

阿里巴巴在人工智慧領域的最新進展, Qwen3-編碼器,標誌著快速發展的人工智慧驅動軟體開發領域的一個重要里程碑。 Qwen23-Coder 於 2025 年 3 月 480 日發布,是一個開源的代理程式編碼模型,旨在自主處理複雜的程式設計任務,從生成樣板程式碼到跨整個程式碼庫進行偵錯。該模型建立在尖端的混合專家 (MoE) 架構之上,擁有 35 億個參數,每個令牌激活 3 億個參數,在性能和計算效率之間實現了最佳平衡。在本文中,我們將探討 QwenXNUMX-Coder 的獨特之處,檢視其基準效能,解析其技術創新,指導開發人員進行最佳使用,並考慮該模型的接受度和未來前景。
什麼是 Qwen3‑Coder?
Qwen3‑Coder 是 Qwen 家族最新的代理程式編碼模型,於 22 年 2025 月 3 日正式發布。其旗艦版本 Qwen480‑Coder‑35B‑A480B‑Instruct 被設計為“迄今為止最具代理性的程式碼模型”,擁有 35 億個參數,並採用混合專家 (MoE) 設計,每個標記可啟動 256 億個參數。它原生支援高達 XNUMXK 個標記的上下文窗口,並透過外推技術擴展到 XNUMX 萬個標記,從而滿足了程式碼庫規模程式碼理解和產生的需求。
Apache 2.0 下的開源
阿里巴巴秉承社區驅動開發的承諾,Qwen3-Coder 採用 Apache 2.0 授權發布。這種開源方式確保了透明度,促進了第三方貢獻,並加速了其在學術界和工業界的普及。研究人員和工程師可以存取預先訓練好的權重,並針對從金融科技到科學計算等特定領域對模型進行微調。
從Qwen2.5進化而來
Qwen2.5‑Coder 的成功源自於其強大的模型,其參數規模從 0.5 億到 32 億不等,並在程式碼產生基準測試中取得了 SOTA 的優異成績。 Qwen3‑Coder 透過更大規模、更強大的資料管線和全新的訓練機制,進一步擴展了前身的功能。 Qwen2.5‑Coder 已使用超過 5.5 兆個 token 進行訓練,並進行了細緻的資料清理和合成資料產生;Qwen3‑Coder 則進一步提升了這項能力,它以 7.5% 的程式碼率提取了 70 兆個 token,並利用先前的模型過濾和重寫資料輸入,從而獲得卓越的雜訊品質。
Qwen3-Coder 的主要創新點是什麼?
幾項關鍵創新使 Qwen3-Coder 脫穎而出:
- 代理任務編排:Qwen3-Coder 不僅可以產生程式碼片段,還可以自主地將多個操作(讀取文件、呼叫實用程式和驗證輸出)連結在一起,無需人工幹預。
- 增強思維預算:開發人員可以配置每個推理步驟所需的計算量,從而實現速度和徹底性之間的可自訂權衡,這對於大規模程式碼合成至關重要。
- 無縫工具集成:Qwen3-Coder 的命令列介面「Qwen Code」採用函數呼叫協定和自訂提示,以便與流行的開發人員工具集成,從而可以輕鬆嵌入現有的 CI/CD 管道和 IDE 中。
與競爭對手相比,Qwen3‑Coder 的表現如何?
