
.png&w=3840&q=75)
GPT-5.4 Mini og GPT-5.4 Nano er OpenAIs nye kompakte varianter af GPT-5.4 frontier-familien: Mini sigter mod en førsteklasses balance mellem ydeevne og latenstid til kodning, multimodale UI-opgaver og subagent-arbejdsbelastninger; Nano sigter mod ultralav pris og latenstid til klassificering, ekstraktion, ranking og massivt parallelle subagenter. Mini tilbyder næsten-frontier-nøjagtighed på mange udvikler-benchmarks, samtidig med at den kører >2× hurtigere end tidligere mini-modeller; Nano er markant billigere pr. token og ideel, hvor throughput og responsivitet betyder mest. Disse modeller er live i API’et (GPT 5.4 Mini og Nano er tilgængelige i CometAPI).
Hvad er GPT-5.4 Mini og GPT-5.4 Nano?
Kort definition: GPT-5.4 Mini og GPT-5.4 Nano er kompakte, ingeniørtilpassede varianter af GPT-5.4-familien, designet til at bringe kernekvaliteterne fra den store GPT-5.4 (resonnering, kodning, multimodal perception, værktøjsbrug) ind i hurtigere, billigere modeller målrettet højvolumen- og lav-latens-arbejdsbelastninger. Modellerne blev annonceret af OpenAI som en del af GPT-5.4-udrulningen.
- GPT-5.4 Mini — En performant lille model, der “nærmer sig ydeevnen for GPT-5.4 på flere evalueringer”, samtidig med at den er optimeret til hastighed og lavere omkostninger. Den fremhæves specifikt til kodning, resonnering, multimodal UI-fortolkning (skærmbilleder) og som subagent i agentiske systemer. OpenAI rapporterer, at den kører mere end 2× hurtigere end tidligere “mini”-varianter.
- GPT-5.4 Nano — Den mindste, billigste GPT-5.4-variant; anbefales til klassificering, ekstraktion, ranking og “understøttende” subagenter, der håndterer snævre, repetitive opgaver med meget høj gennemløb. Den bytter dybere resonnering for lavere latenstid og omkostninger.
Tilgængelighed og pris
OpenAI giver to konkrete datapunkter, du kan bruge til at sammenligne omkostninger:
- GPT-5.4 (fuldt flagskib) API-inddata-pris: $2.50 / 1M tokens (og højere uddata-prissætning på flagskibet).
- GPT-5.4 mini API-inddata-pris: $0.75 / 1M tokens og uddata $4.50 / 1M tokens.
- GPT-5.4 nano API-inddata-pris: $0.20 / 1M og uddata $1.25 / 1M.
Sat side om side: minis inddata-tokenpris (0.75) er 30% af flagskibets (2.50), altså cirka en tredjedel af inddataomkostningen; minis uddata-pris (4.50) er omkring 32% af en flagskibs-uddatapris angivet i API-pristabellen, dvs. også omtrent en tredjedel. Nano er endnu billigere: dens indomkostning er omkring 8% af flagskibets, og dens udomkostning er under 10% af flagskibets. Disse proportioner er netop grunden til, at OpenAI omtaler mini/nano som “cirka en tredjedel” (mini) og “en brøkdel af” (nano) omkostningen ved at bruge de største modeller til højvolumen-opgaver. Prisen på nano-tokenet steg fra $0.05 til $0.20, og prisen på mini-tokenet steg fra $0.25 til $0.75 (for inddata-tokens).
På OpenAI-platformen
GPT-5.4 mini er tilgængelig tre steder: OpenAI API, Codex (OpenAIs udvikler-IDE/app-platform) og ChatGPT (tilgængelig for Free- og Go-brugere via “Thinking”-valgmuligheden og som rate-limit-fallback for betalte niveauer). I API’et understøtter den tekst- og billedinddata, værktøjsbrug (funktionskald), web-/filsøgning, computerbrug og skills — og den tilbyder et meget stort kontekstvindue (400k tokens) til dokumenttunge og multi-skærmbillede-workflows. Prissætning for API’et er $0.75 per 1M inddata-tokens og $4.50 per 1M uddata-tokens.
