

Luma AI’s Uni-1 er mere end en ny tekst-til-billede-model. Med Lumas egne ord er det en “multimodal ræsonneringsmodel, der kan generere pixels”, bygget på “Unified Intelligence”, så den kan forstå intention, reagere på anvisninger og “tænke sammen med dig”. Virksomhedens tekniske rapport siger, at modellen bruger en decoder-only autoregressiv transformer, hvor tekst og billeder repræsenteres i en enkelt interleaved sekvens, og at Uni-1 kan udføre struktureret intern ræsonnering før og under billedsyntese. Det er den kombination, der gør Uni-1 til en af de mest interessante udgivelser inden for billedmodeller i 2026.
Hvad er UNI-1-billedmodellen?
Uni-1 er Luma AI’s nye billedmodel til opgaver, der kræver både forståelse og generering i ét system. Luma præsenterer den som en multimodal ræsonneringsmodel snarere end en klassisk billedmotor, der kun bygger på diffusion, hvilket er vigtigt, fordi modellen er tænkt til mere end blot at producere visuelt tiltalende output: den er designet til at fortolke instruktioner, bevare referencebegrænsninger og ræsonnere sig frem gennem scenelogik som en del af genereringen. Virksomhedens tekniske rapport beskriver Uni-1 som dens første samlede forståelses- og genereringsmodel på vejen mod multimodal generel intelligens.
Hvorfor Uni-1 er anderledes
Den gamle pipeline har et loft: billedgenerering uden forståelse kan kun nå så langt. Uni-1 præsenteres som et skridt mod “unified intelligence”, hvor sprog, perception, fantasi, planlægning og udførelse håndteres i én arkitektur. Det er mere end branding. Uni-1 kan bevæge sig fra visuel lighed mod intentionel komposition, plausibilitet og scenelogik.
Den større historie er, at billedmodeller bliver mere agentiske. Googles nyeste billedstack lægger nu vægt på konversationsbaseret redigering, search grounding, multi-image fusion og karakterkonsistens; OpenAI’s GPT Image-familie lægger vægt på indbygget multimodalitet og instruktionsfølgning. Uni-1 indgår i den udvikling, men læner sig hårdere ind i idéen om, at modellen bør “tænke” over billedet, før den tegner det. Det gør Uni-1 særligt interessant til workflows, hvor præcision og reproducerbarhed betyder lige så meget som visuel flair.
Hvordan fungerer Uni-1 egentlig?
🔬 Tokeniseringsproces
- Tekst → tokensekvens
- Billede → tokeniserede patches
- Kombineret til én enkelt interleaved sekvens
🔁 Genereringsproces
- Inputprompt + referencer
- Modellen udfører intern ræsonnering
- Planlægger kompositionen
- Genererer tokens sekventielt
Matematisk: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Lag for intern ræsonnering
Uni-1:
- Nedbryder instruktioner
- Løser begrænsninger
- Planlægger layout før rendering
👉 Dette er et stort spring i forhold til diffusionsmodeller.
Decoder-only autoregressiv generering
Den vigtigste tekniske detalje er, at Uni-1 er autoregressiv snarere end diffusionsbaseret. Lumas tekniske rapport siger, at det er en decoder-only autoregressiv transformer, og at tekst og billeder kodes i en enkelt interleaved sekvens. På almindeligt dansk betyder det, at modellen ikke blot starter fra støj og gradvist “denoiser” sig frem mod et billede. I stedet genererer den tokens trin for trin, hvilket gør det muligt for modellen at ræsonnere sig gennem prompten, løse begrænsninger og planlægge kompositionen før og under rendering.
