

Alibaba’s Wan2.7-Image, released on April 1, 2026, marks a major leap in AI visual generation. This unified model integrates text-to-image creation, interactive editing, multi-image composition, and semantic understanding into a single architecture. Unlike traditional separate pipelines for generation and editing, it eliminates inconsistencies such as “standardized AI faces,” garbled text, and unpredictable colors.
Creators, designers, marketers, and enterprises now achieve photorealistic, instruction-perfect results with fewer iterations. The model supports up to 12 sequential images, 9 reference fusions, 12-language text rendering (up to 3,000 tokens), and pixel-level control.
What Is Wan2.7-Image?
Wan2.7-Image is Alibaba’s Tongyi Lab flagship unified image model within the Wan (Tongyi Wanxiang) series. It handles end-to-end visual workflows: text-to-image generation, image-to-image transformation, command-based editing, and interactive pixel-level refinements—all in one shared latent space.
Released April 1, 2026, it builds on prior Wan 2.x video models (which topped VBench benchmarks) by shifting focus to image precision. It directly tackles “aesthetic fatigue” from repetitive faces, unstable colors, and poor prompt alignment common in earlier AI tools. the model family includes two names that matter most for users: wan2.7-image and wan2.7-image-pro. The standard version is tuned for faster generation speed, while the Pro version is aimed at professional output, with 4K high-definition support.
Key differentiator: unified architecture. Traditional models use disconnected stages (encoder → diffusion → decoder), requiring separate inpainting for edits. Wan2.7-Image maps semantics directly in a shared space, enabling true understanding rather than pixel pattern matching.
Why Wan2.7-Image Matters (Industry Context)
Traditional AI image tools suffer from:
| Problem | Explanation |
|---|---|
| Fragmented workflow | Separate tools for generation, editing, inpainting |
| “AI face syndrome” | Repetitive, unrealistic human faces |
| Weak instruction alignment | Prompts not followed accurately |
| Poor text rendering | Distorted or unreadable text |
| Inconsistent multi-image output | Characters change across frames |
Wan2.7-Image directly addresses these limitations with a unified architecture + semantic understanding layer.
5 Core Features of Wan2.7-Image
1. Bone-Level Avatar Customization for Truly Unique Faces
Wan2.7-Image excels at “a unique face for every individual.” It supports fine-grained control over bone structure, eye shape (almond, phoenix, deep-set, puffy, smiling), facial contours, and subtle details. This eliminates the “standardized AI face” problem that plagued previous models.

Example prompt: “Photorealistic portrait of a 28-year-old East Asian woman, oval face, almond-shaped eyes, subtle smile, detailed skin texture, natural lighting.” Results show lifelike diversity ideal for virtual influencers, game NPCs, or personalized branding.
2. Precision Color Palette Control
One of the most practical features is the new color palette control. Alibaba says users can enter specific color codes and proportions to replicate artistic styles or lock in brand colors. The API docs formalize this with a color_palette parameter that accepts 3 to 10 colors, with 8 recommended. For brand teams, this is one of the clearest enterprise-oriented features in the release. No more random color shifts—perfect consistency across campaigns.
Official quote: “Say goodbye to random color generation. Achieve precise color ratios and bring your creative vision to life.” — Tongyi Wanxiang.
3. Advanced Multilingual Text Rendering (12 Languages, 3,000 Tokens)
Render ultra-long text, tables, formulas, charts, and infographics with print-quality clarity (A4-equivalent). Supports Chinese, English, Japanese, Korean, and 8 more languages. Academic papers, posters, product labels, and multilingual banners achieve near-perfect legibility—addressing a historic AI weakness.
4. Pixel-Precise Interactive Editing with Marquee Selection
Use bounding boxes (editRegions) or marquee tools for targeted changes. Upload up to 9 references and instruct edits like “change background to beach sunset while preserving face, pose, and clothing.” Pixel-level accuracy ensures identity preservation.
5. Multi-Image Compositional Generation (Up to 12 Sequential Images)
The model is designed for more than single-prompt generation. Alibaba says users can work with up to nine reference images and generate up to 12 images at once, which is ideal for coherent storyboards, architecture, and e-commerce series. The “click-to-edit” flow lets users select specific areas and make changes with pixel-level accuracy, and the API documentation adds interactive precise editing through a bounding-box parameter for local edits.
How Does Wan2.7-Image Work? (Technical Deep Dive)
Alibaba describes Wan2.7-Image as a framework that bridges language and visuals by training on large, diverse datasets. In plain terms, the model is not only learning how to draw images; it is also learning how prompts map to visual structure, composition, lighting, and text placement. That is what allows the model to interpret user intent more accurately than a basic text-to-image system.
