

Gemini Embedding 2 是 Google 的首個原生多模態嵌入模型,可將文字、圖片、音訊、影片與 PDF 映射到單一的 3,072 維語意向量空間(輸出大小可配置)。它引入 Matryoshka Representation Learning,提供巢狀/截斷嵌入、改進的多語言效能(100+ 種語言),以及針對任務的嵌入優化控制(例如,task:search、task:code)。
什麼是 Gemini Embedding 2?
Gemini Embedding 2 是 Google 推出的統一嵌入模型,能將多種輸入模態——文字、圖片、音訊、影片與文件——映射到同一個語意向量空間。每個嵌入(預設)是一個 3,072 維的浮點向量,用以表示輸入的語意,使得在向量空間中語意相近的項目(無論模態)彼此接近。其核心能力包括:
- 廣泛的語言與格式覆蓋:單一模型即可接受文字、圖片、音訊、影片與文件,並將其置於同一語意向量空間。Gemini Embedding 2 文件指出可捕捉超過 100+ 種語言的語意意圖,並接受常見檔案格式(PNG/JPEG、MP4/MOV、MP3/WAV、PDF),且具體標示每次請求的限制(例如,每次請求最多數張圖片或數十秒的音訊/影片——見下文「How to use」)。
- 真正的多模態:單一模型即可接受文字、圖片、音訊、影片與文件,並將其置於同一語意向量空間,因此可直接進行跨模態比較或擷取(例如,文字→圖片、音訊→文字)。
- 大型預設維度且可彈性截斷:模型預設輸出為3072 維向量,並使用Matryoshka Representation Learning (MRL),將最重要的語意集中在前面維度,因此可截斷為 1536、768(或更低)且只在檢索品質上有溫和下降,藉此在儲存與運算成本間取得平衡。
為何重要。 傳統上,嵌入多為僅支援文字,或需要為每種模態使用獨立編碼器與複雜的跨模態對齊層。Gemini Embedding 2 藉由原生支援多種格式移除這個障礙——讓文字查詢可直接依語意相似度擷取圖片或短片,而不需中介轉錄或人工對齊。這使 RAG(檢索增強生成)、語意搜尋與多模態檢索流程更簡化。
主要特性與能力(新內容)
1. 真正原生的多模態(單一嵌入空間)
單一模型即可接受文字、圖片、音訊、影片與文件,並將其置於同一語意向量空間。Gemini Embedding 2 將文字、圖片、音訊、影片與文件映射到相同的嵌入空間,讓跨模態檢索(文字→圖片、音訊→文字)無需跨模型對齊即可直接運作。這降低了管線複雜度,簡化了 RAG(檢索增強生成)堆疊。
2. 預設 3,072 維向量,輸出可調
Gemini Embedding 2 預設輸出3072 維向量,並使用Matryoshka Representation Learning (MRL),將最關鍵的語意集中於前面維度,因此可截斷為 1536、768(或更低)而僅帶來溫和的品質下降,從而在儲存與運算成本間做取捨。
3. Matryoshka Representation Learning (MRL)
MRL 產生「巢狀」嵌入——如同俄羅斯娃娃——使較低維的切片仍能保留較高階的語意。這讓系統可根據儲存/準確度取捨,選擇運行點,而無需維護多個獨立的嵌入模型。早期部落格分析與文件將此技術描述為彈性上的核心創新。
4. 任務提示/客製化嵌入目標
API 接受 task 提示(例如,task:search、task:code retrieval、task:semantic-similarity),可針對特定下游關係最佳化嵌入幾何結構——類似於早期嵌入系統的任務條件化,但擴展到多模態輸入。
5. 語言與模態廣度
Gemini Embedding 2 文件指出可捕捉超過 100+ 種語言的語意意圖,並接受常見檔案格式(PNG/JPEG、MP4/MOV、MP3/WAV、PDF),且具體標示每次請求的限制(例如,每次請求最多數張圖片或數十秒的音訊/影片——見下文「How to use」)。
效能基準
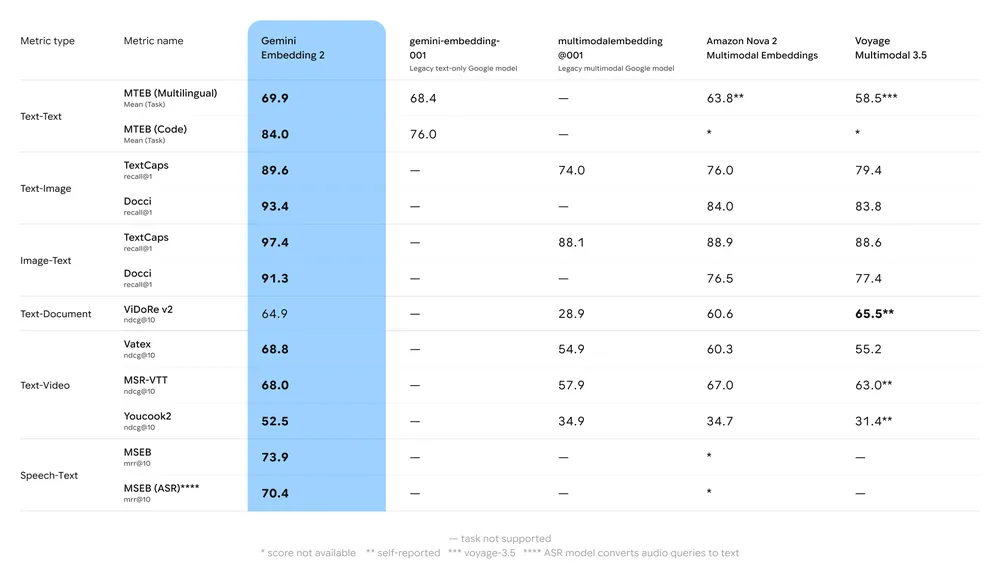
基準重點摘要:
- MTEB(Massive Text Embedding Benchmark):在英文與多語任務的 MTEB 排行上有強勢表現;分析顯示相較於先前的 Gemini 嵌入模型與多款專有替代方案有明顯提升。
- 多模態檢索:用於跨模態相似度(例如文字→圖片檢索)時,因原生多模態訓練而優於或匹配領先的單模態嵌入。
- 延遲與吞吐量:雲端託管的嵌入生成,但對延遲敏感的用例可能更偏好截斷向量或替代的輕量嵌入模型以滿足裝置端需求。
Gemini Embedding 2 vs gemini-embedding-001 and text-embedding-3-large
| Attribute | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Release / availability | Mar 10, 2026 — public preview (Gemini API / Vertex AI). | Earlier Gemini embedding (text-only variants) — GA earlier. | Announced Jan 2024 (text-only GA). |
| Modalities supported | Text, images, audio, video, documents (PDF) — unified vector space. | Text (primarily). | Text only (high-quality multilingual). |
