

يُعد Uni-1 من Luma AI أكثر من مجرد نموذج جديد لتحويل النص إلى صورة. ووفقًا لوصف Luma نفسها، فهو «نموذج استدلال متعدد الوسائط يمكنه توليد البكسلات»، ومبني على «الذكاء الموحّد» بحيث يمكنه فهم النية، والاستجابة للتوجيهات، و«التفكير معك». ويذكر التقرير التقني للشركة أن النموذج يستخدم محوّلًا توليديًا ذاتي الانحدار من نوع decoder-only، حيث تُمثَّل النصوص والصور في تسلسل متداخل واحد، وأن Uni-1 يمكنه إجراء استدلال داخلي منظّم قبل وأثناء توليد الصورة. وهذا المزيج هو ما يجعل Uni-1 أحد أكثر إصدارات نماذج الصور إثارة للاهتمام في عام 2026.
ما هو نموذج الصور UNI-1؟
Uni-1 هو نموذج الصور الجديد من Luma AI للمهام التي تتطلب الفهم والتوليد معًا داخل نظام واحد. وتعرضه Luma بوصفه نموذج استدلال متعدد الوسائط بدلًا من كونه محرك صور تقليديًا قائمًا على الانتشار فقط، وهذا مهم لأن النموذج مُصمم للقيام بأكثر من مجرد إنتاج مخرجات جذابة بصريًا: فهو مصمم لتفسير التعليمات، والحفاظ على قيود المراجع، والاستدلال عبر منطق المشهد كجزء من عملية التوليد. ويصف التقرير التقني للشركة Uni-1 بأنه أول نموذج موحّد لديها يجمع بين الفهم والتوليد على الطريق نحو الذكاء العام متعدد الوسائط.
لماذا يختلف Uni-1
للنهج القديم سقف واضح: فتوليد الصور دون فهم لا يمكن أن يصل إلا إلى حد معين. ويُطرح Uni-1 كخطوة نحو «الذكاء الموحّد»، حيث تُدار اللغة، والإدراك، والخيال، والتخطيط، والتنفيذ داخل بنية واحدة. وهذا أكثر من مجرد تسمية تسويقية. إذ يمكن لـ Uni-1 الانتقال من مجرد التشابه البصري إلى التكوين المقصود، والمعقولية، ومنطق المشهد.
والقصة الأكبر هي أن نماذج الصور أصبحت أكثر قدرة على التصرف كعوامل. فحزمة الصور الأحدث من Google تركز الآن على التحرير الحواري، والارتكاز إلى البحث، ودمج عدة صور، واتساق الشخصيات؛ بينما تركز عائلة GPT Image من OpenAI على التعددية الوسائط الأصلية واتباع التعليمات. ينضم Uni-1 إلى هذا التحول، لكنه يميل أكثر إلى فكرة أن النموذج ينبغي أن «يفكر» في الصورة قبل رسمها. وهذا يجعل Uni-1 مثيرًا للاهتمام بشكل خاص لسيناريوهات العمل التي تكون فيها الدقة وقابلية التكرار بنفس أهمية اللمسة البصرية.
كيف يعمل Uni-1 فعليًا؟
🔬 عملية تحويل البيانات إلى رموز
- النص → تسلسل رموز
- الصورة → رقع محوّلة إلى رموز
- تُدمج في تسلسل متداخل واحد
🔁 عملية التوليد
- إدخال الموجّه + المراجع
- ينفّذ النموذج استدلالًا داخليًا
- يخطط للتكوين
- يولّد الرموز بشكل تسلسلي
رياضيًا: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 طبقة الاستدلال الداخلي
يقوم Uni-1 بـ:
- تفكيك التعليمات
- حل القيود
- تخطيط التخطيط قبل التصيير
👉 هذه قفزة كبيرة مقارنةً بنماذج الانتشار.
