

GLM-5-Turbo er en ny grundmodel-LLM fra Zhipu AI, der er specifikt trænet og tunet til agent-orienterede arbejdsflows (virksomheden kalder det målrettede økosystem OpenClaw / “lobster”-scenarier). Den tilbyder en meget lang kontekst (op til ~200K tokens), streaming og strukturerede output, lavere fejlrate ved værktøjsopkald (rapporteret ~0,67% i tredjepartstests) og væsentligt lavere pris pr. token. Modellen har til formål at bytte en lille mængde topgennemstrømning i enkelt-omgange for langt bedre stabilitet, værktøjsreliabilitet, håndtering af planlagte/vedvarende opgaver og langkædet eksekvering—nyttigt for autonome agenter, orkestreringssystemer og pipelines med flere værktøjer.
Hvad er GLM-5-Turbo?
GLM-5-Turbo præsenteres af Zhipu som en grundmodel, der er formålsbygget til agent-orkestrering og komplekse automatiserede arbejdsflows frem for som en generel chat- eller multimodal model. Designvalgene understreger:
- Naturligt agentvenlig træning (værktøjsbrug, kommando-efterfølgning, tidsbestemte/vedvarende opgaver).
- Meget store kontekstvinduer og outputkapacitet til at understøtte lange sessioner, hukommelse og planlægning af kæde-af-tanke.
- Stabil, høj-gennemstrømnings inferens til lange forretningsflows og planlagte opgaver.
I modsætning til traditionelle LLM’er, der er optimeret til chat eller tekstgenerering, er GLM-5-Turbo:
- Agent-først (ikke chat-først)
- Bygget til OpenClaw (“lobster”)-miljøer
- Designet til autonome arbejdsflows i flere trin
🦞 Hvad betyder “Lobster Agent”?
“Lobster”-begrebet refererer til OpenClaw, Zhipus AI-agentøkosystem, hvor modeller:
- Bruger værktøjer dynamisk
- Eksekverer lange kæder af opgaver
- Opretholder vedvarende hukommelse
- Opererer på tværs af terminaler, apps og API’er
GLM-5-Turbo er dybt optimeret til dette paradigme og løser centrale agentproblemer som:
- Reliabilitet for værktøjsopkald
- Opgavedekomponering
- Langsigtet planlægning
- Udførelsesstabilitet
Nøglefunktioner og hvorfor de er vigtige
Lang kontekst + enorm outputkapacitet (200K / 128K)
Et kontekstvindue på 200K tokens og 128K outputkapacitet gør det muligt for GLM-5-Turbo at:
- Holde udvidet hukommelse om tidligere kontekst (samtaler, værktøjsoutput, mellemliggende resultater).
- Producere meget lange genererede artefakter (flertrinsplaner, lange rapporter, kodebaser) uden gentagen kontekst-sammensyning.
- Huse multi-turn agenter, der skal bevare hele eksekveringshistorikken for nøjagtig beslutningstagning.
Dette er et bevidst teknisk valg for agenter — i stedet for at splitte opgaver i korte prompts, kan agenter opretholde koherent tilstand gennem tusinder af samtaleomgange eller trin.
Agent-primitiver indbygget i træningen
I stedet for at retrofitte en generel model til agentopgaver, blev GLM-5-Turbo trænet med agent-stil mål (f.eks. værktøjsopkaldsadfærd, kommando-/argumentparsing). Den påståede effekt er færre hallucinationer under værktøjsopkald, mere stabile planer i flere trin og forbedret latenstid under lange forløb — alt værdifuldt, hvor automatisering skal kæde mange eksterne API’er eller værktøjer pålideligt.
Gennemstrømning og udførelsesstabilitet
GLM-5-Turbo-varianten forbedrer udførelsesstabilitet og gennemstrømning for lange forretningsflows sammenlignet med generelle store modeller — marketing-sproget fremhæver "høj gennemstrømnings eksekvering" og "førende responsstabilitet" blandt lignende modeller. Disse er meningsfulde for enterprise-agent-udrulninger, hvor et mislykket trin kan bryde hele pipelinen. Uafhængige tredjepartsbenchmarks er stadig under udvikling.
Benchmark-data for GLM-5-Turbo
Bemærk: Zhipu har offentliggjort interne evalueringer, og tredjeparts/akademiske benchmarks for GLM-5 er tilgængelige. GLM-5-Turbo er nyligt udgivet; uafhængige community-benchmarkkørsler vil tage tid at fremkomme. Nedenfor lister vi de mest forsvarlige, offentliggjorte tal og kontekst.
