
.webp&w=3840&q=75)
GLM-5.1 代表著 AI 版圖的一次關鍵轉變。隨著中國 AI 公司在開源前沿能力的同時加速商業化,該模型與 OpenAI 的 GPT-5.4、Anthropic 的 Claude Opus 4.6、Google 的 Gemini 3.1 Pro 等專有領先者之間的差距正在縮小——尤其在真實世界軟體工程方面。它採用與 GLM-5 相同的 744B 參數 MoE 架構訓練,但針對代理式工作流進行了大量優化,並在大多數 LLM 容易失誤的領域表現出色:需要規劃、實驗、除錯與自我修正、跨越數千次工具呼叫的冗長、含糊且迭代的任務。
現在,CometAPI 集成了 GLM-5.1 和 GLM-5,開發者也可以看到其他西方頂級模型並以極低的 API 價格獲取(這也是 CometAPI 相對於其他競品的優勢)。
什麼是 GLM-5.1?
GLM-5.1 是 Z.ai 最新的旗艦語言模型,也是該公司在長期、代理式軟體工作方面的最新推進。用 Z.ai 自己的話說,它面向需要持續執行而非一次性回覆的任務,被定位為能在單次長時間運行中完成規劃、執行、完善與交付的模型。Z.ai 的發佈說明稱,GLM-5.1 基於多輪監督微調、增強學習與流程品質評估框架構建,並在長時任務中的穩定性、一致性與工具使用方面有所提升。
這樣的定位很重要,因為 GLM-5.1 並非僅僅作為「另一個聊天模型」來銷售。它瞄準的是工程化工作流——模型需要牢記目標、處理中間步驟、在不丟失主線的情況下從錯誤中恢復;它被設計為可自主規劃、持續執行、修復缺陷並迭代策略的模型,這與休閒助理或短上下文的程式輔助工具是截然不同的產品故事。
一個實用的細節:GLM-5.1 僅支援文本,已納入 GLM Coding Plan,並可在 Claude Code、OpenClaw 等流行編碼代理中使用,這使其對想把模型嵌入既有開發者工作流(而非取而代之)的團隊尤為合適。
核心技術規格(承襲並優化自 GLM-5):
- 架構:專家混合(MoE),總參數 7440 億,單次推理約啟用 400 億參數。
- 上下文視窗:203K–204.8K 權杖(支援最多 131K 輸出權杖)。
- 關鍵增強:DeepSeek Sparse Attention(DSA),以高效處理長上下文並降低部署成本;先進的非同步增強學習基礎設施(透過 Z.ai 的 “slime” 框架)以提升後訓練效果。
- 可用性:開放權重(MIT 授權,Hugging Face 上的 zai-org/GLM-5.1)、可透過 Z.ai 平台與 CometAPI 等聚合器獲取 API,以及整合進 GLM Coding Plan 工具(相容 Claude Code / OpenClaw)。
不同於早期著重通用智能或短期「vibe coding」的 GLM 模型,GLM-5.1 瞄準的是生產級自主代理。它能在無人干預下獨立規劃、執行、基準測試、除錯並迭代複雜工程專案數小時——這些能力使其成為 Anthropic 與 OpenAI 專門編碼代理的直接競爭者。
該發佈與約 10% 的 API 價格上調同時出現(輸入權杖約 $0.54/M,輸出約 $4.40/M),但相比同類(如 Anthropic 的 Opus 4.6,昂貴 250–470%)仍然便宜許多。
