

xAI stille og roligt udgivet Grok 4.1 (17.-18. november 2025) — en fokuseret opgradering til Grok 4, der prioriterer følelsesmæssig intelligens, kreativ udtryk og reduceret hallucination samtidig med at den knivskarpe argumentation fra tidligere Grok-udgivelser bevares. Den kommer i to tilstande (Tænkning / Ikke-Tænkning), blev stille og roligt rullet ud i starten af november, viser topresultater på LMArena og er tilgængelig via grok.com, Grok-appsene og API'en.
Hvad er Grok 4.1?
Grok 4.1 er den trinvise, produktionsfokuserede efterfølger til Grok 4: et familiemedlem bygget på det samme fundament for storstilet forstærkningslæring, men finjusteret og omtrænet med omfattende optimeringer efter træning rettet mod stil, personlighed, tilpasning og pålidelighed i den virkelige verden. Den positioneres som et pragmatisk, "brugbart" skridt fremad: klogere i blinde menneskelige præferencetests, mere følelsesmæssigt intelligent, bedre til kreativ skrivning og målbart mindre tilbøjelig til den slags selvsikre, men forkerte "hallucinationer", der har plaget tidligere højtydende LLM'er.
Grok 4.1 opnår kvalitative ændringer i følgende fire dimensioner:
- Kreativitet: Demonstrerer stærkere sproglig stil og fantasi i skrivning, historiefortælling og sociale sammenhænge;
- Følelsesmæssig intelligens: Genkender tonefald og følelsesmæssige ændringer, reagerer med mere menneskelig følelsesmæssig logik og genererer trøstende og forstående reaktioner;
- Personlighedssammenhæng: Opretholder ensartet tone og personlighed i lange samtaler og udviser ikke længere den inkonsekvente adfærd fra tidligere modeller;
- Samarbejdsorienteret: Opretholder sammenhæng og målbevidsthed i dialoger med flere punkter eller samarbejde om opgaver.
xAI opsummerer sine karakteristika i én sætning: "Det er mere opfattende, mere empatisk og mere som en sammenhængende person."
Hvordan fungerer Grok 4.1 under motorhjelmen?
Grok 4.1 forstås bedst som den samme prætrænede rygrad, der bruges på tværs af Grok 4-familien plus en lagdelt eftertræningspipeline, der fokuserer på belønningsmodellering, stiljustering og agentevaluatorer.
Hvad er trænings- og tilpasningsfaserne?
Grok 4.1 fungerer på en flertrins pipeline, typisk for moderne frontier LLM'er, tilpasset med to vigtige ændringer i 4.1:
- Før træning + midt i træning: Stort forberedende træningsgrundlag i webdata + målrettet midtvejstræning for at styrke domæneviden og multimodale evner.
- Overvåget finjustering (SFT): Menneskelige demonstrationer af ønsket adfærd (svar, afvisningsstrategier).
- Belønningsmodellering (ny anvendelse): xAI-trænede belønningsmodeller ikke kun på menneskelige præferencemærker, men også brugt Frontier Agent Ræsonnement-modeller som belønningsbedømmere – hvilket effektivt giver dygtige, modelbaserede evaluatorer mulighed for at bedømme kandidatoutput i stor skala. Dette muliggjorde optimering af ikke-verificerbare attributter som f.eks. stil, personlig samhørighed, empati og hjælpsomhed uden at kræve et umuligt stort budget til menneskelig mærkning.
- Politikoptimering (RLHF / RL fra modelbelønninger): Standardpolitikoptimering ved hjælp af de lærte belønningssignaler til at producere den implementerede politik (den model, forbrugerne interagerer med).
Hvad er nyt i belønningsmodelleringsmetoden?
I traditionel RLHF indsamler man menneskelige præferencemærkater (A/B), træner en belønningsmodel til at forudsige disse mærker og optimerer derefter basismodellen med RL (eller afvisningssampling) i forhold til den lærte belønning. Men to praktiske innovationer, som xAI fremhæver:
- Agentiske belønningsmodeller: I stedet for rent menneskelige dommere brugte xAI dygtige "agentiske" ræsonnementsmodeller som bedømmere til at evaluere mere subtile egenskaber (tone, følelsesmæssig nuance, kreativitet). Bedømmerne kan køre tusindvis af parvise sammenligninger hurtigt, hvilket giver ingeniører mulighed for at iterere hurtigere. Dette er mekanismen for store forbedringer i stil og følelsesmæssig intelligens.
