
grok-code-fast-1 er xAI’s hastighedsfokuserede, omkostningseffektive agentiske kodemodel, designet til at drive IDE-integrationer og automatiserede kode-agenter. Den lægger vægt på lav latenstid, agentisk adfærd (værktøjskald, trinvise ræsonneringsspor) og en kompakt omkostningsprofil til daglige udviklerarbejdsgange.
Vigtige funktioner (kort fortalt)
- Høj gennemstrømning / lav latenstid: fokuseret på meget hurtig token-output og hurtige completion-svar til IDE-brug.
- Agentisk funktionskald & værktøjer: understøtter funktionskald og orkestrering af eksterne værktøjer (køre tests, linters, filhentning) for at muliggøre flertrins kode-agenter.
- Stort kontekstvindue: designet til at håndtere store kodebaser og kontekster på tværs af flere filer (udbydere lister 256k kontekstvinduer i marketplace-adaptere).
- Synlig ræsonnering / spor: svar kan omfatte trinvise ræsonneringsspor, så agentbeslutninger kan inspiceres og fejlfindes.
Tekniske detaljer
Arkitektur & træning: xAI siger, at grok-code-fast-1 er bygget fra bunden med en ny arkitektur og et prætræningskorpus rigt på programmeringsindhold; modellen modtog derefter efterfølgende kuratering på høj-kvalitets, virkelige pull-request-/kode-datasæt. Denne engineering-pipeline er målrettet mod at gøre modellen praktisk i agentiske arbejdsgange (IDE + værktøjsbrug).
Udrulning & kontekst: grok-code-fast-1 og typiske brugsmønstre forudsætter streamede outputs, funktionskald og rig kontekst-injektion (filuploads/-samlinger). Flere cloud-markedspladser og platformadaptere har allerede opført den med stor kontekststøtte ( 256k kontekster i nogle adaptere).
Brugbarhedsfunktioner: Synlige ræsonneringsspor (modellen synliggør sin planlægning/værktøjsbrug), prompt-engineering-vejledning og eksempelintegrationer samt tidlige lanceringspartner-integrationer (fx GitHub Copilot, Cursor).
Benchmark-ydelse (hvad den scorer på)
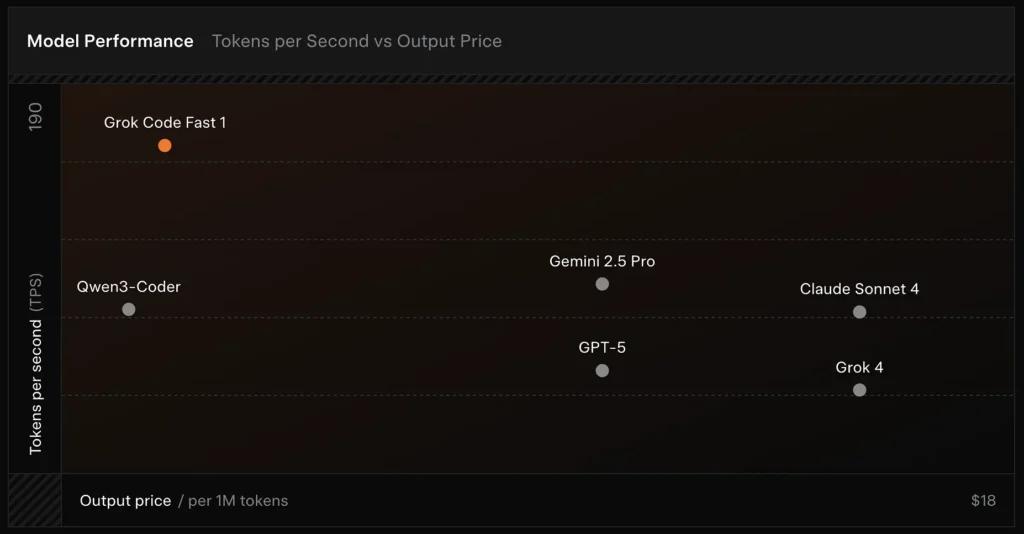
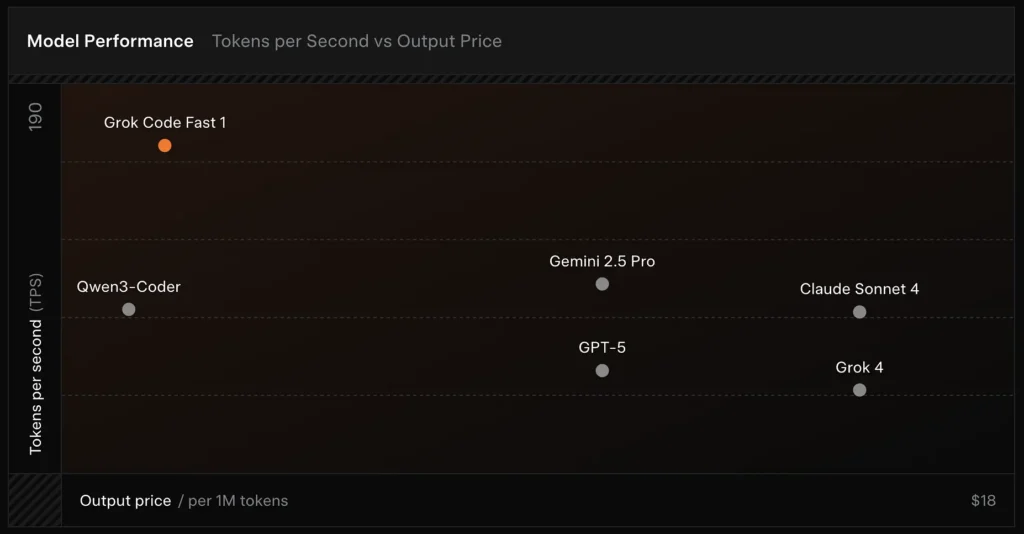
SWE-Bench-Verified: xAI rapporterer en score på 70.8% på deres interne harness over SWE-Bench-Verified-delsættet — en benchmark, der almindeligvis bruges til sammenligning af software-engineeringsmodeller. En nylig hands-on-evaluering rapporterede en gennemsnitlig menneskelig vurdering ≈ 7.6 på en blandet kodningssuite — konkurrencedygtig med nogle højværdi-modeller (fx Gemini 2.5 Pro), men efter de større multimodale/“best-reasoner”-modeller såsom Claude Opus 4 og xAI’s egen Grok 4 på opgaver med høj ræsonneringssværhedsgrad. Benchmarks viser også variation efter opgave: fremragende til almindelige bugfixes og kortfattet kodegenerering, svagere ved nogle niche- eller bibliotekspecifikke problemer (Tailwind CSS-eksempel).
Sammenligning :
- vs Grok 4: Grok-code-fast-1 bytter noget absolut korrekthed og dybere ræsonnering for meget lavere omkostning og hurtigere gennemstrømning; Grok 4 er fortsat løsningen med højere kapacitet.