التوليد الذاتي الانحدار من نوع Decoder-only
أهم تفصيلة تقنية هي أن Uni-1 ذاتي الانحدار وليس قائمًا على الانتشار. ويقول التقرير التقني لـ Luma إنه محوّل توليدي ذاتي الانحدار من نوع decoder-only، وأن النصوص والصور مُشفّرة داخل تسلسل متداخل واحد. وبعبارة أبسط، لا يبدأ النموذج فقط من الضوضاء ثم «يزيل الضوضاء» تدريجيًا للوصول إلى صورة. بل إنه يولّد الرموز خطوة بخطوة، مما يتيح له الاستدلال عبر الموجّه، وحل القيود، والتخطيط للتكوين قبل وأثناء التصيير.
🔬 عملية تحويل البيانات إلى رموز
- النص → تسلسل رموز
- الصورة → رقع محوّلة إلى رموز
- تُدمج في تسلسل متداخل واحد
الانتشار مقابل التوليد الذاتي الانحدار
| الميزة | نماذج الانتشار | Uni-1 (ذاتي الانحدار) |
|---|---|---|
| التوليد | ضوضاء → صورة | رمزًا بعد رمز |
| الاستدلال | محدود | قوي |
| التحرير | ضعيف | متعدد الجولات |
| عرض النص | ضعيف | قوي |
| التحكم | منخفض | مرتفع |
البنية الأساسية
Uni-1 هو:
- محوّل توليدي ذاتي الانحدار من نوع decoder-only
- مساحة رموز مشتركة للنصوص + الصور
هذه البنية مهمة لأنها تمنح النموذج فرصة للحفاظ على التماسك عندما يكون الموجّه معقدًا. وتقول Luma إن Uni-1 يستطيع تفكيك التعليمات، وحل القيود المتعارضة، والتخطيط للصورة قبل بدء التصيير. وهذا مفيد بشكل خاص لمهام مثل استكمال المشاهد المنظّمة، وتموضع عدة عناصر/أشخاص، والتحسين متعدد الجولات، والتعديلات التي تتطلب بقاء المخرجات وفية لصورة مرجعية مع الالتزام في الوقت نفسه بتعليمات جديدة.
ما الذي يبدو أن النموذج مُصمم للقيام به بشكل أفضل
إن تعلّم توليد الصور يحسّن الفهم. تقول Luma إن تدريب النموذج على توليد الصور يحسّن بشكل ملموس الفهم البصري الدقيق، خاصةً على مستوى المناطق، والعناصر، والتخطيطات. ولهذا لا يبدو Uni-1 كمولّد أحادي الاتجاه، بل كنظام موحّد يعزّز فيه التوليد والفهم أحدهما الآخر. وعلى مستوى الاستدلال، يعني هذا أن Uni-1 يحاول تقليص الفجوة بين «الرؤية» و«الصنع». وهذه قفزة كبيرة مقارنةً بنماذج الانتشار.
عملية التوليد:
- إدخال الموجّه + المراجع
- ينفّذ النموذج استدلالًا داخليًا
- يخطط للتكوين
- يولّد الرموز بشكل تسلسلي
رياضيًا: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
ما الميزات والمزايا الأساسية التي يقدمها Uni-1؟
اتباع قوي للتعليمات وقابلية عالية للتوجيه
أقوى نقطة بيع في Uni-1 هي التحكم. فالنموذج مبني من أجل التحرير الدقيق، والاستخدام المنظّم للمراجع، وسير العمل القابل للتكرار. وبالنسبة للمبدعين، فهذا يعني مراهنة أقل على الموجّهات ومخرجات أكثر قابلية للتكرار.
