

在 2025 年 11 月 19–20 日,OpenAI 發布了兩項彼此相關但不同的升級:GPT-5.1-Codex-Max,這是一款面向 Codex 的新型代理式程式設計模型,強調長時程程式設計、token 效率,以及用於維持多視窗工作階段的「compaction」;以及 GPT-5.1 Pro,這是更新後的 Pro 級 ChatGPT 模型,針對複雜、專業工作中更清晰且更有能力的回答進行了調校。
什麼是 GPT-5.1-Codex-Max,它試圖解決什麼問題?
GPT-5.1-Codex-Max 是 OpenAI 推出的專用 Codex 模型,針對需要持續、長時程推理與執行的程式設計工作流程進行了調校。一般模型在面對極長上下文時可能會出現問題——例如多檔案重構、複雜的代理迴圈,或持續性的 CI/CD 任務——而 Codex-Max 則被設計為可自動壓縮並管理跨多個上下文視窗的工作階段狀態,讓它在單一專案跨越數千個(甚至更多)token 時,仍能連貫地持續工作。OpenAI 將 Codex-Max 定位為讓具備程式能力的代理真正能用於長時間工程工作的下一步。
什麼是 GPT-5.1-Codex-Max,它試圖解決什麼問題?
GPT-5.1-Codex-Max 是 OpenAI 推出的專用 Codex 模型,針對需要持續、長時程推理與執行的程式設計工作流程進行了調校。一般模型在面對極長上下文時可能會出現問題——例如多檔案重構、複雜的代理迴圈,或持續性的 CI/CD 任務——而 Codex-Max 則被設計為可自動壓縮並管理跨多個上下文視窗的工作階段狀態,讓它在單一專案跨越數千個(甚至更多)token 時,仍能連貫地持續工作。
OpenAI 將其描述為「在開發週期的每個階段都更快、更智慧、且更具 token 效率」,並明確表示其目的是取代 GPT-5.1-Codex,成為 Codex 各使用介面的預設模型。
功能概覽
- 用於多視窗連續性的 compaction: 修剪並保留關鍵上下文,以便在數百萬 token 與數小時的工作中保持連貫。0
- 相較 GPT-5.1-Codex 有更高的 token 效率: 在某些程式基準測試中,以相近的推理工作量可減少約 ~30% 的 thinking tokens。
- 長時程代理式耐久性: 內部觀察顯示可持續多小時/多天的代理迴圈(OpenAI 記錄了超過 24 小時的內部執行)。
- 平台整合: 現已可在 Codex CLI、IDE 擴充套件、雲端與程式碼審查工具中使用;API 存取即將推出。
- Windows 環境支援: OpenAI 特別指出,Windows 首次在 Codex 工作流程中獲得支援,擴大了真實世界開發者的覆蓋範圍。
它與競品(例如 GitHub Copilot、其他程式設計 AI)相比如何?
與按請求補全的工具相比,GPT-5.1-Codex-Max 被定位為更具自主性、能處理長時程工作的協作者。雖然 Copilot 與類似助手擅長編輯器內的短期補全,但 Codex-Max 的優勢在於協調多步驟任務、跨工作階段維持連貫狀態,以及處理需要規劃、測試與迭代的工作流程。不過,對多數團隊來說,最佳方式通常是混合使用:以 Codex-Max 處理複雜自動化與持續性的代理任務,並以較輕量的助手進行逐行補全。
GPT-5.1-Codex-Max 如何運作?
什麼是「compaction」,它如何支援長時間工作?
