

在一個由「不惜一切擴大規模」理念主導的版圖中——像 Flux.2 與 Hunyuan-Image-3.0 等模型將參數量推至 30B 到 80B 的龐大級別——一個新的競逐者橫空出世,試圖改寫現狀。Z-Image,由 Alibaba’s Tongyi Lab 開發,正式發佈,以精實的 60 億參數架構打破預期,在消費級硬體上運行的同時,輸出品質可與業界巨頭比肩。
Z-Image 於 2025 年末釋出,其超高速變體 Z-Image-Turbo 同步登場,瞬間吸引了 AI 社群的目光,在首發 24 小時內即超過 500,000 次下載。Z-Image 只需 8 個推理步驟即可生成照片級真實感影像,不僅僅是另一個模型,更是生成式 AI 的普及化力量,讓原本會讓筆電吃不消的高保真創作在消費級裝置上變得切實可行。
什麼是 Z-Image?
Z-Image 是由 Tongyi-MAI / Alibaba Tongyi Lab 研究團隊開發的全新開源圖像生成基礎模型。它是一個擁有 60 億參數的生成模型,基於新型 Scalable Single-Stream Diffusion Transformer (S3-DiT) 架構,將文字 token、視覺語義 token 以及 VAE token 串接為單一處理流。設計目標明確:在大幅降低推理成本並支援消費級硬體的前提下,提供頂級寫實度與指令遵從。Z-Image 專案以 Apache-2.0 授權釋出程式碼、模型權重與線上示範。
Z-Image 提供多種變體。討論度最高的是 Z-Image-Turbo——一個經蒸餾、少步驟、面向部署的版本——此外還有未蒸餾的 Z-Image-Base(基礎檢查點,更適合微調)以及 Z-Image-Edit(針對圖像編輯進行指令微調)。
「Turbo」優勢:8 步推理
旗艦變體 Z-Image-Turbo 採用名為 Decoupled-DMD(分佈匹配蒸餾) 的漸進式蒸餾技術。這使模型能將標準的 30–50 步生成過程壓縮至僅 8 步。
效果: 在企業級 GPU(H800)上可達亞秒級生成,在消費級顯卡(RTX 4090)上幾乎實時,且不會出現其他 turbo/lightning 模型常見的「塑膠感」或「褪色」外觀。
Z-Image 的 4 個關鍵特性
Z-Image 具備面向技術開發者與創意專業人士的豐富功能。
1. 無與倫比的寫實與美學
儘管只有 60 億參數,Z-Image 依然能生成令人驚訝的清晰影像,並在以下方面表現出色:
- 肌膚質感: 重現毛孔、瑕疵與自然光影。
- 材質物理: 精準渲染玻璃、金屬與布料的質地。
- 光照: 在電影級與體積光照上的處理優於 SDXL。
2. 原生雙語文字渲染
文字渲染一直是 AI 圖像生成的重大痛點。Z-Image 原生支援英文與中文。
- 能生成拼寫與字形均正確的複雜海報、標誌與招牌,這在許多以西方為中心的模型中常常缺失。
3. Z-Image-Edit:基於指令的編輯
與基礎模型同步釋出的是 Z-Image-Edit。此變體針對圖到圖任務進行微調,允許用戶以自然語言指令修改現有圖像(例如「讓這個人微笑」、「把背景換成雪山」)。在轉換過程中能高度保持身份特徵與光照一致性。
4. 消費級硬體可用性
- VRAM 效率: 在 6GB VRAM(量化)至 16GB VRAM(全精度)間運行自如。
- 本地執行: 完整支援透過 ComfyUI 與
diffusers進行本地部署,免於雲端依賴。
Z-Image 如何運作?