ومن المزايا العملية لـ Uni-1 أنه مبني للتكرار المتحكم فيه. إذ تسمح البذور للمستخدمين بإعادة إنتاج النتائج، بينما تساعد أدوار المراجع النموذج على معرفة ما إذا كان ينبغي للصورة أن توجه هوية الشخصية، أو الأجواء، أو لوحة الألوان، أو التكوين. وهذا يجعل Uni-1 أسهل في التوجيه من نموذج يعتمد فقط على الموجّهات، خاصةً للفرق التي تنتج الإعلانات، والقصص المصورة، ونماذج المنتجات، أو الأصول الخاصة بالعلامات التجارية حيث يكون الاتساق مهمًا.
توليد قائم على المراجع يحافظ على الهوية
من المزايا الكبيرة طريقة التعامل مع المراجع. إذ تصرّح Luma صراحةً بأن Uni-1 يستخدم عناصر تحكم مرتكزة إلى المصدر ويمكنه الحفاظ على الهوية، والتكوين، والقيود البصرية الأساسية من مرجع واحد أو أكثر. وهذا يجعله جذابًا لسير العمل التجاري مثل شخصيات العلامة التجارية، ونماذج المنتجات، وأصول الحملات، وأي مشروع يجب أن يبقى فيه الموضوع قابلًا للتعرّف عليه عبر عدة نسخ. وهذه من أوضح الطرق التي يختلف بها Uni-1 عن أنظمة الصور الأكثر تركيزًا على الجانب الجمالي فقط.
طلاقة ثقافية واتساع في الأساليب
تؤكد Luma أيضًا على التوليد الواعي بالثقافة. فقسم “Cultured” لديها يشير إلى الميمات، والمانغا، والمظاهر السينمائية، والصور العفوية، والرياضة، وصور الحيوانات، بما يوضح أن النموذج مخصص للعمل عبر لغات بصرية متعددة بدلًا من أسلوب عام واحد. وهذا مهم لأن نموذج الصور الحديث الجيد لا يحتاج فقط إلى تصيير مشهد واقعي؛ بل يحتاج أيضًا إلى فهم الأعراف البصرية لثقافة الإنترنت، والتصميم التحريري، والرسوم التوضيحية المنمقة، والمحتوى الاجتماعي.
التفكير متعدد الوسائط كخيار تصميمي
