技術詳細資訊
- 自適應推理:
Gemini 2.5 Flash-Lite支援按需思考,允許開發者僅在需要更深層推理時分配運算資源。 - 工具整合:與 Gemini 2.5 原生工具完全相容,包括 Grounding with Google Search、Code Execution、URL Context 與 Function Calling,以支援無縫的多模態工作流程。
- Model Context Protocol (MCP):利用 Google 的 MCP 擷取即時網路資料,確保回應最新且具脈絡相關性。
- 部署選項:可透過 CometAPI、Gemini API、Vertex AI 與 Google AI Studio 使用,並提供預覽通道,供早期採用者試用與回饋。
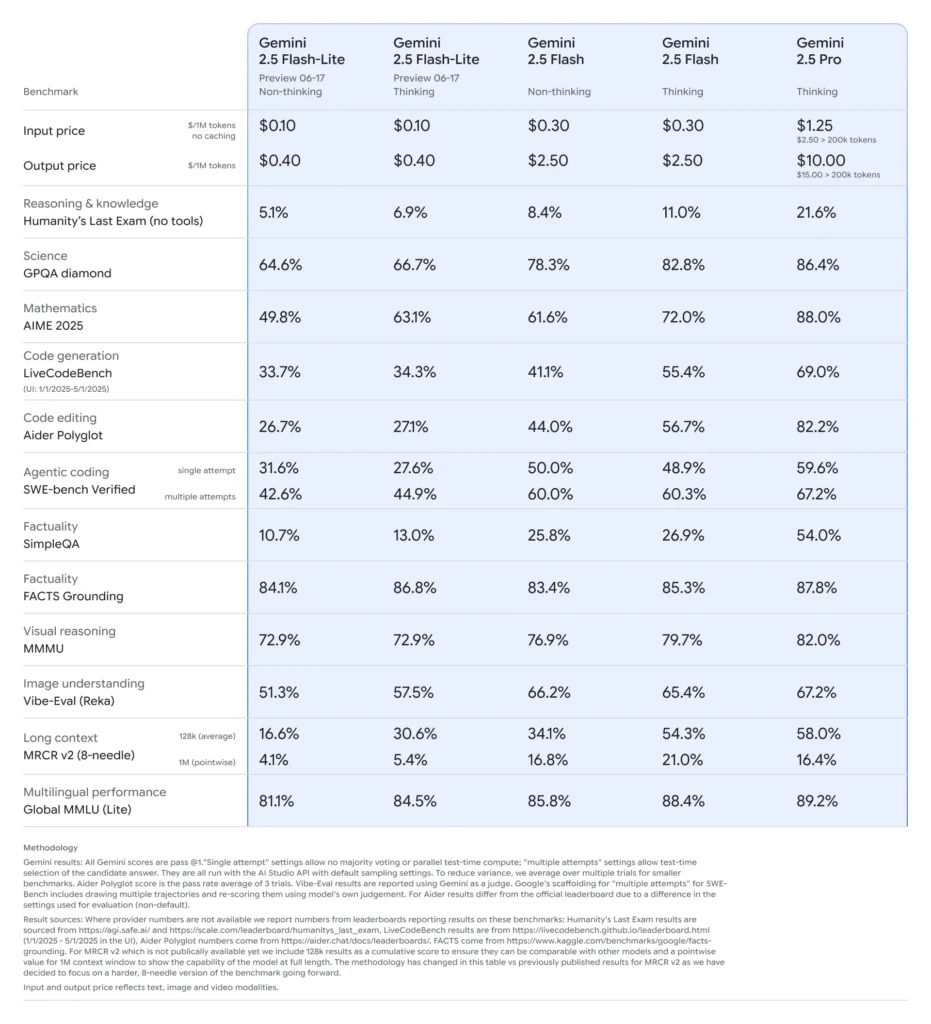
Gemini 2.5 Flash-Lite 的基準效能
- 延遲:相較於 Gemini 2.5 Flash,中位數回應時間最多降低 50%;在標準分類與摘要基準上,典型延遲低於 100 ms。
- 吞吐量:為高流量工作負載最佳化,可在每分鐘持續處理數萬個請求且不降速。
- 價格效能:相較 Flash 對應版本,每 1,000 tokens 成本降低 25%,對成本敏感部署而言是帕累托最優的選擇。
- 產業採用:早期使用者回報能無縫整合至生產管線,效能指標與初始預期一致或更佳。
理想使用情境
- 高頻、低複雜度任務: 自動標註、情緒分析與批量翻譯
- 對成本敏感的流程: 從大型文件語料中抽取資料、定期批次摘要
- 邊緣與行動情境: 當延遲至關重要但資源預算受限時
Gemini 2.5 Flash-Lite 的限制
- 預覽狀態:在 GA 前可能發生 API 變更;整合時應考量可能的版本升級。
- 不支援即時微調:無法上傳自訂權重;需依賴提示工程與系統訊息。
- 創造力較弱:為確定性、高吞吐任務而調校;不太適合開放式生成或「創意」寫作。
- 資源上限:僅能線性擴展至約 ~16 vCPU;超出後吞吐提升將趨緩。
- 多模態限制:支援影像/音訊輸入但保真度有限;不適合重度視覺或語音轉錄任務。
- 上下文視窗取捨:雖可接受最多 1 M tokens,但在該規模下的實際推論可能出現吞吐量下降。