單流擴散 Transformer(S3-DiT)
Z-Image 不同於經典的雙流設計(分離的文字與圖像編碼器/管線),而是將文字 token、圖像 VAE token 與視覺語義 token 拼接為單一 transformer 輸入。這種單流方法提升了參數利用率並簡化了主幹網路中的跨模態對齊;作者表示,對於 6B 模型而言,這帶來更有利的效率/品質折衷。
Decoupled-DMD 與 DMDR(蒸餾 + RL)
為了在少步(8 步)生成的同時避免品質下降,團隊提出 Decoupled-DMD 蒸餾方法。此技術將 CFG(classifier-free guidance,無分類器引導)增強與分佈匹配分離,使兩者可獨立優化;之後再施以訓練後的強化學習步驟(DMDR)以細化語義對齊與美學。兩者結合,讓 Z-Image-Turbo 在遠少於典型擴散模型的 NFEs 下仍能維持高度寫實。
訓練吞吐與成本優化
Z-Image 採用全生命週期的優化策略:精選的數據管線、精簡的課程化訓練,以及以效率為導向的實作選擇。作者報告完整訓練流程約耗費 314K H800 GPU 小時(≈ USD $630K)——這是一個明確且可複製的工程度量,相較於超大型(>20B)替代方案更具成本效益。
Z-Image 模型的基準測試結果
Z-Image-Turbo 在多個當代排行榜上名列前茅,包括在 Artificial Analysis 文本到圖像排行榜的開源名次,以及在 Alibaba AI Arena 的人偏好評測中表現強勁。
但真實世界的品質亦取決於提示撰寫、解析度、升階管線以及後處理等因素。
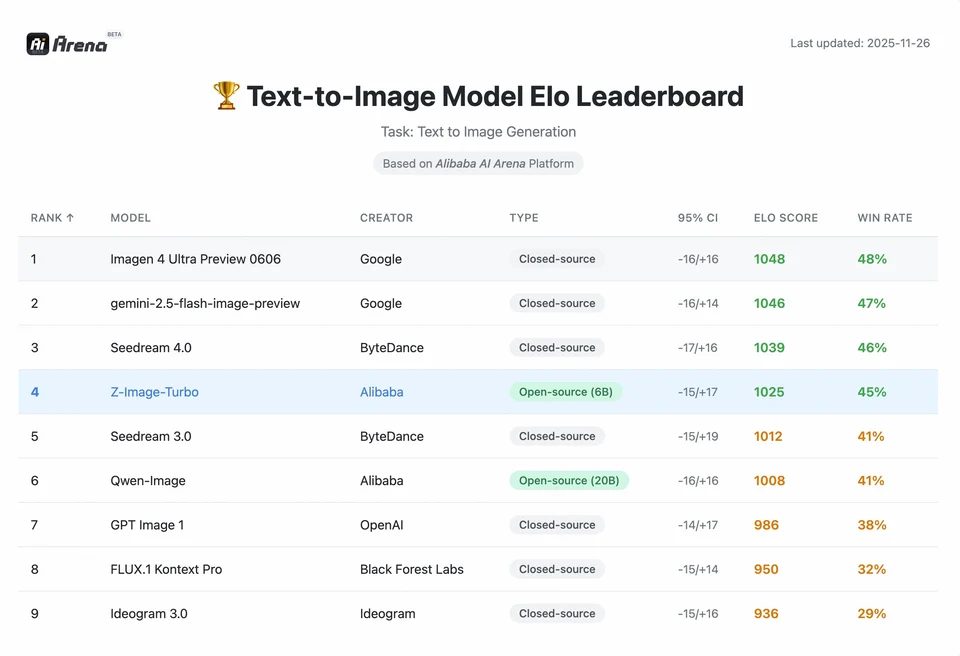
為了理解 Z-Image 的成就幅度,我們需要數據支持。以下是 Z-Image 與領先的開源與商業模型間的比較分析。
比較基準摘要
| 功能 / 指標 | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| 架構 | S3-DiT(單流) | MM-DiT(雙流) | U-Net | 擴散 Transformer |
| 參數量 | 60 Billion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| 推理步數 | 8 Steps | 25 - 50 Steps | 1 - 4 Steps | 30 - 50 Steps |
| 所需 VRAM | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| 文字渲染 | 高(EN + CN) | 高(EN) | 中(EN) | 高(CN + EN) |
| 生成速度(4090) | ~1.5 - 3.0 Seconds | ~15 - 30 Seconds | ~0.5 Seconds | ~20 Seconds |
| 寫實度評分 | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| 授權 | Apache 2.0 | 非商用(Dev) | OpenRAIL | Custom |
數據分析與效能洞見
- 速度 vs. 品質: 雖然 SDXL Turbo 更快(1 步),但在複雜提示下品質大幅下降。Z-Image-Turbo 在 8 步達成「甜蜜點」,可匹敵 Flux.2 的品質,同時快 5 倍到 10 倍。
- 硬體普及化: Flux.2 雖然強大,但實用表現幾乎被 24GB VRAM 顯卡(RTX 3090/4090)門檻所限制。Z-Image 讓中階顯卡(RTX 3060/4060)用戶也能在本地生成專業級 1024x1024 圖像。
開發者如何存取與使用 Z-Image?