其核心技術進展之一是 compaction——這是一種內部機制,可在保留關鍵上下文內容的同時修剪工作階段歷史,讓模型得以跨多個上下文視窗持續進行連貫工作。實際上,這表示當 Codex 工作階段接近上下文限制時,系統會進行壓縮(將較舊或較低價值的 token 摘要化/保留),讓代理擁有新的視窗,並可反覆持續迭代直到任務完成。OpenAI 表示,內部執行中曾有模型連續工作超過 24 小時。
自適應推理與 token 效率
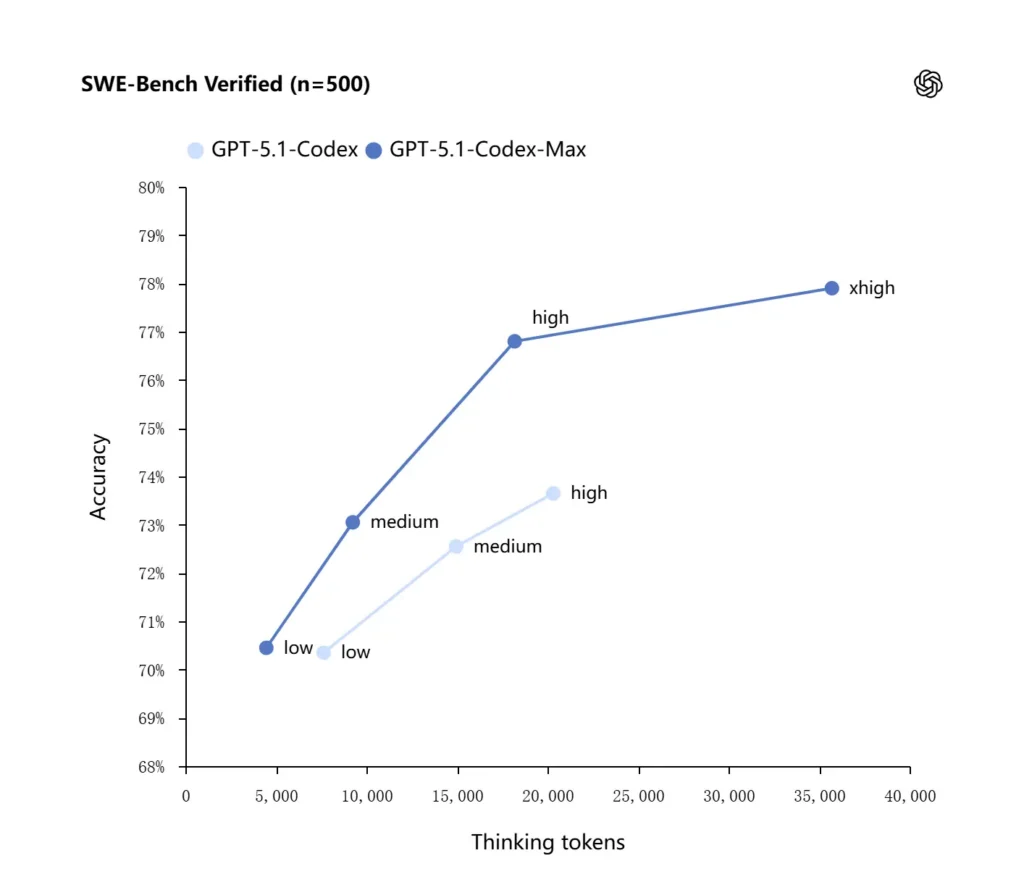
GPT-5.1-Codex-Max 採用了改良的推理策略,使其更具 token 效率:在 OpenAI 公布的內部基準中,Max 模型在使用顯著更少「thinking」tokens 的情況下,能達到與 GPT-5.1-Codex 相當或更好的表現——OpenAI 指出,在相同推理投入下執行 SWE-bench Verified 時,thinking tokens 約可減少 30%。該模型也引入了「Extra High(xhigh)」推理投入模式,適用於對延遲不敏感的任務,允許它投入更多內部推理以獲得更高品質輸出。
系統整合與代理式工具
Codex-Max 正透過 Codex 工作流程(CLI、IDE 擴充套件、雲端與程式碼審查介面)進行發佈,讓它能與真實的開發者工具鏈互動。早期整合包括 Codex CLI 與 IDE 代理(VS Code、JetBrains 等),API 存取預計之後推出。其設計目標不只是更聰明的程式碼生成,而是一個能執行多步驟工作流程的 AI:開啟檔案、執行測試、修復失敗、重構,然後重新執行。
GPT-5.1-Codex-Max 在基準測試與實際工作中的表現如何?