- Justering efter træning for ikke-verificerbare signaler: For egenskaber, som man ikke kan måle med en deterministisk metrik (f.eks. "varme" eller "sammenhængende personlighed"), introducerede de specialiserede belønningsmål og skaleringsprogrammer, så modellen lærer stil af output uden at ofre central faktuel nøjagtighed.
Hvordan fungerer "tænkning" vs. "ikke-tænkning" teknisk set?
- Grok 4.1 Thinking (kodenavn
quasarflux) — eksponerer eksplicitte ræsonnementstrin (tænketokens) før det endelige svar produceres; optimeret til komplekse opgaver og højere Elo i LMArena. De ekstra tokens koster inferenstid, men hjælper med flertrinsræsonnementsopgaver, fejlfinding og forklaringsevne. - Grok 4.1 Ikke-tænkende (kodenavn
tensor) omgår eksplicitte mellemliggende tokens for et enkelt, øjeblikkeligt endeligt svar. Dette reducerer latenstid og tokenomkostninger, samtidig med at den drager fordel af de samme raffinerede politikvægte. Den ikke-tænkende tilstand blev optimeret til at have ekstremt lav latenstid og stadig være yderst kapabel.
Optimering af justering af stemning og stil
Ud over simple "sandfærdigheds"-signaler inkluderer Grok 4.1 målrettet optimering af justering af stemning, tone og interpersonel stil. Det betyder, at træningspipelinen inkluderer belønnings- eller tabskomponenter, der eksplicit straffer uoverensstemmende tone (f.eks. at være unødvendig kortfattet, når empati er passende) og belønningsresponser, der matcher en ønsket stil eller stemningsprofil. I Grok 4.1 introducerede AI først optimeringsmålet "Personlighedsjustering".
Det har til formål at hjælpe modellen med at opretholde en konsistent og stabil identitetsfølelse. Sammenlignet med Grok 4 tilføjer 4.1 følgende til træningsmålene:
- Positive belønninger for den følelsesmæssige udtryksdimension (belønning for følelsesmæssig tilpasning);
- En personlighedskohærensmåling.
Hvordan blev Grok 4.1 evalueret – og hvordan klarede den sig?
Hvad viste blinde menneskelige præferencetests?
Under en lydløs udrulning blev Grok 4.1 foretrukket i 64.78 % af tilfældene frem for den tidligere produktionsmodel i livetrafik – et stærkt signal fra mennesker, der indikerer bedre samtaleresultater i praksis.
Topper Grok 4.1 ranglisterne?
xAI rapporterer, at Grok 4.1's Tænker tilstanden sidder ved #1 på LMArenas tekstarena, med en rapporteret Elo på 1483, og dens ikke-ræsonnement (hurtige) tilstand rangerer som nr. 2 med 1465 Elo — stærke offentlige ranglister for både præcision og præsentation (stilkontrol spiller en rolle).