基準測試對決
根據阿里巴巴公佈的性能指標,Qwen3-Coder 的表現優於國內領先的同類產品,例如 DeepSeek 的 codex 風格模型和 Moonshot AI 的 K2,並且在多項基準測試中達到或超過了美國頂級產品的編碼能力。在第三方評估中:
- 艾德多語者: Qwen3-Coder-480B 的得分為 61.8%,說明強大的多語言程式碼產生和推理。
- MBPP 和 HumanEval:獨立測試報告顯示,Qwen3-Coder-480B-A35B 在功能正確性和複雜提示處理方面均優於 GPT-4.1,尤其是在多步驟編碼挑戰中。
- 480B 參數變體在 SWE-Bench 已驗證套件——超越 DeepSeek 的頂級模型(78%)和 Moonshot 的 K2(82%),並與 Claude Sonnet 4 的 86% 非常接近。
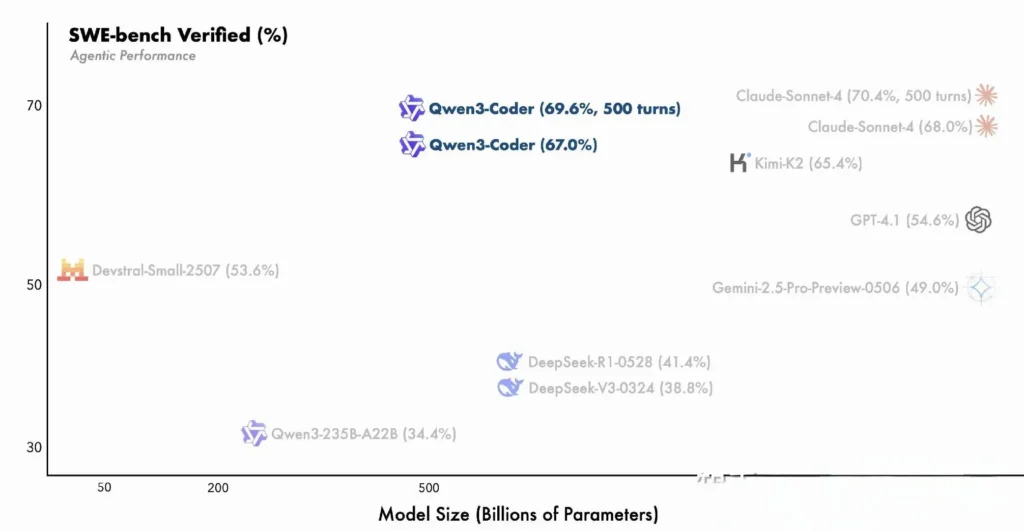
與專有模型的比較
阿里巴巴聲稱,Qwen3-Coder 的代理能力在端到端編碼工作流程中與 Anthropic 的 Claude 和 OpenAI 的 GPT-4 相媲美,這對於一個開源模型來說是一項非凡的成就。早期測試人員報告稱,其多輪規劃、動態工具呼叫和自動糾錯功能可以在極少的人工提示下處理複雜的任務,例如建立全端 Web 應用程式或整合 CI/CD 管線。這些能力得益於該模型透過程式碼執行進行自我驗證的能力,而這項特性在純生成式 LLM 中並不那麼明顯。
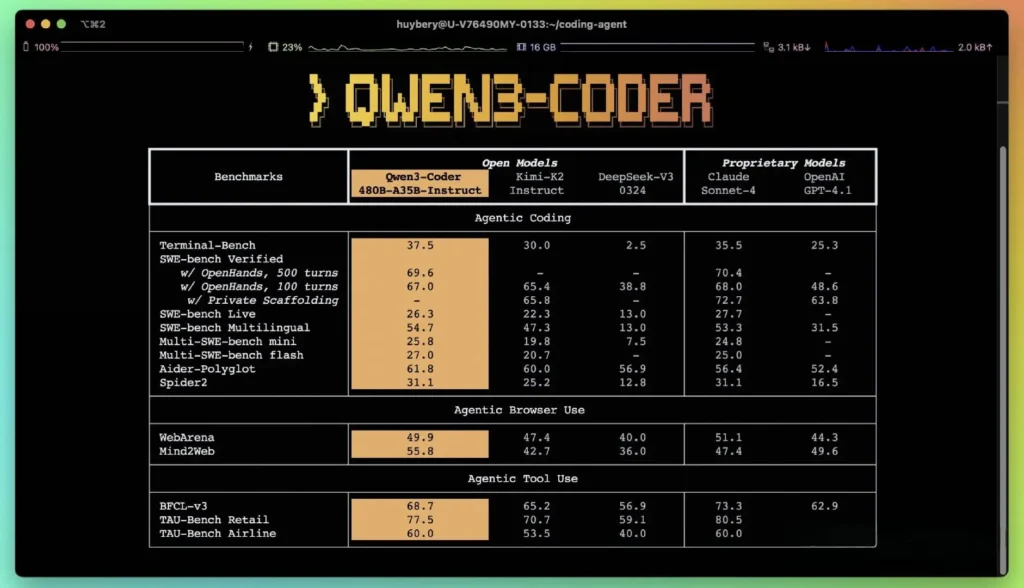
Qwen3-Coder 背後的技術創新是什麼?