العامل الفارق الحقيقي ليس فقط أن Uni-1 يولّد الصور، بل إن Luma تؤطر توليد الصور بوصفه مهمة استدلالية. إذ يستطيع Uni-1 تنفيذ استدلال داخلي منظّم، كما أن تعلم توليد الصور يحسّن الفهم البصري الدقيق للمناطق، والعناصر، والتخطيطات. وهذا يشير إلى نموذج مُصمم لفهم المشهد قبل تصييره، بدلًا من مجرد تقريب الموجّه إحصائيًا.
معايير الأداء
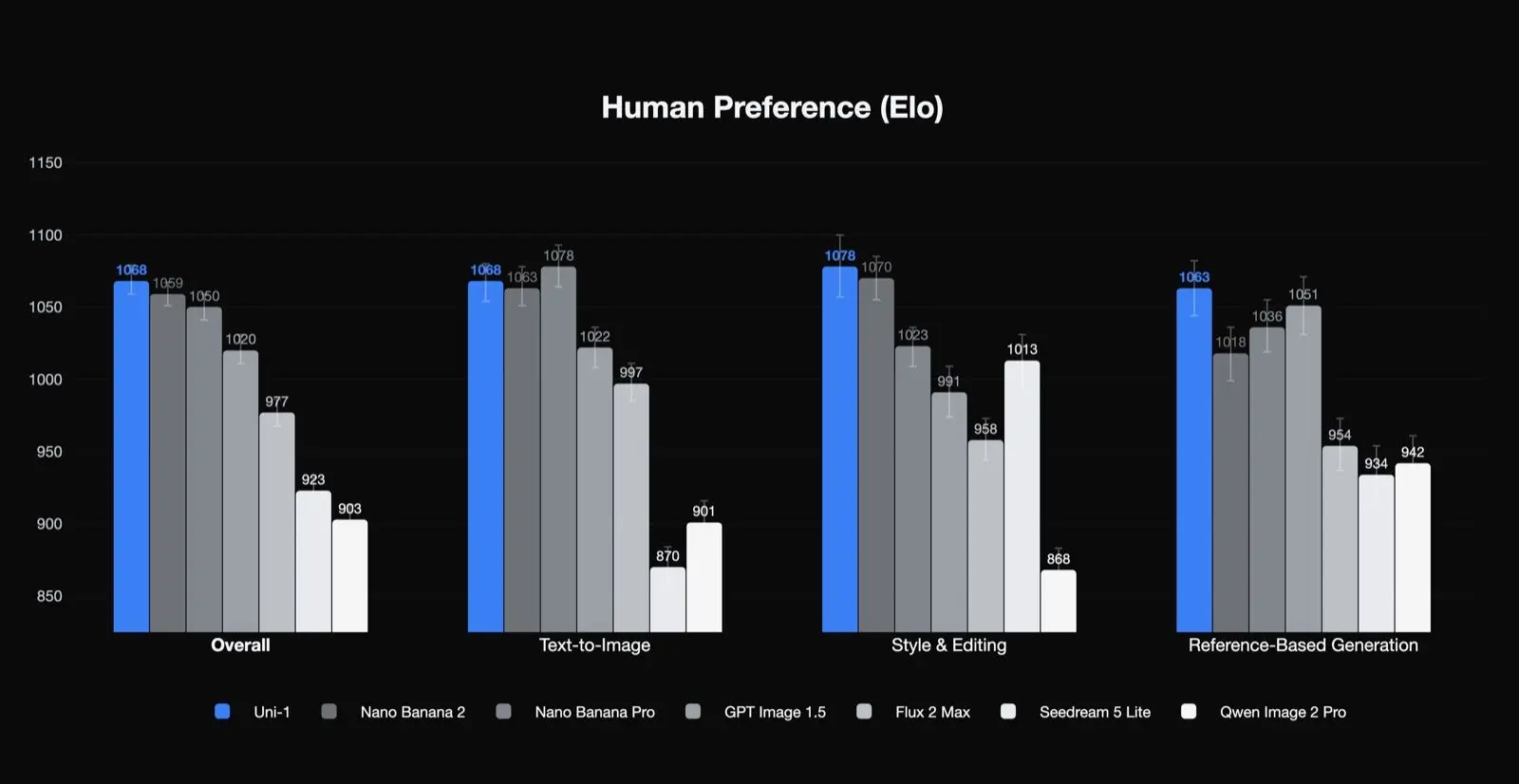
نتائج تفضيل البشر الخاصة بـ Luma
يحتل Uni-1 المركز الأول في Elo لتفضيلات البشر من حيث الجودة العامة، والأسلوب والتحرير، والتوليد المعتمد على المراجع، ويأتي ثانيًا في تحويل النص إلى صورة. وهذه نتيجة ذات دلالة لأنها تشير إلى أن النموذج قوي بشكل خاص في أنواع المهام التي تهتم بها فرق الإنتاج: التحرير، والاتساق، والتحويل الموجّه. كما تشير إلى أن أفضل حالات استخدامه قد لا تقتصر على التوليد الأحادي المباشر من النص إلى الصورة فقط.
RISEBench: التحرير البصري القائم على الاستدلال
أكثر المعايير لفتًا للانتباه هو RISEBench، الذي يقيّم التحرير البصري القائم على الاستدلال عبر الاستدلال الزمني، والسببي، والمكاني، والمنطقي. وتقول تقارير خارجية عن إطلاق Luma إن Uni-1 يحقق نتيجة إجمالية تبلغ 0.51 على RISEBench، متقدمًا على Nano Banana 2 من Google الذي حقق 0.50، وNano Banana Pro الذي حقق 0.49، وGPT Image 1.5 من OpenAI الذي حقق 0.46. وفي الاستدلال المكاني، يُذكر أن Uni-1 سجل 0.58 مقابل 0.47 لـ Nano Banana 2. وفي الاستدلال المنطقي، يُذكر أن Uni-1 سجل 0.32، أي أكثر من ضعف نتيجة GPT Image 1.5 البالغة 0.15. والفوارق ليست ضخمة إجمالًا، لكنها كبيرة في أصعب فئات الاستدلال.