GLM-5 (reference) — repræsentative offentliggjorte målinger
Zhipus GLM-5 (flagskibsforgængeren til Turbo) rapporterer stærke placeringer i mange ingeniør-/workflow-opgaver — for eksempel:
- SWE-bench Verified: 77.8 (rapporteret i GLM-5-dokumentationen som en førende score for open-modeller).
- Terminal Bench 2.0: 56.2 (rapporteret som top-ydeevne for open-modeller på den givne distribution).
Disse tal etablerer GLM-5 som en høj baseline i softwareengineering- og eksekveringsopgaver; GLM-5-Turbo er positioneret til at bytte noget rå størrelse/parameterfokus for bedre agentreliabilitet og gennemstrømning. GLM-5-Turbo viste ~0,67% værktøjsopkaldsfejl i deres sammenligningskørsler, væsentligt lavere end GLM-5-udbyderkørsler, der spændte fra ~2,33% til 6,41%.
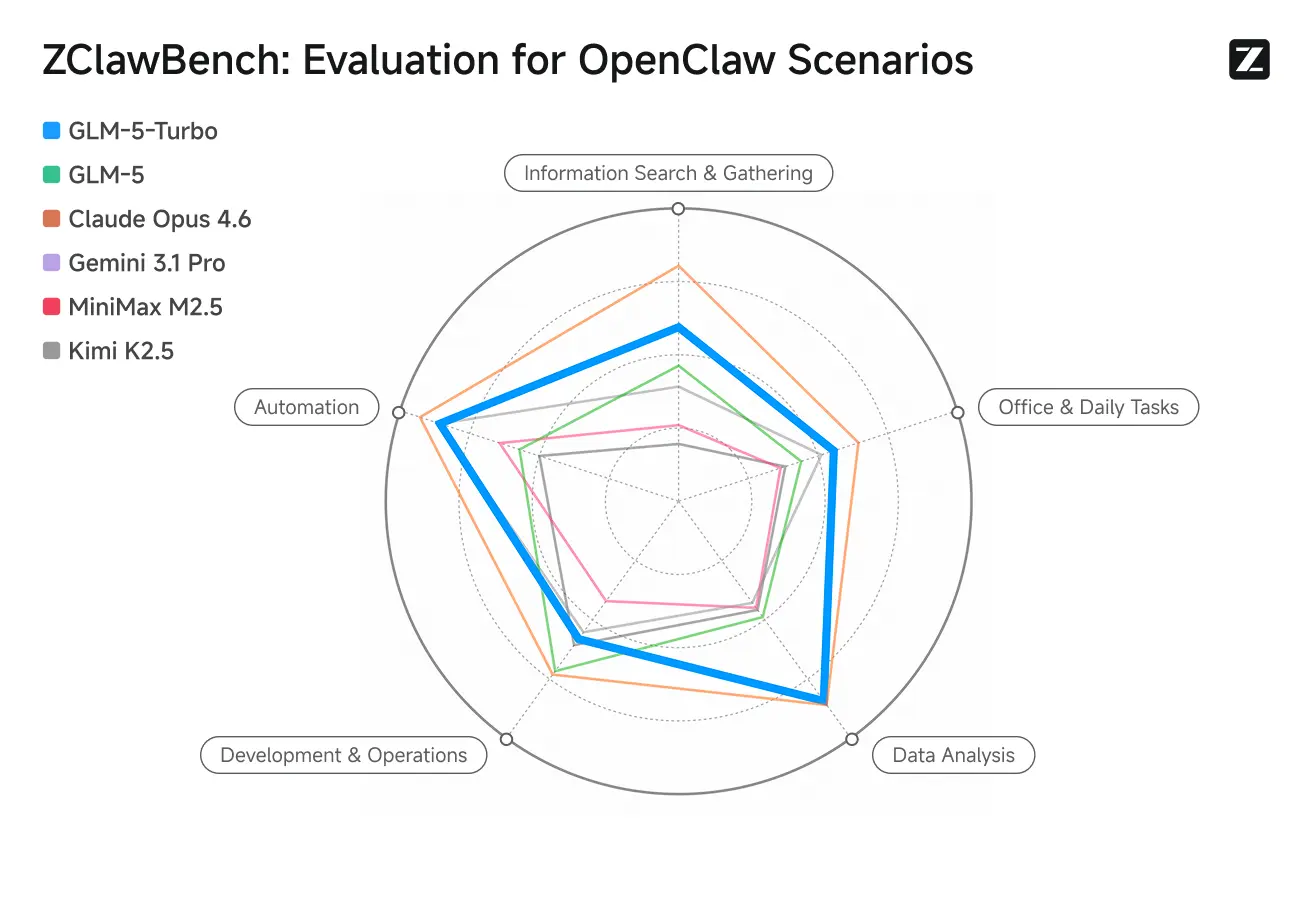
ZClawBench: Benchmark-test for OpenClaw-proxyscenarier
Zhipu udgav også ZClawBench-benchmarket til evaluering af intelligente agenter. I blindtests, der dækker forskellige felter såsom kodeudvikling, dataanalyse og indholdsproduktion, vandt den nye model med kodenavn Pony-Alpha-2 90% af respondenternes gunst.