GPT-5.4 nano er kun tilgængelig via API’et. Dens listepriser er $0.20 per 1M inddata-tokens og $1.25 per 1M uddata-tokens — hvilket positionerer den som den lavest prissatte indgang i GPT-5.4-familien. Nano-modellen bytter bevidst kapabilitet for pris og hastighed.
På tredjepartsplatform
CometAPI er en multimodal aggregeringsplatform for AI-API’er, som nu har lanceret GPT 5.4 Series API, inklusive GPT 5.4 Mini og GPT 5.4 Nano, til 20% under OpenAI-prisen.
GPT 5.4 Nano:
| Comet-pris (USD / M tokens) | Officiel pris (USD / M tokens) |
|---|---|
| Inddata:$0.16/M; Uddata:$1/M | Inddata:$0.2/M; Uddata:$1.25/M |
GPT 5.4 Nano:
| Comet-pris (USD / M tokens) | Officiel pris (USD / M tokens) |
|---|---|
| Inddata:$0.6/M; Uddata:$3.6/M | Inddata:$0.75/M; Uddata:$4.5/M |
Nøglefunktioner og hvad er nyt
Nedenfor er hovedkapabiliteterne — hvorfor ingeniører og produktteams vil være interesserede.
Indkodning og understøttelse af lange kontekster
Kontekstvindue: GPT-5.4 mini understøtter et kontekstvindue på 400k tokens (OpenAI angiver eksplicit mini med 400k kontekst). Dette er stort nok til kodebaser med flere filer, lange dokumenter eller multi-turs agentsessioner, hvor kontekst betyder noget. Nanos kontekst er mindre relativt til den fulde GPT-5.4, men stadig betydelig til hurtige korte opgaver.
Resonnering
Resonneringsniveauer: OpenAI eksponerer konfigurerbar reasoning_effort (none → xhigh); mini og nano kan køre med varierende indsats, men mini lukker hullet til den fulde GPT-5.4 på mange resonnerings-benchmarks ved højere indsats. På flere intelligens-benchmarks (fx GPQA Diamond) opnår mini 88.0% mod 93.0% for GPT-5.4, og nano leverer 82.8%, hvilket indikerer respektabel resonnering for en lille model. Dette er resultater, som OpenAI offentliggjorde i deres launch-post.
Multimodal forståelse (vision og UI)
Visuel perception og UI-opgaver: GPT-5.4 mini viser meget stærk multimodal ydeevne til UI-opgaver (skærmbilleder, tætte dokumentbilleder). På OSWorld-Verified (en computerbrugs-benchmark) scorer mini 72.1%, meget tættere på GPT-5.4’s 75.0% og langt over tidligere mini-modeller — dette er grunden til, at mini positioneres til skærmbillede-drevne automatiseringer og responsive multimodale assistenter. Nano præsterer lavere på visuelle benchmarks, men er stadig nyttig til enklere billedopgaver.
Værktøjskald og computerbrug
Indbyggede værktøjs-/klikfunktioner: GPT-5.4 introducerer og udvider indbygget computerbrugs-værktøj; mini arver evnen til at kalde værktøjer, foretage funktionskald, fortolke skærmbilleder og orkestrere subagenter. Værktøjskalds-benchmarks (Toolathlon, MCP Atlas) viser, at mini og nano scorer respektabelt (Toolathlon: mini 42.9%, nano 35.5%) — dette kvantificerer deres evne til at kalde og koordinere eksterne værktøjer. Disse målinger stammer fra OpenAIs annoncering.
Hallucination/faktualitet/fejlrater
OpenAI rapporterer, at GPT-5.4 er den “mest faktuelle model til dato” og viser reduktioner i hallucinationer vs GPT-5.2; mini og nano viser lavere absolut faktualitet end den fulde model (fx HLE m/ værktøjer: GPT-5.4 52.1%, mini 41.5%, nano 37.7%), hvilket antyder et øget behov for verifikation, når mindre modeller bruges i høj-fakt-opgaver. Brug værktøjsbaseret verifikation (værktøjskald, kildecitation) når korrekthed er vigtig.