ODinW-13 وادعاء أن «التوليد يحسّن الفهم»
يحقق Uni-1 أيضًا أداءً قويًا على ODinW-13، وهو معيار مفتوح المفردات للكشف الكثيف. وتقول التقارير عن البيانات التقنية لـ Luma إن النموذج الكامل يحقق 46.2 mAP، وهو قريب جدًا من Gemini 3 Pro من Google الذي يحقق 46.3. وتشير التقارير نفسها إلى أن نسخة الفهم فقط تحقق 43.9 mAP، ما يعني ضمنيًا أن تدريب التوليد يحسّن الفهم بمقدار 2.3 نقطة. وهذه ملاحظة مهمة لأنها تدعم الفرضية الأساسية لـ Luma: فقد يكون توليد الصور وفهم الصور هدفين يعززان بعضهما بعضًا بدلًا من أن يكونا متنافسين.
سعر واجهة Uni-1 API
| سعر الإدخال (نص) | $0.50 |
|---|---|
| سعر الإدخال (صور) | $1.20 |
| سعر الإخراج (النص والتفكير) | $3.00 |
| سعر الإخراج (الصور) | $45.45 |
على جانب المستهلك، تعرض صفحة الأسعار الخاصة بـ Luma باقة Plus بسعر $30/شهر، وPro بسعر $90/شهر، وUltra بسعر $300/شهر، مع أرصدة تجريبية مجانية مضمّنة في جميع الخطط. وهذا يعني أن هناك في الأساس مستويين من التسعير ينبغي أخذهما في الاعتبار: عضوية المستهلك للمنصة، وتسعير واجهة API على مستوى النموذج للاستخدام الإنتاجي.
في الوقت الحالي، واجهة Uni-1 API من CometAPI ستكون متاحة قريبًا، مع خصم مُعلن عند الإطلاق. وتقدم CometAPI حاليًا أيضًا نماذج صور خام ممتازة، مثل Midjourney وNano Banana 2.
Uni-1 مقابل GPT Image 1.5 مقابل Nano Banana 2
Uni-1 مقابل Nano Banana 2 من Google
يبدو أن Nano Banana 2 أقوى من حيث اتساع التعامل مع المراجع والتكامل مع المنظومة. إذ تؤكد Google على الارتكاز إلى البحث بالصور، والتكرار الحواري، وسير العمل المعتمد بكثافة على المراجع مع ما يصل إلى 14 مرجعًا. أما Uni-1، فعلى النقيض، فيُقدَّم بصورة أوضح على أنه يتمحور حول الاستدلال، ومعقولية المشهد، والتحرير الدقيق ضمن بنية نموذج موحّدة. وعمليًا، يبدو أن Google مُحسّنة للسرعة، ولحجم الإنتاج السائد، وللارتكاز الأصلي إلى Google؛ بينما يبدو أن Luma مُحسّنة للاستدلال البصري المنظّم والتحرير الصوري القابل للتوجيه.
وفي المقارنات العامة حول Uni-1، تبدو المفاضلة واضحة: يبدو أن Nano Banana 2 لا يزال قويًا جدًا في جودة وسرعة تحويل النص إلى صورة بشكل خالص، بينما يدفع Uni-1 بقوة أكبر نحو التحرير الكثيف الاستدلال، والتحكم بالمراجع، والالتزام بالتعليمات.
