
Kling O1 的公眾成名之處在於 工作流程統一賦予單一模型理解文字、圖像和影片的能力,並在同一語義系統中執行生成和基於豐富指令的編輯操作。對於經常在「創建」、「編輯」和「擴展」步驟之間切換的創作者和團隊而言,這種整合可以顯著簡化迭代速度並降低工具的複雜性。此外,它還改進了時間一致性、起始/結束幀控制以及實用的平台集成,使創作者能夠輕鬆上手。
Kling Video o1 API 即將上線 CometAPI。
開發人員可以訪問 Kling 2.5 渦輪 Veo 3.1 API 通過 彗星API,列出的最新模型截至本文發布之日。首先,探索模型在 游乐场 並諮詢 API指南 以獲得詳細說明。造訪前請確保您已經登入CometAPI並取得API金鑰。 彗星API 提供遠低於官方價格的價格,幫助您整合。
準備出發了嗎? → 立即註冊 CometAPI !