- vs Claude Opus / GPT-class: Disse modeller ligger ofte i front på komplekse, kreative eller krævende ræsonneringsopgaver; Grok-code-fast-1 konkurrerer godt på højvolumen, rutineprægede udvikleropgaver, hvor latenstid og omkostning betyder noget.
Begrænsninger & risici
Praktiske begrænsninger observeret indtil nu:
- Domænehuller: ydeevnen falder på nichebiblioteker eller usædvanligt formulerede problemer (eksempler omfatter Tailwind CSS edge cases).
- Tradeoff mellem ræsonnerings-tokens og omkostning: fordi modellen kan afgive interne ræsonnerings-tokens, kan meget agentisk/omfangsrig ræsonnering øge inferens-outputlængden (og omkostningen).
- Nøjagtighed / kanttilfælde: selv om den er stærk på rutineopgaver, kan Grok-code-fast-1 hallucinere eller generere forkert kode for nye algoritmer eller adversarielle problemformuleringer; den kan præstere dårligere end topmodeller med fokus på ræsonnering på krævende algoritmiske benchmarks.
Typiske anvendelsesområder
- IDE-assistance & hurtig prototyping: hurtige completions, inkrementelle kodeændringer og interaktiv fejlfinding.
- Automatiserede agenter / kodearbejdsgange: agenter, der orkestrerer tests, kører kommandoer og redigerer filer (fx CI-hjælpere, bot-anmeldere).
- Daglige ingeniøropgaver: generering af kode-skeletter, refaktoreringer, bug-triageforslag og projektstillas på tværs af flere filer, hvor lav latenstid væsentligt forbedrer udviklerflowet.
Sådan kalder du grok-code-fast-1 API fra CometAPI
grok-code-fast-1 API-priser i CometAPI, 20% under den officielle pris:
- Input Tokens: $0.16/ M tokens
- Output Tokens: $2.0/ M tokens
Påkrævede trin
- Log ind på cometapi.com. Hvis du endnu ikke er bruger, så registrer dig først
- Hent adgangslegitimations-API-nøglen til interfacet. Klik på “Add Token” ved API token i det personlige center, få token-nøglen: sk-xxxxx og indsend.
Brugsmetode
- Vælg “
grok-code-fast-1”-endpointet for at sende API-anmodningen og angiv request body. Anmodningsmetode og request body fås fra vores websites API doc. Vores website tilbyder også Apifox-test for din bekvemmelighed. - Erstat <YOUR_API_KEY> med din faktiske CometAPI-nøgle fra din konto.
- Indsæt dit spørgsmål eller din forespørgsel i content-feltet—det er dette, modellen svarer på.
- . Behandl API-svaret for at få det genererede svar.
CometAPI tilbyder en fuldt kompatibel REST API—for problemfri migrering. Nøgleoplysninger i API doc:
- Base URL: https://api.cometapi.com/v1/chat/completions
- Model Names: “
grok-code-fast-1“ - Authentication: Bearer token via
Authorization: Bearer YOUR_CometAPI_API_KEYheader - Content-Type:
application/json.
API-integration & eksempler
Python-snippet til et ChatCompletion-kald via CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Se også Grok 4