Uni-1 مقابل GPT Image من OpenAI
في تقارير المعايير، يتقدم Uni-1 على GPT Image 1.5 بفارق طفيف في النتيجة الإجمالية لـ RISEBench، وبفارق أوضح في الاستدلال المنطقي. ومقارنةً بعائلة GPT Image من OpenAI، يتموضع Uni-1 بشكل أضيق وأكثر هجومية حول الاستدلال البصري والتحرير المتحكم فيه. وتؤكد مستندات OpenAI على المعرفة بالعالم، والفهم متعدد الوسائط، والوعي السياقي؛ بينما تؤكد مستندات Luma على الاستدلال الداخلي المنظّم، والتحكم المرتكز إلى المراجع، ومهارة التحرير البصري المقاسة بالمعايير. لذلك، وبينما كلاهما متعدد الوسائط، فإن Uni-1 هو بشكل أوضح «نموذج استدلال متخصص في الصور»، في حين يبدو GPT Image أشبه بنظام متعدد الوسائط عام يجيد توليد الصور للغاية.
مقارنة الأسعار بين الثلاثة
فيما يتعلق بالتسعير، تعتمد المقارنة على حجم المخرجات وفئة المنتج، لذا فهي ليست مقارنة متكافئة تمامًا. فالسعر المنشور لـ Uni-1 المكافئ لـ 2048px يبلغ نحو $0.0909 لكل صورة. وتعرض صفحة التسعير الأحدث لنماذج الصور من Google سعر $0.134 لكل صورة 1K/2K وسعر $0.24 لكل صورة 4K لأحدث معاينة صور Gemini لديها، بينما تعرض صفحة تسعير GPT Image من OpenAI سعرًا لكل صورة يبلغ $0.011 عند الجودة المنخفضة لدقة 1024x1024، و$0.042 عند الجودة المتوسطة، و$0.167 عند الجودة العالية، مع مخرجات أكبر عالية الجودة بسعر $0.25. وبعبارة أخرى، يمكن أن تكون OpenAI أرخص بكثير عند الحد الأدنى، وتبدو Google قوية على مستوى السرعة والحجم، بينما يقع Uni-1 في المنتصف مع ملف سعر/أداء قوي موجّه نحو 2K.
الاختلافات الفلسفية
| النموذج | النهج |
|---|---|
| Uni-1 | ذكاء متعدد الوسائط موحّد |
| GPT Image | LLM + توليد صور |
| Nano Banana 2 | انتشار مُحسّن للإنتاج |
جدول مقارنة تفصيلي
| الميزة | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| البنية | ذاتي الانحدار | هجينة | انتشار |
| التوحيد متعدد الوسائط | ✅ أصلي | جزئي | ❌ |
| قدرة الاستدلال | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| جودة الصورة | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| عرض النص | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| سير عمل التحرير | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| السرعة | متوسطة | سريعة | سريعة |
| التحكم | مرتفع | متوسط | متوسط |
CometAPI توفّر صورًا خامًا تفاعلية لكل من GPT Image 1.5، وNano Banana 2، وUni-1 القادم، بالإضافة إلى البرمجة عبر API. وتجعل الأسعار المخفضة وخيارات الدفع حسب الاستخدام منها خيارًا مفضلًا للمطورين.
ما الذي يُعد Uni-1 الأفضل فيه
يبدو أن Uni-1 قوي بشكل خاص في الحالات التي تحتاج فيها إلى قابلية التكرار، أو اتساق الشخصيات، أو التحكم متعدد المراجع. ويشمل ذلك حملات العلامات التجارية، ونماذج المنتجات، والمفاهيم التحريرية، والقصص المصورة، ومتغيرات التوطين، وتعديلات الصور التي يجب أن يبقى فيها التكوين سليمًا بينما يتغير الأسلوب أو البيئة. وتميل أمثلة Luma نفسها بشدة إلى هذه الاستخدامات، كما أن تقسيم النموذج بين “Create vs Modify” هو في الأساس استجابة مباشرة لنقاط الألم الشائعة في الإنتاج.