Hastighed
OpenAI rapporterer, at GPT-5.4 mini kører mere end 2× hurtigere end den tidligere GPT-5 mini på typiske produktions-latenser (disse er baseret på simuleret produktionsadfærd, der inkluderer varigheder for værktøjskald og samplede tokens). Denne hastighedsforøgelse er et centralt krav for den nye familie og er det, der gør det muligt at bruge mini som en responsiv subagent i interaktive apps som kodeassistenter.
Hvordan klarer mini og nano sig — “nærmer” de sig den fulde GPT-5.4?
OpenAI offentliggjorde et omfattende sæt benchmark-sammenligninger på tværs af kodning, værktøjsbrug, multimodal computerbrug, intelligens-tests og langkontekst-evalueringer. Hovedtallene (xhigh resonneringsindsats hvor relevant) inkluderer:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (gammel) | Noter |
|---|---|---|---|---|---|
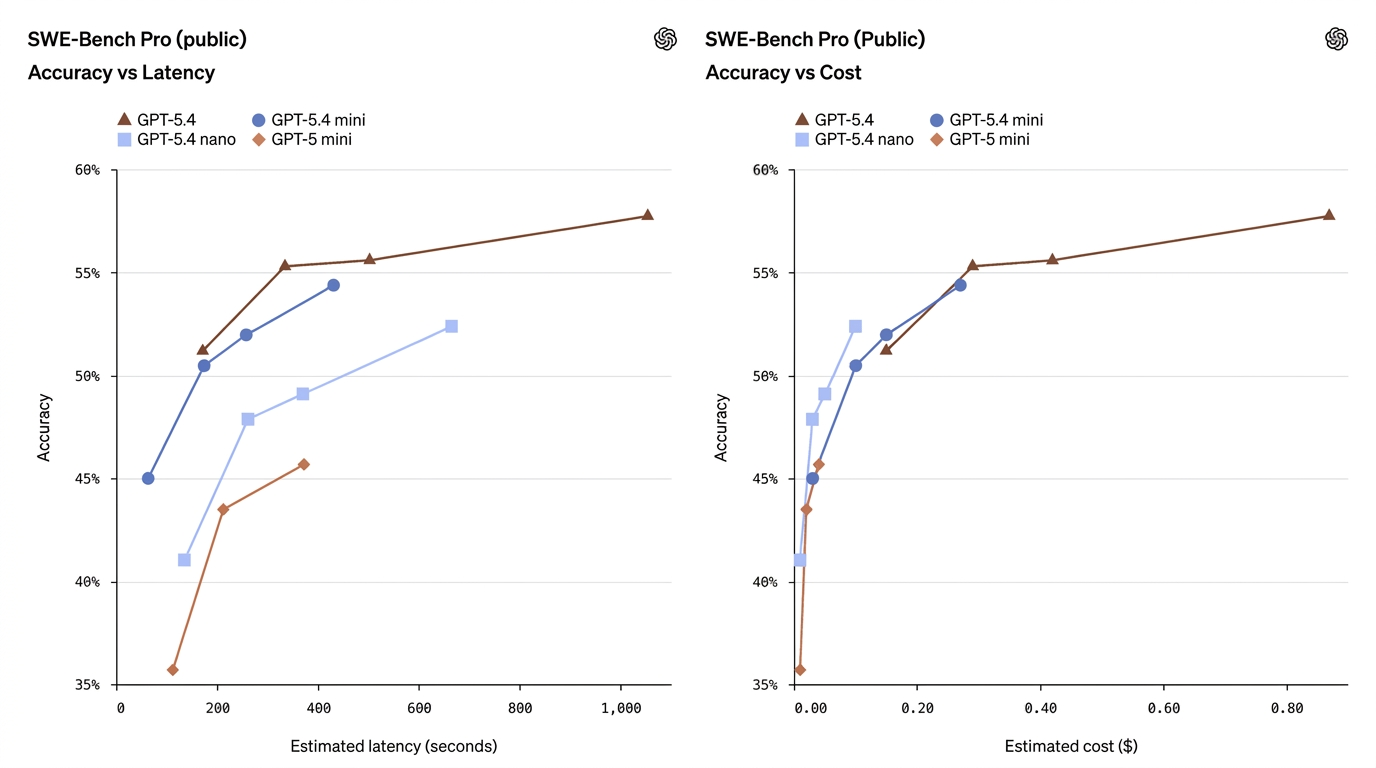
| SWE-Bench Pro (Coding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini nærmer sig den fulde models kodeydelse |
| Terminal-Bench 2.0 (Interactive Coding) | 75.1% | 60.0% | 46.3% | — | Stærk realtids-kodeevne for Mini |
| Toolathlon (Tool Use) | 54.6% | 42.9% | 35.5% | — | Måler orkestrering og værktøjskald |
| GPQA Diamond (Advanced QA) | 93.0% | 88.0% | 82.8% | — | Intelligens- og resonnerings-benchmark |
| OSWorld-Verified (GUI Tasks) | 75.0% | 72.1% | 39.0% | 42.0% | UI-/computerbrugs-kapabilitet |
Disse tal viser, at mini ofte indsnævrer hullet betydeligt — især på kodning og computerbrugs-opgaver — mens nano indtager en nyttig middelvej mellem kapabilitet og omkostning.
Hvad betyder tallene i klare vendinger?
- GPT-5.4 Mini ≈ “næsten flagskib” på mange produktionstasks. På SWE-Bench Pro (et kode-pass-rate-mål) scorer mini 54.4% vs flagskibets 57.7% — et lille relativt hul for mange virkelige kodeopgaver, særligt når latenstid betyder noget. På OSWorld (computerbrug) er mini 72.1% mod flagskibets 75.0% — igen meget tæt for UI-/skærmbillede-opgaver.
