

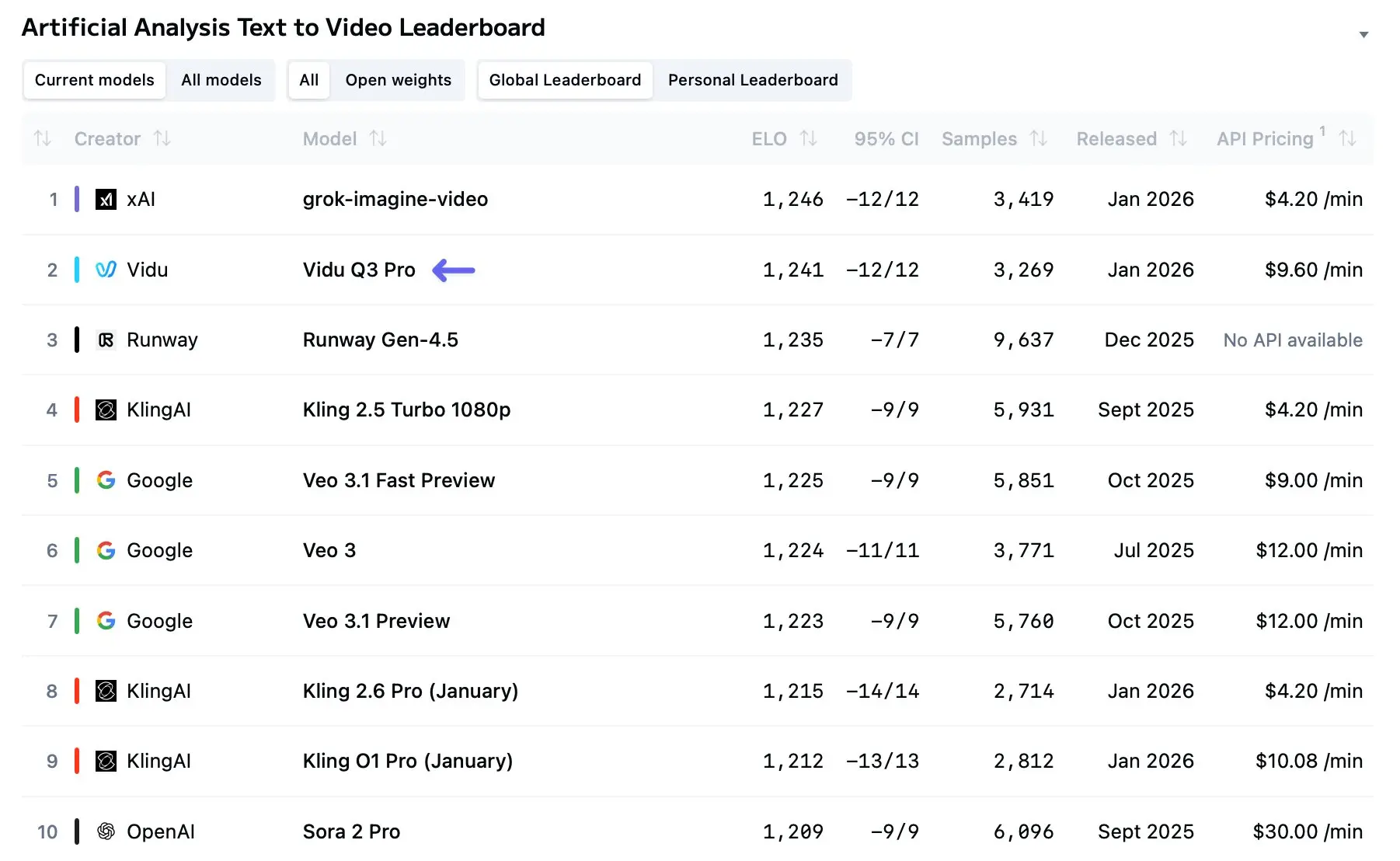
Vidu Q3 於 2026 年初進入視野,成為迄今最明確的信號之一:由 AI 驅動的影片生成,正從短小、新奇的片段邁向真正具敘事性的多鏡頭故事。在廣泛發布後的數月裡,Vidu Q3 已成為創作者工作流程、研究試點與商業試點的常用工具——理由充分:它在時長、聲畫整合與多鏡頭一致性方面均超越多數早期模型,並提供面向開發者的 API 以便程式化使用。
什麼是 Vidu Q3?
