

Alibaba Wan2.7-Image, udgivet den 1. april 2026, markerer et stort spring i AI-billedgenerering. Denne forenede model integrerer tekst-til-billede-skabelse, interaktiv redigering, multi-billede-komposition og semantisk forståelse i en enkelt arkitektur. I modsætning til traditionelle adskilte pipelines til generering og redigering eliminerer den inkonsistenser som “standardiserede AI-ansigter”, forvansket tekst og uforudsigelige farver.
Skabere, designere, marketingfolk og virksomheder opnår nu fotorealistiske, instruktionstro resultater med færre iterationer. Modellen understøtter op til 12 sekventielle billeder, 9 referencefusioner, tekstrendering på 12 sprog (op til 3,000 tokens) og kontrol på pixelniveau.
Hvad er Wan2.7-Image?
Wan2.7-Image er Alibabas Tongyi Lab flagskibs-forenede billedmodel i Wan (Tongyi Wanxiang)-serien. Den håndterer end-to-end visuelle workflows: tekst-til-billede-generering, billede-til-billede-transformation, kommandobaseret redigering og interaktive finjusteringer på pixelniveau—alt i ét delt latent rum.
Udgivet 1. april 2026 bygger den på tidligere Wan 2.x-videomodeller (som toppede VBench-benchmarks) ved at flytte fokus til billedpræcision. Den går direkte i kødet på “æstetisk træthed” fra gentagende ansigter, ustabile farver og dårlig prompt-tilpasning, som var almindeligt i tidligere AI-værktøjer. Modelfamilien inkluderer to navne, der betyder mest for brugere: wan2.7-image og wan2.7-image-pro. Standardversionen er tunet til hurtigere genereringshastighed, mens Pro-versionen sigter mod professionelt output, med 4K højopløsningsstøtte.
Nøgle-differentiering: forenet arkitektur. Traditionelle modeller bruger adskilte trin (encoder → diffusion → decoder), der kræver separat inpainting til redigeringer. Wan2.7-Image kortlægger semantik direkte i et delt rum, hvilket muliggør reel forståelse frem for pixelmønster-matchning.
Hvorfor Wan2.7-Image er vigtig (branchekontekst)
Traditionelle AI-billedværktøjer lider af:
| Problem | Forklaring |
|---|---|
| Fragmenteret arbejdsflow | Separate værktøjer til generering, redigering, inpainting |
| “AI-ansigtssyndrom” | Gentagende, urealistiske menneskeansigter |
| Svag efterlevelse af instruktioner | Prompter følges ikke præcist |
| Dårlig tekstrendering | Forvrænget eller ulæselig tekst |
| Inkonsistent multi-billede-output | Karakterer ændrer sig på tværs af billeder |
Wan2.7-Image adresserer direkte disse begrænsninger med en forenet arkitektur + semantisk forståelseslag.
5 kernefunktioner i Wan2.7-Image
1. Avatar-tilpasning på skeletniveau for virkelig unikke ansigter
Wan2.7-Image excellerer i “et unikt ansigt til hver person”. Den understøtter finkornet kontrol over knoglestruktur, øjenform (mandel-, føniks-, dybtliggende, hævede, smilende), ansigtskonturer og subtile detaljer. Dette eliminerer problemet med “standardiserede AI-ansigter”, der plagede tidligere modeller.

Eksempelprompt: “Fotorealistisk portræt af en 28-årig østasiatisk kvinde, ovalt ansigt, mandelformede øjne, subtilt smil, detaljeret hudtekstur, naturlig belysning.” Resultaterne viser livagtig diversitet ideel til virtuelle influencere, spil-NPC'er eller personlig branding.
2. Præcis kontrol over farvepalet
En af de mest praktiske funktioner er den nye farvepalet-kontrol. Alibaba siger, at brugere kan indtaste specifikke farvekoder og proportioner for at genskabe kunstneriske stilarter eller låse brandfarver. API-dokumentationen formaliserer dette med en color_palette-parameter, der accepterer 3 til 10 farver, med 8 anbefalet. For brandteams er dette en af de mest klare virksomhedsorienterede funktioner i udgivelsen. Ikke flere tilfældige farveskift—perfekt konsistens på tværs af kampagner.
Officitel udtalelse: “Sig farvel til tilfældig farvegenerering. Opnå præcise farveforhold og bring din kreative vision til live.” — Tongyi Wanxiang.