持續推理與長時程任務
評估顯示,它在持續推理與長時程任務上有可衡量的改善:
- OpenAI 內部評估: Codex-Max 在內部實驗中可於任務上持續工作「超過 24 小時」,且將 Codex 與開發者工具整合後,提高了內部工程生產力指標(例如使用量與 pull request 產出量)。這些是 OpenAI 的內部說法,顯示其在真實世界生產力上的任務層級改善。
- 獨立評估(METR): METR 的獨立報告測得 GPT-5.1-Codex-Max 的觀察到的 50% 時間跨度(代表模型可連貫維持長任務的中位時間的統計值)約為 2 小時 40 分鐘(信賴區間較寬),高於 GPT-5 在可比測量中的 2 小時 17 分鐘——這是持續連貫性方面有意義且符合趨勢的提升。METR 的方法與信賴區間強調了變異性,但結果支持了 Codex-Max 提升實務長時程表現的敘事。
程式碼基準測試
OpenAI 表示,其在前沿程式設計評估中取得了更好的結果,尤其是在 SWE-bench Verified 上,GPT-5.1-Codex-Max 以更佳的 token 效率超越 GPT-5.1-Codex。公司強調,在相同的「medium」推理投入下,Max 模型能產生更好的結果,同時使用少約 30% 的 thinking tokens;對於允許更長內部推理的使用者,xhigh 模式可進一步提升答案品質,但代價是延遲增加。
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
GPT-5.1-Codex-Max 與 GPT-5.1-Codex 相比如何?
效能與用途差異
- 範圍: GPT-5.1-Codex 是 GPT-5.1 系列中的高效能程式設計變體;Codex-Max 則明確是一個代理式、長時程的後繼模型,旨在成為 Codex 與類 Codex 環境中的建議預設選項。
- token 效率: Codex-Max 在 SWE-bench 與內部使用中展現出顯著的 token 效率提升(OpenAI 宣稱約減少 ~30% 的 thinking tokens)。
- 上下文管理: Codex-Max 引入了 compaction 與原生多視窗處理能力,以支撐超出單一上下文視窗的任務;Codex 過去並未以相同規模原生提供這種能力。
- 工具鏈就緒度: Codex-Max 作為 Codex 在 CLI、IDE 與程式碼審查介面中的預設模型發佈,顯示其正遷移到生產級開發者工作流程。
何時使用哪個模型?
- 使用 GPT-5.1-Codex:適合互動式程式設計協助、快速修改、小型重構,以及所有相關上下文都能輕鬆放入單一視窗的低延遲使用情境。
- 使用 GPT-5.1-Codex-Max:適合多檔案重構、需要多輪迭代的自動化代理任務、類 CI/CD 工作流程,或需要模型在多次互動中維持專案層級視角的情況。
實用提示模式,以及如何取得最佳效果的範例?