Vidu Q3 是 ShengShu Technology 大型影片模型(LVM)架構的最新旗艦迭代。與其前代(Vidu 1.0 與 1.5)需要將影像生成與音訊後期分開的工作流程不同,Vidu Q3 是一個「一體化」生成引擎。
Vidu Q3 的核心突破在於能夠同時生成高畫質影像與高保真音訊。[ 藉由同時理解聲音與光線的物理,該模型消除了競品常見的音畫不同步所帶來的「恐怖谷」。它支援最高 16 秒的連續生成,原生 1080p 解析度,定位於可投入製作的短片、廣告與敘事創作工具。
Vidu Q3 在底層如何運作?
儘管核心架構細節為專有,Vidu 建立在 U‑ViT 將擴散模型與 Transformer 融合 的設計之上——這種設計以在影片生成中平衡整體連貫性、時間連續性與表現力而著稱。
這種混合式架構使模型能在較長序列中推理運動、聲音與敘事脈絡。
Vidu Q3 的 6 大亮點
1. 延長時長的生成——能做到多長?
Vidu Q3 的主打功能之一是更長的單次生成時長。許多早期模型聚焦於微型片段;Q3 有意延長片段長度,以允許簡單的故事弧線與多鏡頭序列,無需強迫創作者拼接許多短片。平台文件與合作夥伴入口宣稱,一次生成可達 ~16 秒的原生時長(不同提供者與 API 方案的格式與品質選項可能有所差異)。這很重要,因為由 4–8 秒提升至 16 秒,會改變創作者規劃場景、撰寫節奏點與安排聲音提示的方式。
2. 視覺保真與時間一致性
獨立評估與早期基準顯示,Vidu Q3 的影像更清晰,且比早期消費級模型更少出現逐幀失真。架構與資料增強的改進似乎降低了閃爍,並改善了 10–16 秒以內片段的運動連續性。然而,模型在密集、多主體的場景(人群、複雜的物理互動)中仍可能遇到挑戰,因為遮擋與細緻運動需要更強的物理推理。比較排名網站與模型排行榜已將 Vidu Q3 列為 T2V(文字轉影片)中的高位,儘管排名會因基準與資料集而異。
3. 原生音訊 + 影像生成
不同於僅產生無聲影像、將音訊留給後期的系統,Vidu Q3 在模型內整合了音訊生成。結果是對嘴同步的對白、精準對時的音效,以及與畫面同時產生的可選背景音樂。在模型層面整合聲音可降低對齊錯誤(對嘴漂移、節拍失準),並縮短用於展示、預覽與許多定稿短片的製作迴路。
4. 智慧鏡頭控制與多鏡頭敘事
Q3 的「智慧鏡頭」功能能解讀提示中的鏡頭運動(平移、移動、追蹤)與多鏡頭序列。模型不再只產生單一靜態視角,而是能生成計畫好的切換與轉場,使最終片段像一個被導演過的場景。對創作者而言,這將輸出從「一張移動的構圖」轉變為「一個包含多鏡頭的短場景」。這提高了可看性,並在一次生成中實現更豐富的視覺敘事。
5. 多參考一致性與角色還原度
Vidu(作為平台)投入於「reference to video」與多參考一致性系統,允許創作者上傳多張參考圖像以鎖定角色在各幀的身份。Q3 擴展了這些理念,讓角色外觀與道具在多個鏡頭與切換間保持一致——這是 coherent 敘事輸出的基本且必要條件。這對於需要維持角色畫風一致性的動畫或風格化專案尤其實用。
6. 面向開發者的就緒度:API 與流程
Vidu 的模型套件——包含 Q3——可透過網頁介面與程式化的 REST API 使用。開發者可提交文字轉影片或圖像加文字的任務到推論端點,接收任務 ID,並輪詢結果(典型的非同步任務模式)。API 提供解析度、長寬比、時長、運動幅度與音訊生成切換等參數。這使 Q3 可用於自動化、批次流程與編輯管線整合。
Vidu Q3 與 Sora 2、Veo 3.1 的比較如何?