常見有三種方式:
- 託管 / SaaS(web UI 或 API): 使用 z-image.ai 等服務或其他提供者,部署模型並提供網頁介面或付費 API 進行圖像生成。這是無需本地設定即可最快試用的途徑。
- Hugging Face + diffusers 管線: Hugging Face 的
diffusers函式庫包含ZImagePipeline與ZImageImg2ImgPipeline,並提供典型的from_pretrained(...).to("cuda")工作流程。這是希望簡單整合與可複製範例的 Python 開發者的推薦路徑。 - 從 GitHub 倉庫進行本地原生推理: Tongyi-MAI 倉庫包含原生推理腳本、優化選項(FlashAttention、編譯、CPU offload),以及從原始碼安裝
diffusers的最新整合說明。此路徑適合希望完全掌控或進行自訂訓練/微調的研究人員與團隊。
最小化 Python 範例是什麼樣?
以下是使用 Hugging Face diffusers 的簡潔 Python 範例,示範以 Z-Image-Turbo 進行文字轉圖像生成。
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
備註:Turbo 模型的 guidance_scale 預設與推薦設定有所不同;文件建議依目標行為將 guidance 設為較低甚至 0。
如何使用 Z-Image 進行圖到圖(編輯)?
ZImageImg2ImgPipeline 支援圖像編輯。範例:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
這與官方使用模式一致,適合創意編輯與修補(inpainting)任務。
該如何撰寫提示與調整引導?
- 明確描述結構: 對於複雜場景,將提示結構化,包含場景構圖、焦點物件、相機/鏡頭、光照、氛圍與任何文字元素。Z-Image 對詳細提示受益良多,且能良好處理位置/敘事線索。
- 謹慎微調 guidance_scale: Turbo 模型可能建議較低的引導值;需要實驗。對許多 Turbo 工作流而言,
guidance_scale=0.0–1.0搭配固定種子與步數可產生一致結果。 - 使用圖到圖進行可控編輯: 當需要保留構圖但改變風格/配色/物件時,從初始圖像開始並使用
strength控制變更幅度。
最佳使用場景與實務
1. 快速原型與分鏡
使用場景: 導演與遊戲設計師需要即時視覺化場景。
為何選擇 Z-Image? 透過 3 秒內生成,創作者可在單次工作階段中迭代數百個概念,並即時微調光照與構圖,而不必等待數分鐘渲染。
2. 電商與廣告
使用場景: 生成商品背景或生活化情境照。
最佳實務: 使用 Z-Image-Edit。
上傳原始商品照片,搭配指令提示如「把這瓶香水放在陽光花園的木桌上」。模型會在保留商品完整性的同時,生成照片級真實的背景。
3. 雙語內容創作
使用場景: 需要同時面向西方與亞洲市場的全球行銷素材。
最佳實務: 善用文字渲染能力。
- 提示:「在黑暗巷弄中發光的霓虹招牌,上面寫著『OPEN』與『營業中』。」
- Z-Image 能正確渲染英文字與中文字,大多數其他模型難以達成。
4. 低資源環境
使用場景: 在邊緣裝置或一般辦公筆電上運行 AI 生成。
優化提示: 使用 INT8 量化版本。這能將 VRAM 使用降至 6GB 以下且品質損失可忽略,使非遊戲筆電上的本地應用變得可行。
重點結論:誰該使用 Z-Image?
Z-Image 為重視高品質寫實、實際延遲與成本並偏好開放授權以及自建或客製部署的組織與開發者而設計。它對需要快速迭代(創意工具、產品樣機、即時服務)的團隊,以及有興趣微調精巧而強大的圖像模型的研究者/社群成員尤其具有吸引力。
CometAPI 亦提供限制較少的 Grok Image 模型,以及 Nano Banana Pro、GPT- image 1.5、Sora 2(Sora 2 能生成 NSFW 內容嗎?我們該如何嘗試?)等——只要掌握合適的 NSFW 技巧與訣竅以繞過限制,即可更自由地創作。在存取之前,請確保已登入 CometAPI 並取得 API key。CometAPI 提供遠低於官方價格的方案,協助你完成整合。
Ready to Go?→ Free trial for Creating !