GLM-5.1 基準測試表現
Z.ai 將 GLM-5.1 定位為全球最強的開源模型,以及代理式編碼領域全球前三的選手。表現數據來自官方在 SWE-Bench Pro、NL2Repo、Terminal-Bench 2.0 與自定義長期情境中的評測。
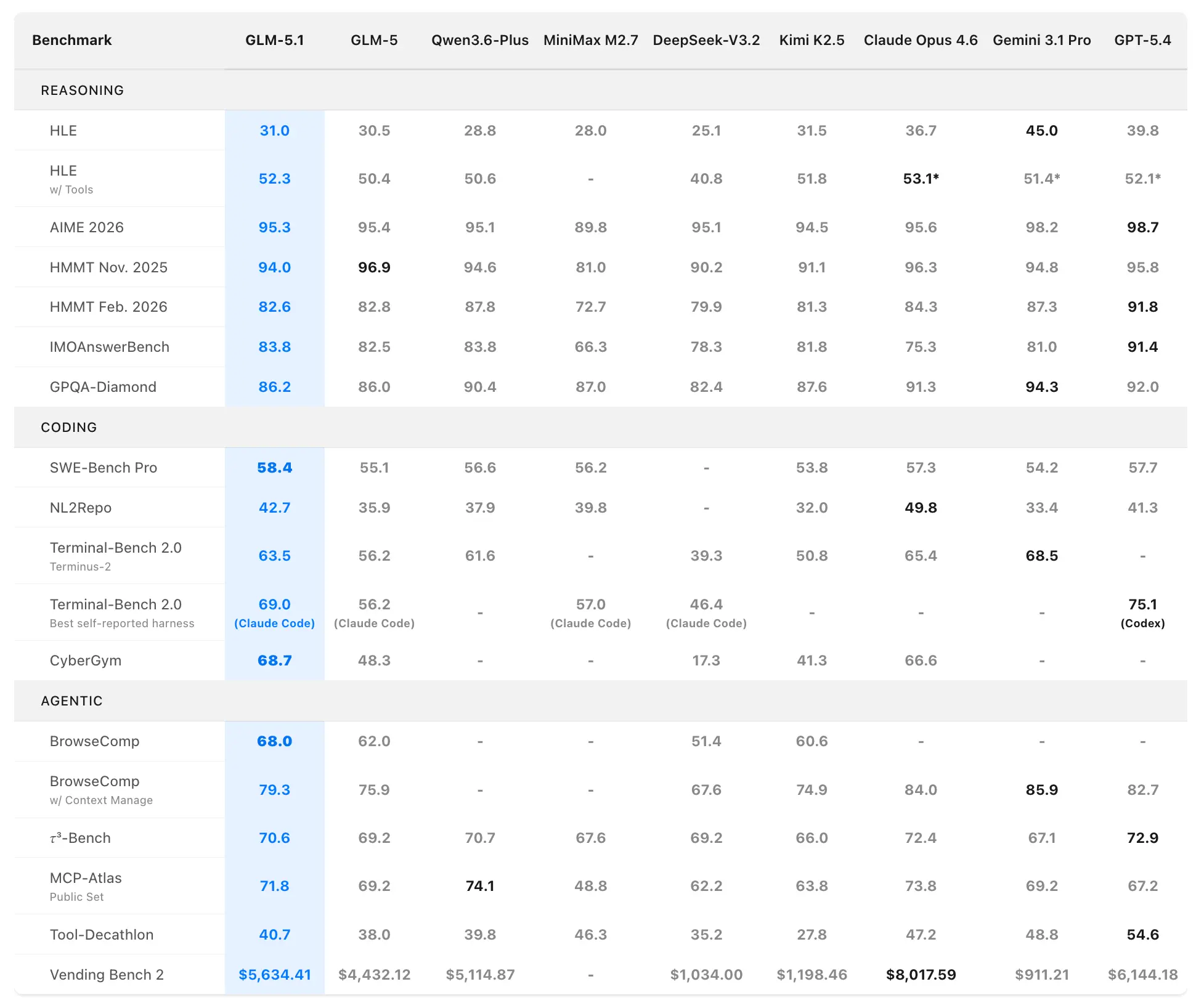
編碼與代理式基準
SWE-Bench Pro(需要倉庫導航、代碼編輯與功能驗證的真實軟體工程任務):
- GLM-5.1:58.4(新的 SOTA)
- GLM-5:55.1
- GPT-5.4:57.7
- Claude Opus 4.6:57.3
- Gemini 3.1 Pro:54.2
GLM-5.1 是首個國產(中國)且開源的模型在這項嚴苛的基準上奪得榜首,該基準與專業開發者的工作流高度貼合。
NL2Repo(從自然語言到完整倉庫生成):
- GLM-5.1:42.7(大幅領先 GLM-5 的 35.9)
- 競品範圍 32.0–49.8(具體領先者因測試套件而異)。
Terminal-Bench 2.0(真實終端與系統任務):
- Terminus-2 測試套件:GLM-5.1 63.5(對比 GLM-5 的 56.2)
- 最佳自報(Claude Code):最高 69.0。
在另一個編碼測試套件評估(Claude Code 風格)中,GLM-5.1 獲得 45.3——達到 Claude Opus 4.6 的 47.9 之 94.6%,且較 GLM-5 的 35.4 提升 28%。
綜合排名:開源第 1,中國模型第 1,綜合全球第 3(涵蓋 SWE-Bench Pro + NL2Repo + Terminal-Bench)。
長期任務表現:真正的差異化所在
標準基準多衡量一次性或短會話表現。GLM-5.1 在長時間自主運行中大放異彩:
- VectorDBBench 最佳化(600+ 次迭代,6000+ 次工具呼叫):從一個 Rust 骨架出發,GLM-5.1 迭代性地重設索引、壓縮、路由與剪枝,實現 21.5k QPS(較此前 50 輪最佳——Claude Opus 4.6 的 3547 QPS——提升 6×),同時在 SIFT-1M 上保持 ≥95% 召回率。其進展呈現「階梯式」躍升,每 100–200 次迭代出現結構性突破。
- KernelBench Level 3(完整 ML 模型最佳化,1000+ 輪):在 50 個複雜問題上達到 3.6× 的幾何平均加速比(超過 torch.compile max-autotune 的 1.49×)。GLM-5.1 在 GLM-5 停滯後仍持續提升;僅有 Claude Opus 4.6 以 4.2× 略勝。
- Linux 桌面 Web 應用構建(8+ 小時,開放式):僅給定自然語言提示、無任何起始代碼,GLM-5.1 自主構建了可運作的 Linux 風格桌面環境——包含工作列、視窗、互動與細節打磨——而此前模型只產出基礎骨架。
這些結果顯示 GLM-5.1 能在極長時間跨度內保持連貫、自我評估、修訂策略並跳出局部最優——這些能力是 Z.ai 為真實世界的代理式系統明確打造的。
GLM-5.1 與 GLM-5 有何不同?