簡短回答:Vidu Q3 在 10–20 秒場景的長篇敘事輸出與音畫整合上競爭力強;Sora 2 擅長具物理可合理性的單鏡頭寫實與社群整合;Veo 3.1 則在像素級細緻度、多幀連續工具與企業級 API 整合上領先。以下從實用維度拆解差異。
哪個在寫實與物理上更強:Sora 2 還是 Vidu Q3?
Sora 2(OpenAI) 專為物理可合理性與世界模擬而訓練——其公開說明強調先進的物理行為、精準的物體互動與高度寫實的運動軌跡。Sora 2 也提供同步音訊與社群應用整合(包含客串功能與行動 App),使其在逼真、物理一致的場景中表現出色。若你的需求是短而完整的片段中,要求精準碰撞、真實動力學或寫實的人物運動,Sora 2 往往更勝一籌。
Vidu Q3 則定位為一款敘事引擎:更長的片段、多鏡頭序列與導演風格的鏡頭控制。這並不代表 Vidu 犧牲寫實度,但其主要優勢在於敘事連貫性與聲畫合一,而非純粹的物理模擬。對於電影式的短篇敘事(如含切換與 VO 的 16 秒產品 Demo),Q3 的工作流程通常更快速、簡單。
哪個在電影質感與高保真上更佳:Veo 3.1 vs Vidu Q3?
Veo 3.1(Google / DeepMind / Gemini) 被定位為高保真、企業級選項,具備強大的連續性控制、原生音訊生成,並支援在 Google 的雲端/Vertex/Gemini 堆疊中使用。Veo 3.1 引入了進階的 “ingredients to video” 功能、直式(9:16)原生支援,以及升頻至高解析度(在部分流程中包含 4K 能力)。對需要最高像素品質、精準色彩協調與嚴密企業 API 的專案而言,Veo 3.1 常是首選。
Vidu Q3 則以延長時長 + 多鏡頭故事連貫為核心,並具創作者導向的產品化(快速的網頁試驗場、對多參考的編排)。若你的優先事項是產出一段具人為導引、多個鏡頭運動與整合音訊提示的短場景(並且將長度置於像素打磨之上),Vidu Q3 相當吸引人。就純粹的照片級寫實而言,Veo 3.1 通常更具優勢。
截至 2026 年初,AI 影片三巨頭由 OpenAI 的 Sora 2、Google 的 Veo 3.1 與 Vidu Q3 構成。以下是直接對比:
| 功能 | Vidu Q3 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| 單段影片最長時長 | ~16 秒 | 最高約 ~25 秒(Pro) | 8 秒(具敘事拼接功能) |
| 原生音訊生成 | 是(整合) | 是(實驗性) | 是(進階) |
| 電影級鏡頭控制 | 是(具鏡頭/鏡次意識) | 預設有限 | 是(多鏡頭一致性) |
| 多鏡頭敘事 | 是 | 是 | 是 |
| 畫面中文本渲染 | 是 | 視情況而定 | 視情況而定 |
| 解析度 | 1080p | 1080p | 1080p / 特定情況下為 4K |
| 主要使用案例 | 故事敘事、動畫 | 高預算概念/電影 | YouTube Shorts / TikTok |
Analysis:
- 相較 Sora 2: Sora 2 仍是純視覺保真與超現實想像(「好萊塢級」)的重量級選手。然而,Vidu Q3 憑藉 16 秒上限與更優的音訊整合,在工作流程效率上勝出。對需要「一次完成」片段的創作者而言,Q3 更快。
- 相較 Veo 3.1: Google 的 Veo 3.1 在較短、社群導向的片段(4–8 秒)上速度快,且與 YouTube 深度整合。Vidu Q3 的目標則更靠近價值鏈上游,面向需要更長、連續鏡頭的專業動畫師與電影人,而這是 Veo 一貫性較難長時間維持的區域。
Vidu Q3 帶來哪些實用場景?