| Default embedding dim. | 3072 (MRL / truncation recommended: 1536, 768). | 3072 (for large) — text only. | 3072 (text-embedding-3-large). |
| Reported MTEB (example) | High-60s on MTEB; shows 68.17 at 1536 in vendor table (see docs). | gemini-embedding-001 reported ~68.32 mean in some leaderboards. | ~64.6 (MTEB average reported by OpenAI for text-embedding-3-large). |
| Native audio/video support | Yes (direct audio/video embedding). | No (text only). | No (text only). |
| Typical use cases | Multimodal retrieval, RAG, semantic search across file types, speech retrieval, video search. | Text retrieval, multilingual RAG. | Text retrieval, semantic search, RAG — strong multilingual text performance. |
技術規格與限制
預設與可調的嵌入大小
- 預設: 3,072 維。
- 可調: 透過
output_dimensionality參數可請求較低維度的輸出以節省儲存/CPU。擁有海量向量庫的用例常將維度降至 512–1,024 以節省成本,但需接受一定的準確度取捨。
支援的模態與每次請求限制
- 圖片: PNG、JPEG——每次請求最多 6 張(廠商回報的限制)。
- 影片: MP4、MOV——廠商回報單次請求可支援單支影片約 128 秒。
- 音訊: MP3、WAV——廠商回報每個音訊輸入約 80 秒。
- 文件: PDFs——每次請求最多 6 頁(廠商回報)。
- 文字內容的 Token 限制: 模型支援大型文字輸入;實際每次請求的 Token 上限存在(請查閱 API 文件與 Vertex AI 配額)。
可用性與存取
- Public preview: Gemini Embedding 2 以公開預覽形式釋出,可透過 Gemini API 與 Google Cloud 的 Vertex AI 立即進行實驗性使用
常見問題(FAQ)
Q1: What modalities does Gemini Embedding 2 support?
A: 文字、圖片(PNG/JPEG)、影片(MP4/MOV)、音訊(MP3/WAV)與 PDF 文件——全部映射至同一語意向量空間。
Q2: What is the default vector size for Gemini Embedding 2?
A: 預設為3,072 維。你可透過 API 請求更小的輸出維度。
Q3: Is Gemini Embedding 2 available now?
A: 是——已以公開預覽形式發佈,可透過 Gemini API 與 Vertex AI 使用(查看型號 gemini-embedding-2-preview 與最新變更紀錄)。
Q4: How does it compare to embeddings from other providers?
A: 獨立廠商測試顯示,Gemini Embedding 2 在多語文字方面位居頂尖專有模型之列,且在多項多模態任務上達到最先進表現。實際名次因任務與資料集而異;請於你的資料上評估。
Q5: Will I need to transcribe audio to use Gemini Embedding 2?
A: 不需要——Gemini Embedding 2 可直接接受音訊並產生嵌入,無需先轉為文字,支援端到端的音訊語意檢索。
Q6: How do I lower storage costs for 3,072-dim vectors?
A: 可選擇請求較小的 output_dimensionality、採用 float16/量化/PQ,並在向量資料庫中儲存壓縮表徵。廠商文章提供了工作流程與最佳實務。
接下來怎麼做——現在就採用嗎?
Gemini Embedding 2 在統一多模態檢索上邁出重要一步,並簡化過去需要為文字、視覺與語音維護多組檢索器的架構。採用決策的關鍵考量:
- 盡早採用:若你的產品需要穩健的跨模態檢索(文字↔圖片/影片/音訊),或維護多個單模態檢索器的成本與複雜度過高。
- 現在先試點:若你想評估 MRL 截斷並量測成本與品質,可先行試點(建議混合部署:以 1536 為主,3072 用於重排序)。
- 暫緩觀望:若你的工作負載對成本極度敏感且只需文字檢索——頂尖的純文字模型(例如 OpenAI text-embedding-3-large)仍具競爭力,且依管線與合約不同,有時更為便宜。
Developers can access Gemini Embedding 2 and OpenAI text-embedding-3 API via CometAPI now. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for cometapi today!
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!