GLM-5 與 GLM-5.1 關係緊密,但定位不同。GLM-5 是 Z.AI 早期面向 Agentic Engineering 的基礎模型。它為複雜系統工程與長距代理任務設計,具備開放權重的 SOTA 編碼與代理能力,在真實編程場景中的表現接近 Claude Opus 4.5。在 SWE-bench Verified 上得分 77.8,在 Terminal Bench 2.0 上為 56.2。
相較之下,GLM-5.1 被定位為邁向長期任務與更可靠持續執行的下一步,強化了在長時任務中的穩定性、一致性與工具使用表現,並在整體對齊上更接近 Claude Opus 4.6。換言之,GLM-5 是之前更偏工程核心的基礎模型,而 GLM-5.1 是更注重任務耐力的旗艦。
GLM-5 代還在架構與訓練上做出了變化,為躍升提供了解釋。GLM-5 從 355B 參數(啟用 32B) 擴展到 744B 參數(啟用 40B),預訓練數據從 23T 增至 28.5T,引入了非同步增強學習框架,並整合了 DeepSeek 稀疏注意力,在提升效率的同時保持長文本品質。這些屬於 GLM-5 的細節,構成了 GLM-5.1 的進一步基礎。
GLM-5.1 與其他前沿模型
GLM-5.1 以最強開源競逐者的姿態脫穎而出,並提供具吸引力的性價比。
比較表:主要編碼與代理式基準(2026 年 4 月)
| 模型 | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | 編碼測試套件分數 | 長期持續能力? | 開源? | 約 API 價格(每百萬權杖輸入/輸出) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4(SOTA) | 42.7 | 63.5 | 45.3(為 Opus 的 94.6%) | 是(600+ 次迭代,8 小時) | 是 | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | 受限 | 是 | 較低(提價前) |
| GPT-5.4 | 57.7 | — | — | — | 強 | 否 | 較高 |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | 最強 | 否 | 約貴 250–470% |
| Gemini 3.1 Pro | 54.2 | — | — | — | 良好 | 否 | 較高 |
結論:GLM-5.1 在開源可獲性、成本與特定長期編碼指標上佔優。在代理式情境中與閉源領先者分庭抗禮,同時讓前沿能力更為普及。
GLM-5.1 的應用場景
1) 自主軟體工程
當任務類似真實工程衝刺時,GLM-5.1 最具吸引力:閱讀代碼庫、規劃變更、實作、測試、修復回歸,並持續迭代直到結果穩定。Z.ai 的發佈說明明確強調自主規劃、持續執行、缺陷修復與策略迭代,使其看起來為編碼代理與軟體交付流水線量身打造。
2) 長時間運行的代理工作流
若你的用例涉及大量工具呼叫、長多步驟工作流或反覆的自我修正,GLM-5.1 的設計高度匹配。文檔強調了工具調用、結構化輸出、MCP 整合與工具串流支援,這些在模型不僅回答、而是運作於更大系統中的情境尤為有用。
3) 企業知識工作與報告
GLM-5.1 也定位於辦公效率場景,如 PowerPoint、Word、PDF 與 Excel 工作流。Z.ai 稱其在複雜內容組織、版面設計、結構化輸出與視覺打磨方面有所提升,適合報告生成、教材製作、研究摘要與其他文檔密集型工作。
4) 前端原型與產出物
Z.ai 表示 GLM-5.1 適合網站生成、互動頁面與前端原型製作,結構更少模板化、任務完成品質更高。對需要從簡述快速橋接到可用原型的產品團隊而言,它是很好的契合。
5) 複雜對話與指令遵從
雖然焦點是編碼,GLM-5.1 在開放式問答、複雜指令與多輪互動方面也更強。對需要助理式工作流、必須跟蹤約束、反覆修訂輸出,並在更長對話中保留上下文的場景非常實用。
結語:為何 GLM-5.1 在 2026 年意義重大
GLM-5.1 並非又一次小幅迭代——它預示著真正有能力的開源代理式 AI 的到來。它在最艱難的真實工程基準上表現卓越,同時保持可負擔與開放,Z.ai 為整個行業抬高了標準。無論你是個人開發者、企業團隊還是研究者,GLM-5.1 都能以專有方案一小部分的成本,為長期編碼任務提供無與倫比的自主性。
準備好試試了嗎? 前往 CometAPI 的 GLM-5.1 模型、Hugging Face 倉庫或 GLM Coding Plan 立即開用。