廣告與短影音行銷
品牌可更快速地端到端驗證廣告概念:撰寫腳本,生成含同步旁白與音效的 16 秒畫面,迭代用語與鏡頭構圖,並藉由多語言提示產出多語配音。對於社群素材的 A/B 測試,縮短的週轉時間是明顯的商業優勢。平台釋出的案例顯示,行銷人員已用 Vidu Q3 製作微型廣告與產品預告。
影視分鏡與前期視覺化(Previz)
導演與剪輯正使用短 AI 片段作為前期視覺化(previz),用以排位、測試鏡頭運動與提案。Vidu Q3 的多鏡頭序列與智慧鏡頭控制在此特別有用:創意團隊可在不動用外景拍攝成本的情況下,迭代調整走位與對白。雖然 AI previz 不會取代片場導演,但它縮短了前期決策週期。
線上學習與解說影片
教育與企業培訓部門可生成精簡的動畫解說片段,配有同步旁白與標註音效。對標準化內容(產品訓練、入職),這可降低對昂貴製作公司的依賴,並加速在地化版本。更快的發布速度與原生音訊能力,讓 Vidu Q3 對這些用例極具吸引力。
遊戲、概念藝術與獨立製作
獨立開發者與遊戲團隊使用短 AI 電影感片段來製作預告、NPC 對話樣稿或風格探索。Vidu Q3 對參考圖與角色一致性的支援,有助於在原型預告中維持遊戲 IP 的視覺識別。該模型也常用於募資或爭取發行商青睞的提案素材。
可及性與快速在地化
由於音訊原生生成,Vidu Q3 簡化了多語版本:以不同語言提示生成相同鏡頭,或請求不同聲線。這可快速在地化行銷內容或訓練素材,同時維持對口形近似,足以滿足多數短影音情境(但廣播級嚴格對口仍可能需要人工調整)。
Vidu Q3 是 2026 年最好的 AI 影片模型嗎?
宣稱單一「最佳」模型忽略了細節:勝負取決於用例。
- 若追求照片級寫實、物理落地與保守的安全處理, OpenAI 的 Sora 2 經常被視為首選。它強調寫實與穩健審核,使其對高端製作與風險敏感的企業格外具吸引力。
- 若重視平台整合與格式最佳化的短影音, Veo 3.1 的原生直式輸出與 Google 生態(YouTube Shorts、Google Photos)整合使其便利獨到。
- 若追求快速聲畫原型、多鏡頭敘事控制與敘事功能的良好平衡, Vidu Q3 表現亮眼——尤其在迭代速度與聲畫整合比絕對寫實更重要時。早期基準與供應商報告將 Vidu Q3 列為 T2V 高位,其功能也使其成為行銷人員、獨立創作者與進行原型製作的工作室的實用選擇。
限制與注意事項?
雖然 Vidu Q3 是一次突破,但仍有取捨:
- 片段時長 仍受限(約 16 秒),更長敘事需要拼接或多次提示。
- 資源成本 會隨 HD 生成與複雜音訊而增加。
- AI 工具仍需 編輯判斷 將輸出潤飾為成品。
因此:Vidu Q3 是 2026 年的頂尖競爭者,尤其適合優先考慮原生音訊工作流程與多鏡頭敘事的創作者。是否為「最佳」,取決於你的製作需求、合規限制與發佈管線。
結論
Vidu Q3 於 2026 年脫穎而出,作為能產出 敘事就緒、聲畫整合的短片 的領先 AI 影片模型,在創意與製作需求間架起橋樑。相較於 Sora 2 的強敘事連貫 與 Veo 3.1 的電影級寫實,Vidu Q3 提供平衡而完整的工具組,適合說書人、內容創作者與商業工作流程。
隨著基準顯示其高效能與整合特性,Vidu Q3 標誌著生成式影片 AI 的轉折點——讓複雜的聲畫製作更易用、更高效。
開發者可透過 Vidu Q3、Veo 3.1 與 Sora 2 使用 CometAPI,本文發佈時最新模型以文中日期為準。開始之前,請在 Playground 探索模型能力,並參閱 API guide 取得詳細說明。存取前,請先登入 CometAPI 並取得 API key。CometAPI 提供遠低於官方的價格,協助你完成整合。
Ready to Go?→ 立即註冊開啟影片生成!