
Qwen3-Max-Preview 是阿里巴巴 Qwen3 系列的最新旗艦預覽模型——一個擁有萬億以上參數、混合專家 (MoE) 風格的模型,擁有超長的 262k 令牌上下文窗口,目前已發布預覽版,供企業/雲端使用。它的目標客戶是 *深度推理、長文檔理解、編碼和代理工作流程.
基本資訊和標題特徵
- 名稱/標籤:
qwen3-max-preview(指示)。 - 規模: 超過 1 兆個參數 (萬億參數旗艦)。這是該版本的關鍵行銷/統計里程碑。
- 上下文視窗: 262,144令牌 (支援非常長的輸入和多文件記錄)。
- 模式: 指令調整的“Instruct”變體,支持 思維 (深思熟慮的思路)和 不思考 Qwen3 系列中的快速模式。
- 庫存: 透過預覽訪問 Qwen聊天, 阿里雲模型工作室 (OpenAI 相容或 DashScope 端點)和路由供應商,例如 彗星API.
技術細節(架構和模式)
- 建築: Qwen3-Max 沿襲了 Qwen3 的設計風格,採用了多種 密集+混合專家(MoE) 更大變體中的組件,加上工程選擇以優化非常大的參數計數的推理效率。
- 思考模式 vs 非思考模式: Qwen3系列推出了 思維模式 (用於多步驟思路鍊輸出)和 非思考模式 為了獲得更快、更簡潔的回應;平台公開了參數來切換這些行為。
- 上下文快取/效能特點: 模型工作室列表 上下文快取 支援大型請求以減少重複輸入成本並提高重複上下文的吞吐量。
基準性能
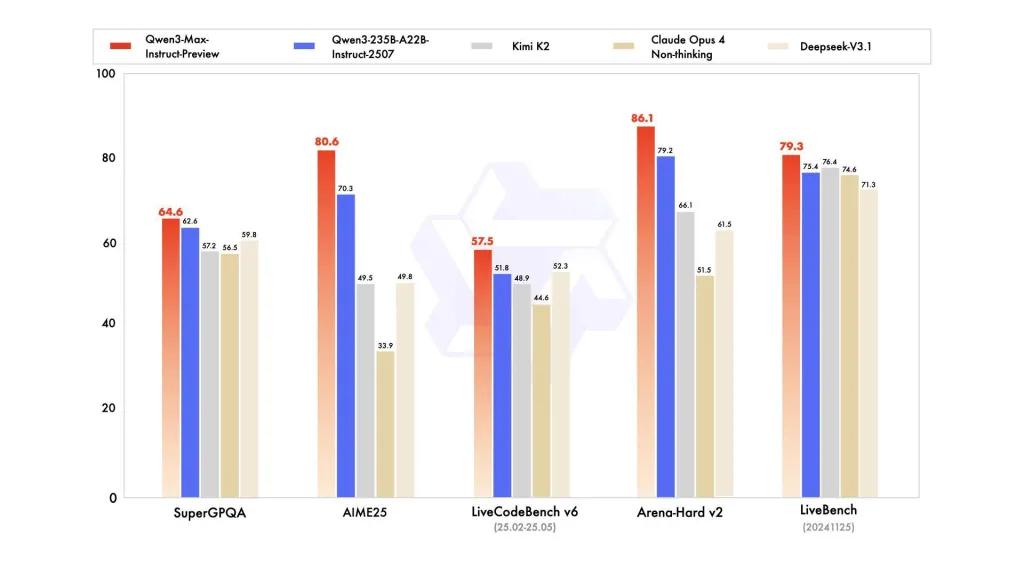
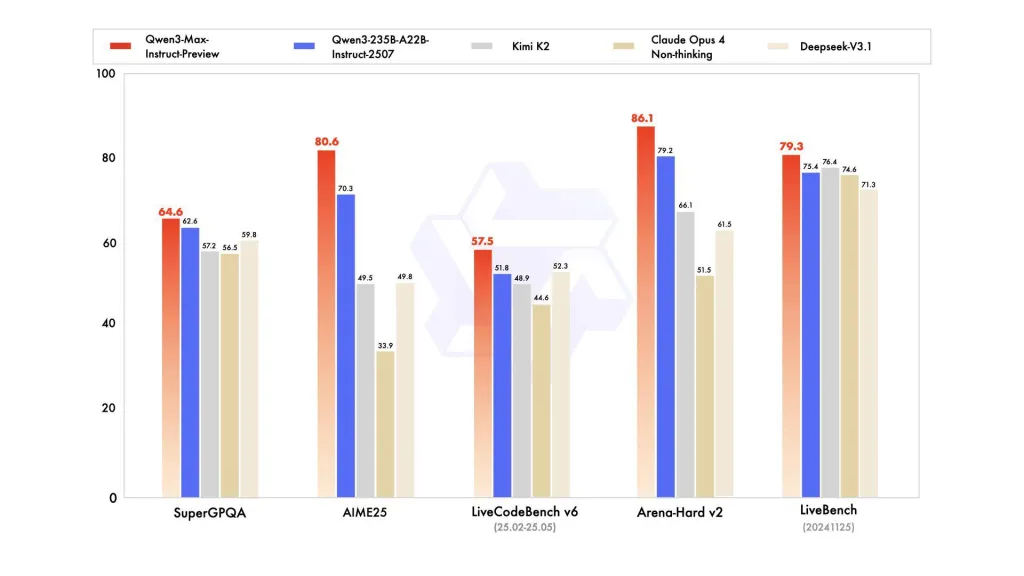
報告參考了 SuperGPQA、LiveCodeBench 變體、AIME25 和其他競賽/基準套件,其中 Qwen3-Max 看起來具有競爭力或領先地位。
限制和風險(實用和安全說明)
- 完整訓練方案/權重的不透明度: 作為預覽版,與早期開放重量版 Qwen3 相比,完整的訓練/資料/權重發布和可重現性資料可能有限。部分 Qwen3 系列車型已開放重量版發布,但 Qwen3-Max 以受控預覽版的形式交付,僅供雲端存取。 降低可重複性 適合獨立研究人員。
- 幻覺與事實: 供應商報告聲稱幻覺減少,但實際使用中仍會發現事實錯誤和過度自信的斷言——適用標準法學碩士(LLM)注意事項。在高風險部署之前,必須進行獨立評估。
- 規模成本: 憑藉巨大的上下文視窗和強大的功能, 代幣成本 對於非常長的提示或生產吞吐量來說,這可能非常重要。使用快取、分塊和預算控制。
- 監理和數據主權考量: 企業用戶在處理敏感資訊之前,應檢查阿里雲區域、資料駐留及合規性影響。 (Model Studio 文件包含特定區域的端點和說明。)