The API also shows that the model is built for multimodal input. In practice, requests are sent through a single-turn messages structure, and the content can include both text and image items. For editing, users can pass multiple images plus instructions such as “move,” “replace,” or “blend” to guide the result. This is a clear sign that Wan2.7 is designed as a prompt-and-reference system rather than a simple one-shot generator.
The docs also expose a thinking mode setting. It is enabled by default and can improve output quality, but Alibaba notes that it increases generation time. That is a useful clue about the model’s workflow: higher-quality outputs may require more internal inference time, especially when the request is text-heavy or visually complex.
Wan2.7-Image employs a unified generation-editing framework in a shared latent space:
- Input Stage: Text prompt (up to 3,000 tokens) + optional reference images (up to 9).
- Semantic Parsing & Thinking Mode (enhanced in Pro): Chain-of-thought reasoning analyzes composition, spatial relationships, lighting, and logic before pixel generation.
- Shared Latent Space Mapping: Semantics map directly to visual features—no disconnected encoder/decoder gaps.
- Unified Inference: Generation or editing occurs in one optimized flow. Edit regions use bounding boxes; color palettes enforce ratios.
- Output: High-fidelity images (768–2048×2048 standard; 4K in Pro), with options for JPG/PNG/WEBP, seeds for reproducibility, and safety checks.
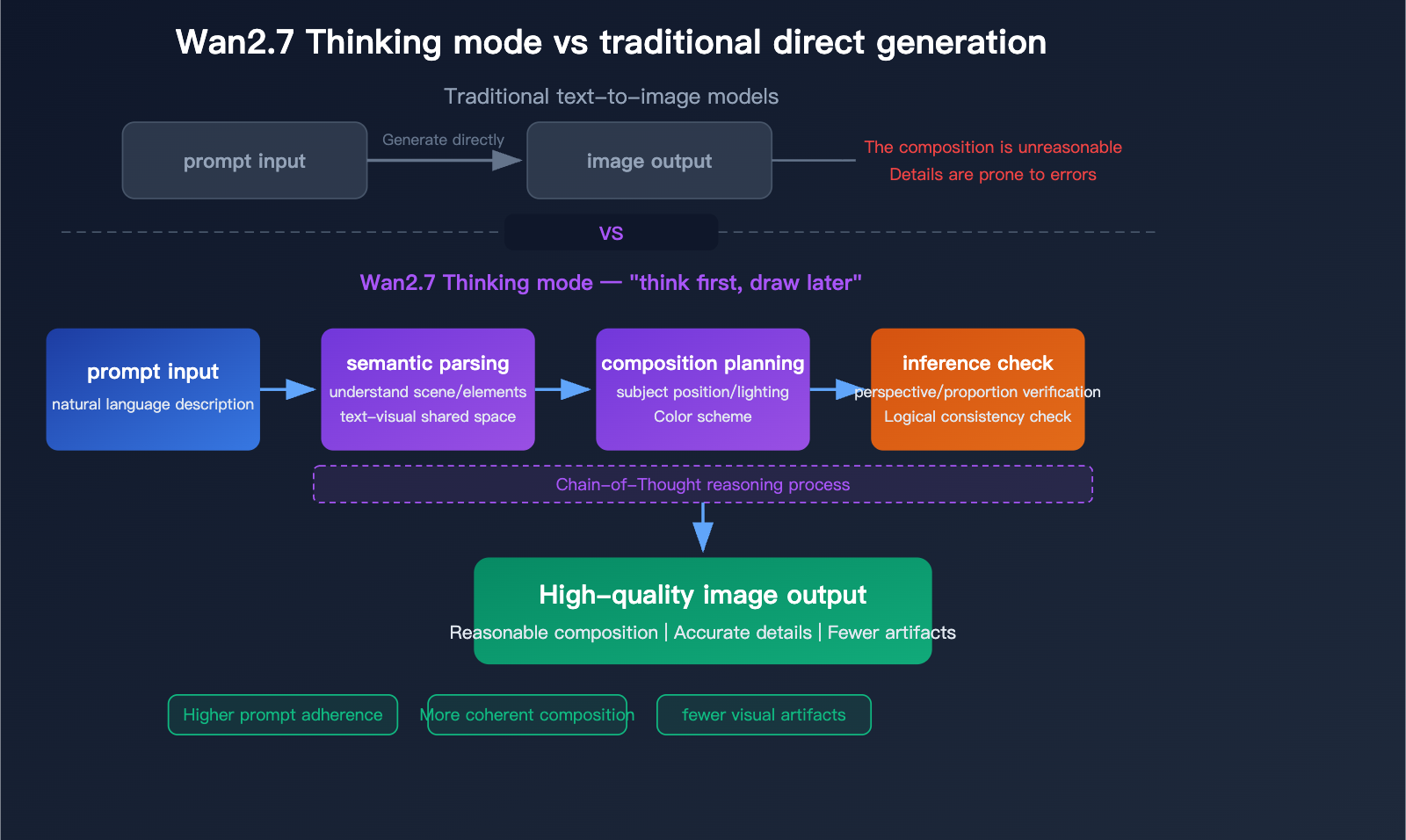
In-depth analysis of Wan2.7-Image-Pro: A new benchmark for AI image generation with 4K quality, reasoning mode, and 12-language text rendering - Apiyi.com Blog
Thinking mode flowchart (Pro) shows semantic parsing → composition planning → inference check, yielding fewer artifacts and higher prompt adherence versus direct generation.