Priser og tilgængelighed (hvem sælger den og til hvilken pris)
Zhipu implementerede en ~20% API-prisstigning for GLM-5-Turbo-tilbuddet ved lancering og introducerede samtidig “Lobster Package”-abonnementsniveauer, der skal udjævne token-prissætningen for agentudrulninger.
Rapporterede abonnementsniveauer (eksempelpakker)
To illustrative Lobster-pakker (priser er rapporterede konverteringer og omtrentlige):
- Entry Lobster-plan: ~39 CNY / måned (~US$5,66) for 35,000,000 tokens.
- Mid Lobster-plan: ~99 CNY / måned (~US$14,36) for 100,000,000 tokens.
Med disse offentliggjorte tal er omkostningen per 1 million tokens cirka:
- Entry-plan: ~US$0,162 per 1M tokens.
- Mid-plan: ~US$0,144 per 1M tokens.
Disse per-1M-tal er simple konverteringer af den offentliggjorte abonnementspris og tokenloft og illustrerer økonomien for agentarbejdsbelastninger med højt volumen. (Beregninger baseret på presse-rapporteret valuta og tokenmængder.)
API-pris
Repræsentativ marketplace-listing (CometAPI): $0,96 per 1M input tokens og $3,20 per 1M output tokens for GLM-5-Turbo.
Zhipus egen (Z.ai) udvikler-prisside angiver en lidt højere direkte sats for GLM-5-Turbo: $1,20 per 1M input tokens og $4,00 per 1M output tokens (cached input-satser er lavere).
GLM-5-Turbo vs GLM-5 — side-om-side sammenligning
På et overordnet niveau:
- GLM-5 = flagskibs alsidig grundmodel (stærk ræsonnering, kodning, benchmarks)
- GLM-5-Turbo = agent-optimeret variant af GLM-5 (fokuseret på lange arbejdsflows, værktøjsbrug, stabilitet)
GLM-5-Turbo er ikke en helt ny modelarkitektur, men en specialiseret, produktionsoptimeret version af GLM-5 designet til agentsystemer som OpenClaw.
Kernepositionering
| Model | Positionering |
|---|---|
| GLM-5 | Alsidig flagskibs-LLM (ræsonnering, kodning, benchmarks) |
| GLM-5-Turbo | Agent-først model (automatisering, orkestrering, værktøjsbrug) |
👉 Kort fortalt:
- Brug GLM-5 → når du ønsker maksimal intelligens
- Brug GLM-5-Turbo → når du ønsker stabil automatisering / agenter
Agentkapacitets-sammenligning (VIGTIGST)
GLM-5 (agentkapacitet) understøtter allerede:
- Værktøjsbrug
- Ræsonnering i flere trin
- Kodeagenter
Men begrænsninger:
- Kan miste kontekst i lange kæder
- Værktøjsopkald kan forringes over tid
- Kræver mere orkestreringslogik
GLM-5-Turbo er eksplicit optimeret til agenter:
Nøgleforbedringer:
- Reliabilitet for værktøjsopkald ↑
- Opgavedekomponering (planlægning) ↑
- Konsistens i lange kæder ↑
- Understøttelse af vedvarende eksekvering ↑
Eksempelforbedring:
- Stabil eksekvering over 10+ trin uden at miste kontekst
👉 Dette er kritisk for:
- Systemer i AutoGPT-stil
- Arbejdsflows med flere agenter
- SaaS-automatisering
Hastighed og effektivitet
| Aspekt | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Inferenshastighed | Moderat | Hurtigere |
| Gennemstrømning | Standard | Højere |
| Latenstid ved lange opgaver | Kan forringes | Optimeret |
GLM-5-Turbo er designet til at løse et reelt brancheproblem:
Store modeller bliver langsomme eller bryder under lange arbejdsflows
Pris-sammenligning
| Model | Inddata ($/1M tokens) | Uddata ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1,00 | ~$3,20 |
| GLM-5-Turbo | ~$1,20 | ~$4,00 |
👉 GLM-5-Turbo er dyrere (~20% højere)
Hvorfor dyrere?