使用場景
- 大規模文件理解/總結: 法律摘要、技術規格和多文件知識庫(優勢: 262K 代幣 窗戶)。
- 長上下文程式碼推理和儲存庫規模碼輔助: 多文件程式碼理解、大型 PR 審查、儲存庫層級重構建議。
- 複雜推理與思路鏈任務: 數學競賽、多步驟規劃、代理工作流程,其中「思考」痕跡有助於可追溯性。
- 多語言、企業問答和結構化資料擷取: 大型多語言語料庫支援和結構化輸出能力(JSON/表格)。
如何從 CometAPI 呼叫 Qqwen3-max-preview API
qwen3-max-preview CometAPI 中的 API 定價,比官方價格便宜 20%:
| 輸入令牌 | $0.24 |
| 輸出代幣 | $2.42 |
所需步驟
- 登錄到 cometapi.com。如果您還不是我們的用戶,請先註冊
- 取得介面的存取憑證API key。在個人中心的API token處點選“新增Token”,取得Token金鑰:sk-xxxxx並提交。
- 取得此網站的 URL: https://api.cometapi.com/
使用方法
- 選擇「qwen3-max-preview」端點發送API請求並設定請求體。請求方法和請求體可從我們官網API文件取得。為了方便您使用,我們官網也提供了Apifox測試。
- 代替使用您帳戶中的實際 CometAPI 金鑰。
- 將您的問題或請求插入內容欄位 - 這是模型將會回應的內容。
- 。處理 API 回應以取得產生的答案。
API調用
CometAPI 提供完全相容的 REST API,以實現無縫遷移。關鍵細節如下: API 文件:
- 核心參數:
prompt,max_tokens_to_sample,temperature,stop_sequences - 終點:
https://api.cometapi.com/v1/chat/completions - 模型參數: qwen3-max-預覽
- 驗證:
Bearer YOUR_CometAPI_API_KEY - 內容類型:
application/json.
更換
CometAPI_API_KEY用你的鑰匙;注意 基本 URL.
Python(請求)-與 OpenAI 相容
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
小提示: 使用 max_input_tokens, max_output_tokens以及 Model Studio 的 上下文快取 發送非常大的上下文時的功能來控製成本和吞吐量。
參見 Qwen3-編碼器