效果良好的提示模式
- 明確說明目標與限制:「重構 X、保留公開 API、維持函式名稱不變,並確保測試 A、B、C 通過。」
- 提供最小可重現上下文: 連結到失敗的測試、附上堆疊追蹤,以及相關檔案片段,而不是直接傾倒整個儲存庫。Codex-Max 會在需要時壓縮歷史。
- 對複雜任務使用分步指示: 將大型工作拆成一系列子任務,並讓 Codex-Max 逐步迭代處理(例如:「1) 執行測試 2) 修復最上面的 3 個失敗測試 3) 執行 linter 4) 摘要變更」)。
- 要求解釋與 diff: 同時要求 patch 與簡短理由,讓人工審查者能快速評估安全性與意圖。
範例提示模板
重構任務
「將
payment/模組重構,把付款處理提取到payment/processor.py。對現有呼叫端保持公開函式簽名不變。為process_payment()建立單元測試,涵蓋成功、網路失敗與無效信用卡。執行測試套件,並以 unified diff 格式回傳失敗測試與 patch。」
除錯 + 測試
「測試
tests/test_user_auth.py::test_token_refresh因 traceback 而失敗。調查根本原因,提出最小變更的修復方案,並新增一個單元測試以防止回歸。套用 patch 並執行測試。」
迭代式 PR 產生
「實作功能 X:新增會串流匯出結果且需驗證身分的端點
POST /api/export。建立該端點、加入文件、建立測試,並開啟一個附有摘要與手動事項檢查清單的 PR。」
對大多數這類任務,請先從 medium 投入開始;當你需要模型跨多個檔案與多輪測試迭代進行深度推理時,再切換到 xhigh。
如何存取 GPT-5.1-Codex-Max
目前可用的位置
OpenAI 現已將 GPT-5.1-Codex-Max 整合進 Codex 工具鏈:Codex CLI、IDE 擴充套件、雲端與程式碼審查流程預設都使用 Codex-Max(你也可以選擇 Codex-Mini)。API 可用性仍在準備中;GitHub Copilot 也已有包含 GPT-5.1 與 Codex 系列模型的公開預覽。
開發者可以透過 CometAPI 存取 GPT-5.1-Codex-Max 與 GPT-5.1-Codex API。若要開始使用,請在 Playground 中探索 CometAPI 的模型能力,並查閱 API guide 以取得詳細說明。在存取之前,請務必確認你已登入 CometAPI 並取得 API key。CometAPI 提供遠低於官方價格的價格,協助你進行整合。
準備好了嗎?→ 立即註冊 CometAPI!
如果你想了解更多 AI 的技巧、指南與新聞,請在 VK、X 與 Discord 上追蹤我們!
快速開始(實用逐步指南)
- 確認你具有存取權限: 確認你的 ChatGPT/Codex 產品方案(Plus、Pro、Business、Edu、Enterprise)或你的開發者 API 方案支援 GPT-5.1/Codex 系列模型。
- 安裝 Codex CLI 或 IDE 擴充套件: 若你想在本機執行程式碼任務,請安裝 Codex CLI,或安裝適用於 VS Code / JetBrains / Xcode 的 Codex IDE 擴充套件。在受支援的設定中,該工具鏈預設會使用 GPT-5.1-Codex-Max。
- 選擇推理投入: 大多數任務先使用 medium 投入即可。對於深度除錯、複雜重構,或你希望模型進行更深入思考且不在意回應延遲時,可切換到 high 或 xhigh 模式。對於快速的小修正,low 也很合理。
- 提供儲存庫上下文: 給模型一個清楚的起點——例如 repo URL,或一組檔案加上一段簡短指示(例如:「將 payment 模組重構為使用 async I/O,並新增單元測試,保持函式層級契約不變」)。當接近上下文限制時,Codex-Max 會壓縮歷史並持續完成工作。
- 透過測試迭代: 在模型產生 patch 後,執行測試套件,並將失敗結果作為持續工作階段的一部分回饋給模型。compaction 與多視窗連續性讓 Codex-Max 能保留重要的失敗測試上下文並持續迭代。
結論:
GPT-5.1-Codex-Max 代表代理式程式設計助手邁向可持續處理複雜、長時間工程任務的重要一步,並具備更佳的效率與推理能力。其技術進展(compaction、推理投入模式、Windows 環境訓練)使其特別適合現代工程組織——前提是團隊需搭配保守的操作控制、明確的人類在迴圈中政策,以及健全的監控機制。對於謹慎採用它的團隊而言,Codex-Max 有潛力改變軟體的設計、測試與維護方式——將重複、繁瑣的工程勞務轉化為人類與模型之間更高價值的協作。