3. Avanceret flersproget tekstrendering (12 sprog, 3,000 tokens)
Render ultralang tekst, tabeller, formler, diagrammer og infografikker med trykklar kvalitet (svarende til A4). Understøtter kinesisk, engelsk, japansk, koreansk og 8 andre sprog. Fagartikler, plakater, produktetiketter og flersprogede bannere opnår næsten perfekt læsbarhed—en historisk svaghed i AI adresseres.
4. Interaktiv redigering på pixelniveau med rektangulær markering
Brug afgrænsningsbokse (editRegions) eller marquee-værktøjer til målrettede ændringer. Upload op til 9 referencer og instruér redigeringer som “skift baggrund til strand-solnedgang, mens ansigt, positur og tøj bevares.” Nøjagtighed på pixelniveau sikrer identitetsbevarelse.
5. Kompositionel generering med flere billeder (op til 12 sekventielle billeder)
Modellen er designet til mere end enkelt-prompt-generering. Alibaba siger, at brugere kan arbejde med op til ni referencebilleder og generere op til 12 billeder på én gang, hvilket er ideelt til sammenhængende storyboard, arkitektur og e-handelserier. “Klik-til-redigering”-flowet lader brugere vælge specifikke områder og foretage ændringer med nøjagtighed på pixelniveau, og API-dokumentationen tilføjer interaktiv præcis redigering via en afgrænsningsboks-parameter til lokale redigeringer.
Hvordan fungerer Wan2.7-Image? (teknisk dybdegående)
Alibaba beskriver Wan2.7-Image som en ramme, der bygger bro mellem sprog og visuelle elementer ved at træne på store, mangfoldige datasæt. Kort fortalt lærer modellen ikke kun at tegne billeder; den lærer også, hvordan prompter kortlægges til visuel struktur, komposition, belysning og tekstplacering. Det er det, der gør modellen i stand til at fortolke brugerintention mere præcist end et grundlæggende tekst-til-billede-system.
API'en viser også, at modellen er bygget til multimodal input. I praksis sendes forespørgsler gennem en enkelttur-beskedstruktur, og indholdet kan omfatte både tekst- og billedelementer. Til redigering kan brugere sende flere billeder plus instruktioner som “flyt”, “erstat” eller “blend” for at styre resultatet. Det er et klart tegn på, at Wan2.7 er designet som et prompt-og-reference-system snarere end en simpel one-shot-generator.
Dokumentationen eksponerer også en indstilling for tænketilstand. Den er aktiveret som standard og kan forbedre outputkvaliteten, men Alibaba bemærker, at den øger genereringstiden. Det er et nyttigt fingerpeg om modellens workflow: højere kvalitet kan kræve mere intern inferenstid, især når forespørgslen er teksttung eller visuelt kompleks.
Wan2.7-Image anvender en forenet genererings- og redigeringsramme i et delt latent rum:
- Inputfase: Tekstprompt (op til 3,000 tokens) + valgfrie referencebilleder (op til 9).
- Semantisk parsing & tænketilstand (forbedret i Pro): Trinvist ræsonnement analyserer komposition, rumlige relationer, belysning og logik, før pixelgenerering.
- Kortlægning til delt latent rum: Semantik kortlægges direkte til visuelle træk—ingen adskilte encoder/decoder-huller.
- Forenet inferens: Generering eller redigering sker i ét optimeret flow. Redigeringsområder bruger afgrænsningsbokse; farvepaletter håndhæver forhold.
- Output: Høj-trofastheds-billeder (768–2048×2048 standard; 4K i Pro), med muligheder for JPG/PNG/WEBP, seed-værdier for reproducerbarhed og sikkerhedstjek.