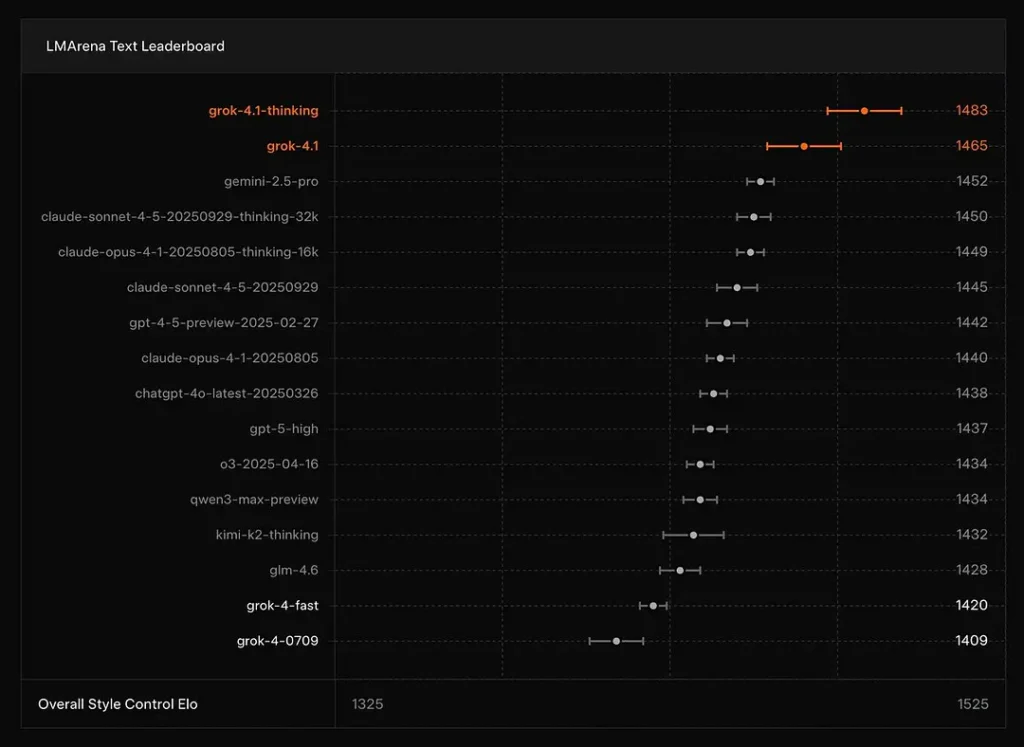
Konklusion: Grok 4.1 overgår de almindelige GPT-4.5- og Claude-seriemodeller i tekstforståelse, generering og generel kvalitet, kun overgået af GPT-5 Advanced Preview-versionen.
Følelsesmæssig intelligens
xAI kørte EQ-Bench3, en specialiseret test for følelsesmæssig intelligens, der dækker 45 udfordrende rollespilsscenarier, og rapporterer, at Grok 4.1 viser stærke forbedringer i empati, tempo og interpersonel indsigt. Grok 4.1 scorede højest i forståelse af sammenhænge med tristhed, empati og komfort.

Kreativ skrivning – er det faktisk mere fantasifuldt?
Grok 4.1 blev evalueret på Kreativ skrivning v3 (32 prompts på tværs af 3 iterationer med rubrik + Elo-scoring). xAI siger, at 4.1's skrivestil, stemmekonsistens og fortællende kreativitet steg betydeligt, hvilket placerede den nær toppen af de seneste ranglister for kreative opgaver (eksempel på prompts er inkluderet i udgivelsen). Uafhængig rapportering afspejlede disse resultater: Anmeldere så markant mere "karakteristisk stemme" og bedre sammenhæng i lange formuleringer. Med hensyn til skrivekvalitet er Grok 4.1 kun overgået af GPT-5-serien og overgår alle produktlinjerne fra Claude, Gemini og Kimi.

Reduceret hallucination / ærlighed
xAI hævder en bemærkelsesværdig reduktion i hallucinationsrater: de rapporterede (i annonceringen og sociale opslag) at Grok 4.1 er ~3 gange mindre tilbøjelige til at hallucinere Sammenlignet med tidligere Grok-modeller, hvor der henvises til produktionstrafikanalyser og evalueringer i FActScore-stil (f.eks. biografi-/biografi-spørgsmål, jo lavere jo bedre). Især i "ikke-ræsonnementstilstanden", hvor eksterne søgeværktøjer er tilgængelige, er faktaenes konsistens mere stabil.

Hvorfor "knuser" Grok 4.1 andre modeller – er det en overdrivelse?
“Crushes” er marketingagtigt, men der er objektive påstande bag påstanden:
- Leaderboards: Grok 4.1 har topplaceringer på offentlige LMArena-ranglister for tekstgenerering (1483 Elo for Thinking-tilstand) og stærke kreative resultater og EQ-bench-resultater pr. xAI's udgivelse. Det er konkurrencemæssige målinger, der bruges på tværs af fællesskabet.
- Præference for reel trafik vinder: xAI rapporterer om sejre i blinde sammenligninger (~65% præference versus den tidligere produktionsmodel) fra en lydløs udrulning på live trafik. Det afspejler forbedringer fra reelle brugere, ikke kun benchmarks på papiret.