混合專家(MoE)架構
Qwen3‑Coder 的核心在於其先進的 MoE 設計。與為每個 token 啟動所有參數的密集模型不同,MoE 架構會選擇性地啟用針對特定 token 類型或任務自訂的專用子網路(專家)。在 Qwen3‑Coder 中,總共 480 億個參數分佈在多個專家模型中,每個 token 僅啟動 35 億個參數。與同等密集模型相比,此方法可將推理成本降低 60% 以上,同時保持程式碼合成和除錯的高保真度。
思考模式與非思考模式
借鑒 Qwen3 系列的創新,Qwen3‑Coder 整合了 雙模式推理 框架:
- 思維模式 為演算法設計或跨文件重構等複雜、多步驟的推理任務分配更大的「思考預算」。
- 非思考模式 提供快速、情境驅動的回應,適用於簡單的程式碼完成和 API 使用片段。
這種統一的模式切換消除了針對聊天最佳化任務和推理最佳化任務分別調整模型的需要,從而簡化了開發人員的工作流程。
強化學習與自動測試用例合成
Qwen3-Coder 的一項突出創新是其原生 256K 令牌上下文視窗——是領先開放模型典型容量的兩倍——並且透過外推方法(例如 YaRN)支援多達一百萬個令牌。這使得該模型能夠一次處理整個儲存庫、文件集或多文件項目,從而保留跨文件依賴關係並減少重複提示。實證測試表明,情境視窗擴展對長期任務表現的提升雖然遞減,但仍具有顯著意義,尤其是在環境驅動的強化學習場景中。
開發人員如何存取和使用 Qwen3‑Coder?
Qwen3-Coder 的發布策略強調開放性和易於採用:
- 開源模型權重:所有模型檢查點均可在 Apache 2.0 下的 GitHub 上取得,從而實現完全透明度和社群驅動的增強功能。
- 命令列介面(Qwen 程式碼):從 Google Gemini Code 分叉而來,CLI 支援自訂提示、函數呼叫和插件架構,以便與現有的建置系統和 IDE 無縫整合。
- 雲端和本地部署:預先配置的 Docker 映像和 Kubernetes Helm 圖表有助於在雲端環境中實現可擴展部署,而本地量化方案(2-8 位元動態量化)即使在商用 GPU 上也能實現高效的本地推理。
- 透過 CometAPI 存取 API:開發人員還可以透過平台上的託管端點與 Qwen3-Coder 進行交互,例如 彗星API,提供開源(
qwen3-coder-480b-a35b-instruct) 和商業版本(qwen3-coder-plus; qwen3-coder-plus-2025-07-22)價格相同。商業版本長度為1M。 - 擁抱臉:阿里巴巴已在 Hugging Face 和 GitHub 上免費提供 Qwen3-Coder 權重和配套庫,這些庫採用 Apache 2.0 許可證打包,允許學術和商業使用而無需支付版稅。
透過 CometAPI 整合 API 和 SDK
CometAPI 是一個統一的 API 平台,它將來自領先供應商(例如 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等)的 500 多個 AI 模型聚合到一個開發者友好的介面中。透過提供一致的身份驗證、請求格式和回應處理,CometAPI 顯著簡化了將 AI 功能整合到您的應用程式中的過程。無論您是建立聊天機器人、影像產生器、音樂作曲家,還是資料驅動的分析流程,CometAPI 都能讓您更快地迭代、控製成本,並保持與供應商的兼容性——同時也能充分利用整個 AI 生態系統的最新突破。
開發人員可以與 Qwen3-編碼器 透過相容的 OpenAI 風格 API(可透過 CometAPI 取得)。 彗星API,提供開源(qwen3-coder-480b-a35b-instruct) 和商業版本(qwen3-coder-plus; qwen3-coder-plus-2025-07-22價格相同。商業版本長度為 1M。 Python 範例程式碼(使用相容 OpenAI 的客戶端)的最佳實務建議採樣設定為:溫度 = 0.7、top_p = 0.8、top_k = 20 和重複懲罰 = 1.05。輸出長度最多可擴展至 65,536 個 token,適用於大型程式碼產生任務。