Training on diverse datasets enables deep understanding of intent, lighting, and layout. Long-context learning (referenced in arXiv studies) powers extended text handling.
Wan2.7-Image vs Wan2.7-Image-Pro: Key Differences
Both versions launch simultaneously, but Pro targets professional needs.
| Feature | Wan2.7-Image (Standard) | Wan2.7-Image-Pro | Best For |
|---|---|---|---|
| Max Resolution | 2048×2048 | 4096×4096 (4K) | Print/production (Pro) |
| Thinking Mode | Available (faster default) | Enhanced/default with deeper reasoning | Complex scenes (Pro) |
| Composition Stability | Strong | Superior semantic understanding | Commercial projects (Pro) |
| Speed vs Quality | Faster iteration | Higher fidelity, slightly longer time | Prototyping (Standard) |
| Use Case | General creators, social content | Enterprise design, academic/print | Scalable vs precision |
Standard suits rapid prototyping; Pro delivers print-ready 4K with superior consistency.
How to Use Wan2.7-Image (Step-by-Step)
1. Access Platform
Available via:
- Alibaba Cloud (BaiLian platform)
- Wanxiang official tools
- CometAPI
2. Choose Workflow Mode
Mode A: Text-to-Image
Prompt example:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
Mode B: Image Editing
- Upload image
- Select area
- Input instruction
Example:
Replace background with a futuristic city
Mode C: Multi-Image Composition
- Upload multiple references
- Define composition rules
3. Fine-Tune Parameters
- Color palette
- Style consistency
- Text rendering
4. Export Output
- High-resolution images
- Commercial-ready assets
Benchmark Performance and Competitor Comparison
In blind human preference tests, Wan2.7-Image surpasses GPT-Image-1.5 in text-to-image quality and matches or exceeds Nano Banana Pro in text rendering, photorealism, and world knowledge.
Comparison Table:
| Model | Text Rendering | Instruction Following | Avatar Customization | Multi-Image Refs | Unified Gen/Edit | Resolution | Open-Source/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | Excellent (12 langs) | Superior (Thinking Mode) | Bone-level | 9 | Yes | 2K–4K | Yes/API |
| Midjourney V8 | Good | Moderate | Strong artistic | Limited | No | High | Discord only |
| FLUX | Good | Strong (simple) | Good | Limited | No | High | Yes |
| DALL-E 3 | Moderate | Good | Moderate | No | No | 2K | API |
| Nano Banana Pro | Strong | Strong editing | Good | Strong | Partial | High | Closed |
Wan2.7-Image leads in unified workflow, multilingual text, and precise control—especially valuable for non-English markets and professional pipelines.
CometAPI is a one-stop aggregation platform for large model APIs, offering seamless integration and management of API services, It supports multiple image generation APIs, such as GPT-image-1.5, Nano Banana series, Midjourney, and Qwen Image Series etc, at a lower price than the official website.
Who should use Wan2.7-Image
Wan2.7-Image is especially relevant for teams that need speed and flexibility rather than only one-off art generation. That includes performance marketers, product designers, e-commerce studios, social content teams, and agencies producing many variants from the same brief. The model’s support for multi-image input, multi-output generation, and instruction-based editing makes it particularly attractive for workflows where consistency, speed, and prompt control matter.
Real-World Use Cases
- Gaming/Entertainment: Generate 100 unique NPCs in minutes.
- Marketing/E-commerce: Brand-consistent carousels with exact color palettes.
- Education/Academia: Print-ready posters with formulas and tables.
- Design Agencies: Storyboards and client revisions via interactive editing.
Productivity gains come from fewer iterations and seamless reference integration.
Conclusion:
Alibaba Wan2.7-Image redefines AI creativity by unifying generation, editing, and understanding. Its 5 core features, shared latent space, and Pro enhancements deliver professional results that competitors still struggle to match. Whether prototyping social content or producing print-ready academic visuals, it offers unmatched precision and efficiency.
Start today at wan.video or via API in CometAPI. For developers and enterprises, the combination of power, accessibility, and data-backed superiority makes Wan2.7-Image the clear leader in unified AI image models for 2026 and beyond.