- Praktisk ny funktion: Kombinationen af modelbedømmere, RL på ikke-verificerbare signaler og strengere inputfiltre er et pragmatisk ingeniørmæssigt skridt, der direkte forbedrer brugeroplevelsen i samtale-, empatiske og kreative opgaver, hvor konkurrenter historisk set underpræsterer.
Så selvom "crushes" er en farverig måde at sige "leads" på i flere offentlige og interne evalueringer, understøttede de underliggende offentlige målinger, der blev offentliggjort af xAI, denne konklusion.
Sådan får du adgang til Grok 4.1
Forbruger-/appadgang
xAI har med jævne mellemrum gjort Grok 4.1 tilgængelig i "Auto"-tilstand gratis eller som et salgsfremmende vindue, men premium-niveauer (SuperGrok, SuperGrok Heavy) og API-adgang med højere kvoter findes og fortsætter som betalte tilbud.
Grok 4.1 er tilgængelig for alle brugere on grok.com, **X (tidligere Twitter)**og iOS- og Android Grok-appsene, der rulles ud med det samme i automatisk tilstand, mens de også eksplicit kan vælges som "Grok 4.1" i modelvælgeren.
API-adgang og udviklerabonnementer
Grok 4.1-slutpunkter er tilgængelige via xAI API'en. Den officielle GPT 4.1 API er ikke blevet udgivet på udgivelsesdatoen for denne artikel.
CometAPI lover at holde styr på den seneste modeldynamik, herunder Grok 4.1 API, som vil blive udgivet samtidig med den officielle udgivelse. Glæd dig til den og fortsæt med at følge CometAPI. Mens du venter, kan du være opmærksom på Groks andre modeller såsom Grok-kode-hurtig-1 og Grok 4, udforsk deres muligheder i Playground og se API-guiden for detaljerede instruktioner til at kalde . Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen.
Praktiske tips til brug af Grok 4.1 i produktion
Sådan reducerer du risikoen for hallucinationer
- Aktivér livesøgning eller en verificeret værktøjskæde til informationssøgningsforespørgsler.
- Angiv bekræftelsestrinbed modellen om at returnere kilder og beviser for faktuelle påstande; brug
responsemetadata til at inspicere citater (hvis tilgængelige). - Kør deterministiske kontroller (faktatjek af LLM'er, strukturerede datavalidatorer) som et efterbehandlingstrin for output med høj indsats.
Sådan styrer du tone og stil
- Brug eksplicitte systemprompter til at korrigere stemmeføring ("Du er formel og empatisk.").
- Brug overvågede prompter og små lokale skabeloner for at opnå ensartet stemmeføring på tværs af applikationer.
- Udnyt xAI's stilfulde kontrolfunktion og belønningsdrevne ratknapper, hvor det er muligt.
Endelig dom: Er Grok 4.1 en kæmpe forandring?
Grok 4.1 er ikke en helt ny arkitektur; snarere er det en sofistikeret og gennemtænkt efter træning / justering udgivelse der fokuserer på, hvad mennesker rent faktisk er interesserede i i chatten: personlighed, følelsesmæssig intelligens, kreativitet og færre faktuelle fejlMålbare gevinster på ranglister, præferencer for reel trafik i stor skala og forbedrede sikkerhedsværktøjer. For applikationer, der er afhængige af samtaler af høj kvalitet, kreativt samarbejde eller tonefølsom assistance, er Grok 4.1 et stort skridt fremad og i flere community-benchmarks den bedste på udgivelsen.
CometAPI er en kommerciel API-aggregeringsplatform, der giver udviklere samlet, OpenAI-lignende REST-adgang til hundredvis af AI-modeller fra flere leverandører – tekst-LLM'er, billed-/videogeneratorer, indlejringer og mere – via en enkelt, ensartet grænseflade. I stedet for at forbinde separate SDK'er eller skræddersyede slutpunkter til OpenAI, Anthropic, Google, Meta eller mindre specialiserede modeludbydere, giver CometAPI dig mulighed for at kalde forskellige modeller ved at ændre modelstrenge og et par parametre.
Klar til at prøve? → Tilmeld dig CometAPI i dag !
Hvis du vil vide flere tips, guider og nyheder om AI, følg os på VK, X og Discord!