首先,探索模型在 游乐场 並諮詢 API指南 以獲得詳細說明。造訪前請確保您已經登入CometAPI並取得API金鑰。
Hugging Face 和阿里雲端快速入門
渴望嘗試 Qwen3‑Coder 的開發人員可以在儲存庫下的 Hugging Face 上找到該模型 Qwen/Qwen3‑Coder‑480B‑A35B‑Instruct. 透過以下方式簡化集成 transformers 庫(版本≥4.51.0以避免 KeyError: 'qwen3_moe') 以及相容於 OpenAI 的 Python 用戶端。一個簡單的例子:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
input_ids = tokenizer("def fibonacci(n):", return_tensors="pt").input_ids
output = model.generate(input_ids, max_length=200, temperature=0.7, top_p=0.8, top_k=20, repetition_penalty=1.05)
print(tokenizer.decode(output))
定義自訂工具和代理程式工作流程
Qwen3‑Coder 的傑出特色之一是 動態工具調用開發人員可以註冊外部實用程式(例如程式碼檢查器、格式化程式和測試運行器),並允許模型在編碼會話期間自主呼叫它們。此功能將 Qwen3-Coder 從被動的程式碼助理轉變為主動的編碼代理,能夠運行測試、調整程式碼風格,甚至根據對話意圖部署微服務。
Qwen3-Coder 支援哪些潛在的應用和未來發展方向?
Qwen3-Coder 將開源自由與企業級效能相結合,為新一代 AI 驅動的開發工具鋪平了道路。從自動化程式碼審計和安全合規性檢查,到持續重構服務和 AI 驅動的開發維運助手,該模型的多功能性已激勵新創公司和內部創新團隊。
軟體開發工作流程
早期採用者報告稱,樣板程式碼編寫、依賴關係管理和初始鷹架搭建的時間減少了 30% 到 50%,使工程師能夠專注於高價值的設計和架構任務。持續整合套件可利用 Qwen3-Coder 自動產生測試、偵測回歸,甚至基於即時程式碼分析提出效能最佳化建議。
企業參與
隨著金融、醫療保健和電子商務等領域的公司將 Qwen3-Coder 整合到關鍵任務系統中,用戶團隊與阿里巴巴研發團隊之間的反饋循環將加速改進,例如針對特定領域的調優、增強的安全協議以及更嚴格的 IDE 插件。此外,阿里巴巴的開源策略鼓勵全球社群的貢獻,從而打造一個充滿活力的擴展、基準測試和最佳實踐庫生態系統。
結論
總而言之,Qwen3-Coder 代表了軟體工程開源 AI 領域的一個里程碑:一個強大的代理模型,它不僅可以編寫程式碼,還能在極少的人工監督下協調整個開發流程。透過免費提供這項技術並使其易於集成,阿里巴巴正在實現先進 AI 工具的民主化,並為軟體開發日益協作、高效和智慧化的時代奠定基礎。
常見問題
是什麼讓 Qwen3‑Coder 具有「代理性」?
代理型人工智慧 (Agentic AI) 是指能夠自主規劃和執行多步驟任務的模型。 Qwen3-Coder 無需人工幹預即可呼叫外部工具、執行測試和管理程式碼庫,這充分體現了這種模式。
Qwen3-Coder 適合生產使用嗎?
雖然 Qwen3‑Coder 在基準測試和實際測試中表現出色,但企業在將其整合到關鍵生產工作流程之前,應該進行特定領域的評估並實施防護措施(例如,輸出驗證管道)。
Mixture‑of‑Experts 架構如何讓開發人員受益?
透過僅激活每個令牌的相關子網絡,MoE 可以降低推理成本,從而實現更快的生成速度並降低計算成本。這種效率對於在雲端環境中擴展 AI 編碼助理至關重要。