إذا كان عملك في الأساس هو «اصنع شيئًا جميلًا من موجّه واحد»، فقد يبدو العامل الفارق أقل دراماتيكية. ولكن إذا كان سير عملك هو «أنشئ خمس نسخ مترابطة، واحتفظ بالشخصية نفسها، وحافظ على الإطار، وغيّر الإضاءة، واجعل النتيجة قابلة لإعادة الإنتاج الأسبوع المقبل»، فإن تصميم Uni-1 يبدأ في أن يبدو منطقيًا جدًا. وهذا استنتاج، لكنه يتبع طبيعيًا من خصائص التحكم التي تؤكد عليها Luma.
أفضل الممارسات للحصول على نتائج أفضل مع Uni-1
ابدأ باستخدام الوضع الصحيح. إرشادات Luma بسيطة: استخدم Create عندما تريد مشهدًا جديدًا، واستخدم Modify عندما تريد الحفاظ على مشهد موجود. خلط هاتين النيتين يجعل المخرجات أقل استقرارًا.
استخدم تسميات المراجع بطريقة احترافية. توصي Luma بعبارات مثل “Use IMAGE1 as a STYLE reference” أو “Use IMAGE2 as LIGHTING.” ويؤدي النموذج أداءً أفضل عندما يكون لكل مرجع وظيفة محددة، بدلًا من «إلهام» غامض.
ثبّت البذرة بعد أن تجد شيئًا جيدًا. توصي Luma صراحةً بالاستكشاف أولًا من دون بذرة، ثم حفظ البذرة بمجرد الوصول إلى نتيجة قوية. وبعد ذلك، غيّر متغيرًا واحدًا في كل مرة. وهذه أسهل طريقة لتحويل التوليد إلى نظام إنتاج متحكم فيه.
كن محددًا وملموسًا. تحذّر Luma من الكلمات المبهمة مثل “beautiful” أو “amazing”، وبدلًا من ذلك تشجع على أساليب مسماة مثل “1970s Italian giallo film poster” أو إشارات دقيقة لأسلوب الكاميرا. وعمليًا، تتفوق الموجّهات المحددة عادةً على الموجّهات الشعرية لأن النموذج يستطيع الارتكاز إلى بنية حقيقية.
استخدم سلسلة Create → Modify. تؤكد Luma صراحةً أن هذا من أقوى سير العمل لديها: الاستكشاف في Create، ثم التحسين في Modify. وهذه هي النقطة المثالية لأعمال الإنتاج الجادة، لأنها تقلل من التراجع وتحافظ على الأجزاء الجيدة من التكوين مع إحكام التفاصيل.
الحكم النهائي
يُعد Uni-1 أوضح تصريح حتى الآن من Luma بأن توليد الصور ينتقل من «موجّه يدخل، صورة تخرج» إلى إنشاء بصري موجَّه بالاستدلال. وتتمثل نقاط قوته المعلنة في التحكم، والتعامل مع المراجع، وقابلية إعادة الإنتاج، وبنية نموذج تُبقي اللغة والبكسلات داخل النظام نفسه.
وبالنسبة للمبدعين والفرق الذين يهتمون بمخرجات بصرية عالية الجاذبية، وشخصيات متسقة، وتعديلات دقيقة، ووضوح التسعير للدقات العالية، فإن Uni-1 نموذج يستحق المتابعة فعلًا. وإذا جاء إطلاق واجهة API بشكل سلس، فقد يصبح أحد أكثر البدائل إثارة للاهتمام أمام Nano Banana 2 من Google وGPT Image 1.5 من OpenAI في عام 2026.
هل تخطط لبدء إنشاء الصور الخام؟ ترحب بك CometAPI، وهي منصة تجميع شاملة لواجهات API الخاصة بالنماذج متعددة الوسائط!