- GPT-5.4 Nano bytter mere kapabilitet for hastighed/omkostning. Nanos kodescore (52.4% på SWE-Bench Pro) er respektabel i forhold til ældre mini-modeller, men dens OSWorld-score falder til 39.0%, hvilket viser, at til opgaver, der kræver kompleks multistep UI-forståelse eller agentiske værktøjssekvenser, er nano mindre egnet. Nano skinner ved single-turn klassificering, ekstraktion og små hjælperopgaver.
- Værktøjsbrug forbedres, men er fortsat sensitiv. Toolathlon og andre værktøjsbrugs-målinger stiger markant ved skift fra GPT-5 mini til GPT-5.4 mini/nano, hvilket viser, at OpenAIs engineering har forbedret pålideligheden af værktøjskald i de mindre modeller — men den fulde model fører stadig i kompleks orkestrering.
Sådan fungerer de i produktion
Komprimering, destillation og ingeniøroptimeringer
Kompakte modeller som mini/nano bruger typisk en kombination af modeldestillation, kvantisering og arkitektonisk pruning til at bevare højværdikapabiliteter (kodeheuristikker, visuelle percepter), samtidig med at inferenscompute reduceres. OpenAIs formulering indikerer fokuseret engineering for at bevare specifikke færdigheder (kodning, multimodal UI-forståelse) i de mindre footprints.
Anbefalede mønstre
- Orkestrator + subagent-mønster: Brug GPT-5.4 (stor) som planner/judge og uddeleger arbejde til GPT-5.4 mini / nano subagenter til hurtig eksekvering (søg, parse, rediger). Dette reducerer de samlede omkostninger og sænker latenstiden for brugeren. OpenAI støtter eksplicit dette designmønster.
- Fallback og rate-limit-håndtering: Eksponér mini som en rate-limit-fallback i ChatGPT eller Codex, så tidskritiske forespørgsler stadig får et kapabelt svar, når den fulde model ikke er tilgængelig.