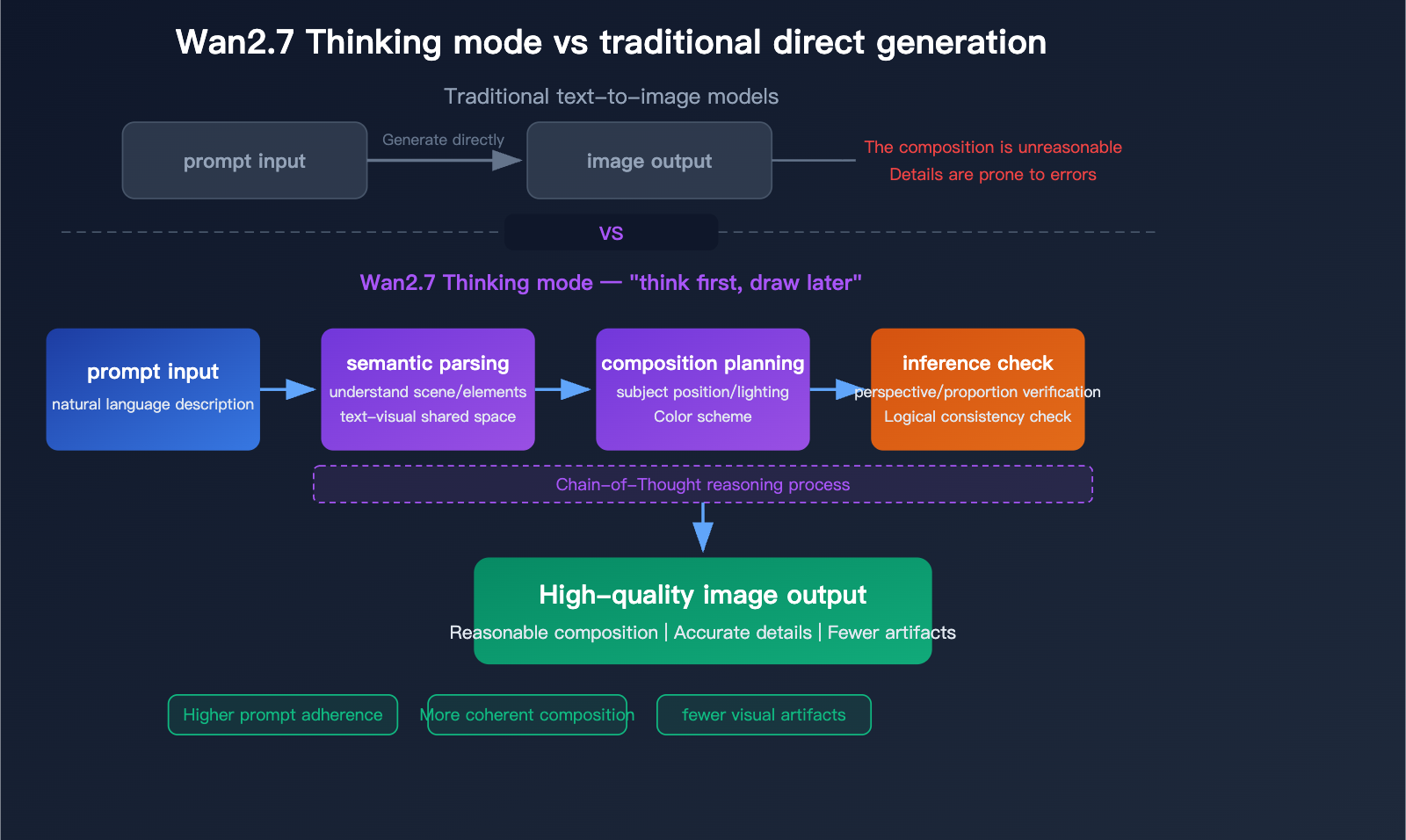
Dybdegående analyse af Wan2.7-Image-Pro: En ny målestok for AI-billedgenerering med 4K-kvalitet, tænketilstand og tekstrendering på 12 sprog - Apiyi.com Blog
Flowchart for tænketilstand (Pro) viser semantisk parsing → kompositionsplanlægning → inferens-tjek, hvilket giver færre artefakter og højere prompt-efterlevelse end direkte generering.
Træning på mangfoldige datasæt muliggør dyb forståelse af intention, belysning og layout. Læringskapacitet for lange kontekster (refereret i arXiv-studier) driver udvidet teksthåndtering.
Wan2.7-Image vs Wan2.7-Image-Pro: vigtige forskelle
Begge versioner lanceres samtidigt, men Pro retter sig mod professionelle behov.
| Funktion | Wan2.7-Image (Standard) | Wan2.7-Image-Pro | Bedst til |
|---|---|---|---|
| Maks. opløsning | 2048×2048 | 4096×4096 (4K) | Print/produktion (Pro) |
| Tænketilstand | Tilgængelig (hurtigere standard) | Forbedret/standard med dybere ræsonnement | Komplekse scener (Pro) |
| Kompositionsstabilitet | Stærk | Overlegen semantisk forståelse | Kommercielle projekter (Pro) |
| Hastighed vs. kvalitet | Hurtigere iteration | Højere troskab, lidt længere tid | Prototyping (Standard) |
| Brugsscenarie | Almindelige skabere, socialt indhold | Enterprise-design, akademisk/print | Skalerbarhed vs. præcision |
Standard passer til hurtig prototyping; Pro leverer tryk-klar 4K med overlegen konsistens.