Fordi den leverer:
- Bedre orkestreringsreliabilitet
- Højere produktionsstabilitet
- Agent-specifikke optimeringer
👉 I enterprise:
- Du betaler mere pr. token
- Men reducerer fejlomkostninger + retries
| Attribute | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Primært mål | Flagskibs-alsidig grundmodel (brede kapabiliteter, stærk kodning/benchmarks) | Agent/“OpenClaw” / lobster-optimeret grundmodel |
| Kontekstvindue | (rapporteret højt; GLM-5 fokuserer ~200K (GLM-5 understøtter også lang kontekst)) | 200.000 tokens (eksplicit dokumenteret). |
| Maksimale output-tokens | (store, modelafhængige) | 128.000 tokens (dokumenteret). |
| Bemærkelsesværdige benchmark-scorer | SWE-bench: 77,8; Terminal Bench 2.0: 56,2 (GLM-5 rapporterede tal). | Interne evalueringer hævder forbedret stabilitet i lange kæder og gennemstrømning for agentarbejdsflows; uafhængige offentlige benchmarks afventer. |
| Modaliteter | Tekst (primær), GLM-familien har vision-varianter i søskendemodeller | Kun tekst (ifølge docs) — optimeret til værktøjsbaserede agenter. |
| Anbefalede anvendelser | Brede: chat, kode, ræsonnering, indhold | Agent-orkestrering, værktøjsopkald, lang-horisont-automatisering |
| Prissætning | Eksisterende GLM-5-priser (varierer pr. plan) | Ny lancering — rapporteret ~20% API-prisstigning; nye Lobster-abonnementsniveauer introduceret |
Sådan bruger du GLM-5-Turbo
CometAPI — enkel API-adgang til mange modeller (OpenAI-kompatibel)
CometAPI listefører GLM-5-Turbo som tilgængelig og leverer en OpenAI-kompatibel base-URL og SDK. Brug den modelstreng, de publicerer (deres side listefører GLM-5-Turbo til lignende priser). Eksempler tilpasset fra CometAPI-dokumentation:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
CometAPIs værdi er aggregator-bekvemmelighed (én integration for mange modeller). Bekræft den præcise model-slug i CometAPI-dashboardet, før du kalder.
Best practices ved opbygning af Lobster / OpenClaw-agenter med GLM-5-Turbo
- Design til reliabilitet, ikke rå latenstid: Turbos fordel er lavere fejl i værktøjsopkald i lange kæder. Strukturér agentkørsler til at foretrække robuste afslutninger (retries, idempotente værktøjsopkald) over små førstetoken-gevinster.
- Brug streaming & inkrementelle værktøjsopkald: Udnyt streaming/opdelte output for at reducere rework og muliggøre tidlig værktøjsinvokering hvor det er passende. GLM-5-Turbo understøtter streaming.
- Strukturerede outputs til parser: Foretræk JSON eller velformaterede resultater for deterministisk nedstrøms værktøjsparsing. Turbo understøtter strukturerede outputs.
- Planlæg for planlægning / vedvarende kørsel: Hvis din agent periodisk skal tjekke eller køre baggrundsopgaver, brug Turbos bedre tidssemantik og cachingfunktioner for at undgå ny-planlægning hver cyklus.
- Instrumentér værktøjsopkald & fallbacks: Log værktøjsopkald og design graciøse fallbacks (f.eks. re-try med let temperatur eller kald et backup-værktøj), da agent-baserede arbejdsflows er skrøbelige, hvis en enkelt ekstern API fejler. Turbo reducerer fejlraterne, men eliminerer ikke eksterne fejl
Udviklere kan få adgang til GLM-5- og GLM-5 turbo-API via CometAPI nu. For at komme i gang, konsulter API-guiden for detaljerede instruktioner. Inden adgang, sørg for at du er logget ind på CometAPI og har fået API-nøglen. CometAPI tilbyder en pris langt under den officielle for at hjælpe dig med integrationen.
Klar til at gå i gang?→ Tilmeld dig GLM-5 og GLM-5 turbo i dag !