- Lagopdelt arkitektur til omkostningskontrol: Masse-pipelines (indeksering, ekstraktion) → GPT-5.4 nano; interaktive UI-komponenter → GPT-5.4 mini; endelig redaktionel vurdering/komplekse kæder → GPT-5.4 fuld. Denne multi-lags-tilgang balancerer omkostning og kapabilitet.
Latenstid og parallelisering
Mini og nano er optimeret til parallelle subagenter, hvor mange små workers kører samtidigt — fx scanning af tusindvis af PDF’er parallelt. OpenAIs “tool yields”-koncept måler, hvordan parallelle værktøjskald reducerer wall-clock-latenstid; mini/nano er ingeniørmæssigt designet til at gøre disse mønstre omkostningseffektive.
Hvordan ville jeg bruge mini og nano i praksis
Skal jeg erstatte mine flagskibs-kald med mini/nano overalt?
Ikke automatisk. Det rigtige mønster, som OpenAI eksplicit anbefaler, er delegering: brug en større model til planlægning, kompleks dom eller endelig verifikation, og uddeleger mange understøttende, kortere delopgaver til mini- eller nano-subagenter. Dette mønster reducerer omkostninger og latenstid, samtidig med at den større models beskyttelsesrækværk bevares, hvor det er vigtigst. Anvendelseseksempler:
- Interaktive kodeassistenter: flagskib planlægger og reviewer; mini håndterer hurtig kodesøgning, redigeringer og korte enhedstests.
- Skærmbillede-drevne “computerbrugs”-agenter: mini kan hurtigt parse tætte grænseflader; flagskibet løser tvetydig flertrinsplanlægning.
- Højvolumen-udtræks- og klassificeringspipelines: nano behandler massive batch-inddata (formularer, logs) og returnerer strukturerede resultater; flagskibet håndterer undtagelser og komplekse edge cases.
Kan mini eller nano bruges til multimodale eller billedopgaver?
Ja — mini understøtter billedinddata og præsterer godt på multimodale/visionsdrevne benchmarks (MMMUPro/OmniDocBench), og nærmer sig flagskibet på nogle tests. Nanos multimodale styrke er mere begrænset: selv om den forbedrer sig i forhold til tidligere nanos, er den ikke det bedste valg til dyb multimodal resonnering eller agentiske billedbaserede opgaver.
Kapløbet om små modelkapaciteter er intensiveret
For tre måneder siden blev små modeller betragtet som “gode nok”. Nu nærmer GPT-5.4 mini sig flagskibsmodeller på programmerings-benchmarks og matcher dem næsten i beregningsmæssig ydeevne.
Tendensen bag dette er klar: kapabiliteterne fra flagskibsmodeller overføres hurtigt til mindre modeller. OpenAI, Google og Anthropic gør alle det samme: destillerer de store modellers kernekapabiliteter ned i mindre, hurtigere og billigere versioner.
Konklusion
Udgivelsen af disse to modeller markerer et skifte i AI-applikationer fra fokus på skala til fokus på praktisk effektivitet. Gennem hurtig respons giver de mere pålidelig understøttelse af realtids-AI-interaktion og nedbrydning af komplekse opgaveforløb.
For udviklere betyder dette, at omkostningsstrukturen for agentsystemer bliver redefineret. Når omkostningerne falder til dette niveau, bliver mange agentscenarier, der tidligere var “teoretisk mulige men økonomisk urealistiske”, gennemførlige.
Udviklere kan få adgang til GPT 5.4 Mini og GPT-5.4 Nano via CometAPI (CometAPI er en one-stop aggregeringsplatform for store model-API’er såsom GPT-API’er, Nano Banana-API’er m.fl.) nu. Før adgang skal du sikre, at du er logget ind på CometAPI og har fået API-nøglen. CometAPI tilbyder en pris langt under den officielle pris for at hjælpe dig med at integrere.
Klar til at gå i gang?