Sådan bruger du Wan2.7-Image (trin for trin)
1. Få adgang til platformen
Tilgængelig via:
- Alibaba Cloud (BaiLian-platformen)
- Wanxiang officielle værktøjer
- CometAPI
2. Vælg workflow-tilstand
Tilstand A: Tekst-til-billede
Prompt-eksempel:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
Tilstand B: Billedredigering
- Upload billede
- Vælg område
- Indtast instruktion
Eksempel:
Replace background with a futuristic city
Tilstand C: Multi-billede-komposition
- Upload flere referencer
- Definér kompositionsregler
3. Finjuster parametre
- Farvepalet
- Stil-konsistens
- Tekstrendering
4. Eksporter output
- Højopløsningsbilleder
- Kommercielt klare aktiver
Benchmark-ydeevne og konkurrentsammenligning
I blinde præferenstests blandt mennesker overgår Wan2.7-Image GPT-Image-1.5 i tekst-til-billede-kvalitet og matcher eller overgår Nano Banana Pro i tekstrendering, fotorealisme og viden om verden.
Sammenligningstabel:
| Model | Tekstrendering | Efterlevelse af instruktioner | Avatar-tilpasning | Flere billedreferencer | Forenet generering/redigering | Opløsning | Open source/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | Fremragende (12 sprog) | Overlegen (tænketilstand) | Skeletniveau | 9 | Ja | 2K–4K | Ja/API |
| Midjourney V8 | God | Moderat | Stærk kunstnerisk | Begrænset | Nej | Høj | Kun Discord |
| FLUX | God | Stærk (enkel) | God | Begrænset | Nej | Høj | Ja |
| DALL-E 3 | Moderat | God | Moderat | Nej | Nej | 2K | API |
| Nano Banana Pro | Stærk | Stærk redigering | God | Stærk | Delvis | Høj | Lukket |
Wan2.7-Image fører an i forenet workflow, flersproget tekst og præcis kontrol—særligt værdifuldt for ikke-engelske markeder og professionelle pipelines.
CometAPI er en alt-i-en aggregeringsplatform for store model-API'er, som tilbyder problemfri integration og styring af API-tjenester. Den understøtter flere billedgenererings-API'er, såsom GPT-image-1.5, Nano Banana series, Midjourney og Qwen Image Series m.fl., til en lavere pris end den officielle hjemmeside.
Hvem bør bruge Wan2.7-Image
Wan2.7-Image er særligt relevant for teams, der har brug for hastighed og fleksibilitet frem for kun enkeltstående kunstgenerering. Det omfatter performance-marketingfolk, produktdesignere, e-handelsstudier, sociale indholdsteams og bureauer, der producerer mange varianter ud fra samme brief. Modellens støtte til multi-billede-input, multi-output-generering og instruktionsbaseret redigering gør den særligt attraktiv til workflows, hvor konsistens, hastighed og prompt-kontrol er afgørende.
Virkelige anvendelsestilfælde
- Gaming/underholdning: Generér 100 unikke NPC'er på få minutter.
- Marketing/e-handel: Brand-konsistente karusseller med præcise farvepaletter.
- Uddannelse/akademia: Tryk-klare plakater med formler og tabeller.
- Designbureauer: Storyboards og kundeændringer via interaktiv redigering.
Produktivitetsgevinster kommer fra færre iterationer og problemfri referenceintegration.
Konklusion:
Alibaba Wan2.7-Image redefinerer AI-kreativitet ved at forene generering, redigering og forståelse. Dets 5 kernefunktioner, delte latente rum og Pro-forbedringer leverer professionelle resultater, som konkurrenter stadig har svært ved at matche. Uanset om du prototyper socialt indhold eller producerer tryk-klare akademiske visuals, tilbyder den uovertruffen præcision og effektivitet.
Start i dag på wan.video eller via API i CometAPI. For udviklere og virksomheder gør kombinationen af styrke, tilgængelighed og databåret overlegenhed Wan2.7-Image til den klare frontløber inden for forenede AI-billedmodeller i 2026 og fremover.