🔬 Tokeniseringsproces
- Tekst → tokensekvens
- Billede → tokeniserede patches
- Kombineret til én enkelt interleaved sekvens
Diffusion vs. autoregressiv
| Feature | Diffusionsmodeller | Uni-1 (autoregressiv) |
|---|---|---|
| Generering | Støj → billede | Token for token |
| Ræsonnering | Begrænset | Stærk |
| Redigering | Svag | Multi-turn |
| Tekstrendering | Dårlig | Stærk |
| Kontrol | Lav | Høj |
Kernearkitektur
Uni-1 er:
- Decoder-only autoregressiv transformer
- Delt tokenrum for tekst + billeder
Den arkitektur er vigtig, fordi den giver modellen en chance for at bevare sammenhæng, når prompten er kompliceret. Luma siger, at Uni-1 kan nedbryde instruktioner, løse modstridende begrænsninger og planlægge billedet, før renderingen begynder. Det er især nyttigt til opgaver som struktureret scenefærdiggørelse, placering af flere motiver, multi-turn-forfinelse og redigeringer, hvor outputtet skal forblive tro mod et referencebillede og samtidig adlyde nye instruktioner.
Hvad modellen ser ud til at være designet til at gøre bedre
At lære at generere billeder forbedrer forståelsen. Luma siger, at modellens træning i billedgenerering mærkbart forbedrer den finmaskede visuelle forståelse, især af regioner, objekter og layouts. Derfor er Uni-1 ikke en envejs-generator, men et samlet system, hvor generering og forståelse forstærker hinanden. Ved inferens betyder det, at Uni-1 forsøger at lukke kløften mellem at “se” og at “skabe”. Dette er et stort spring i forhold til diffusionsmodeller.
Genereringsproces:
- Inputprompt + referencer
- Modellen udfører intern ræsonnering
- Planlægger kompositionen
- Genererer tokens sekventielt
Matematisk: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Hvilke funktioner og kernefordele tilbyder Uni-1?
Stærk instruktionsfølgning og styrbarhed
Uni-1’s stærkeste salgsargument er kontrol. modellen er bygget til præcisionsredigering, struktureret brug af referencer og reproducerbare workflows. For skabere betyder det mindre prompt-gætteri og mere reproducerbart output.
En af Uni-1’s praktiske fordele er, at den er bygget til kontrolleret iteration. Seeds gør det muligt for brugere at reproducere resultater, mens referenceroller hjælper modellen med at vide, om et billede skal styre karakteridentitet, stemning, palette eller komposition. Det gør Uni-1 lettere at styre end en model, der udelukkende drives af prompts, især for teams, der producerer annoncer, storyboards, produktmockups eller brandaktiver, hvor konsistens er vigtig.
Referencebaseret generering, der bevarer identitet
En stor fordel er håndteringen af referencer. Luma siger eksplicit, at Uni-1 bruger source-grounded controls og kan bevare identitet, komposition og centrale visuelle begrænsninger fra én eller flere referencer. Det gør den attraktiv til kommercielle workflows som brandkarakterer, produktmockups, kampagneaktiver og ethvert projekt, hvor et motiv skal forblive genkendeligt på tværs af varianter. Dette er en af de tydeligste måder, Uni-1 adskiller sig fra mere rent æstetiske billedsystemer.
Kulturel flydende forståelse og stilbredde
Luma lægger også vægt på kulturbevidst generering. Dets “Cultured”-sektion peger på memes, manga, filmiske looks, afslappede fotos, sport og dyrebilleder og viser, at modellen er tænkt til at fungere på tværs af visuelle sprog snarere end i én generisk stil. Det er vigtigt, fordi en god moderne billedmodel ikke bare skal kunne rendre en realistisk scene; den skal også forstå de visuelle konventioner i internetkultur, redaktionelt design, stiliseret illustration og socialt indhold.
Multimodal tænkning som et designvalg
Den egentlige forskel er ikke kun, at Uni-1 genererer billeder, men at Luma indrammer billedgenerering som en ræsonneringsopgave. Uni-1 kan udføre struktureret intern ræsonnering, og at lære at generere billeder forbedrer finmasket visuel forståelse af regioner, objekter og layouts. Det peger på en model, der er designet til at forstå scenen, før den renderer den, i stedet for blot statistisk at tilnærme prompten.
Performance-benchmarks
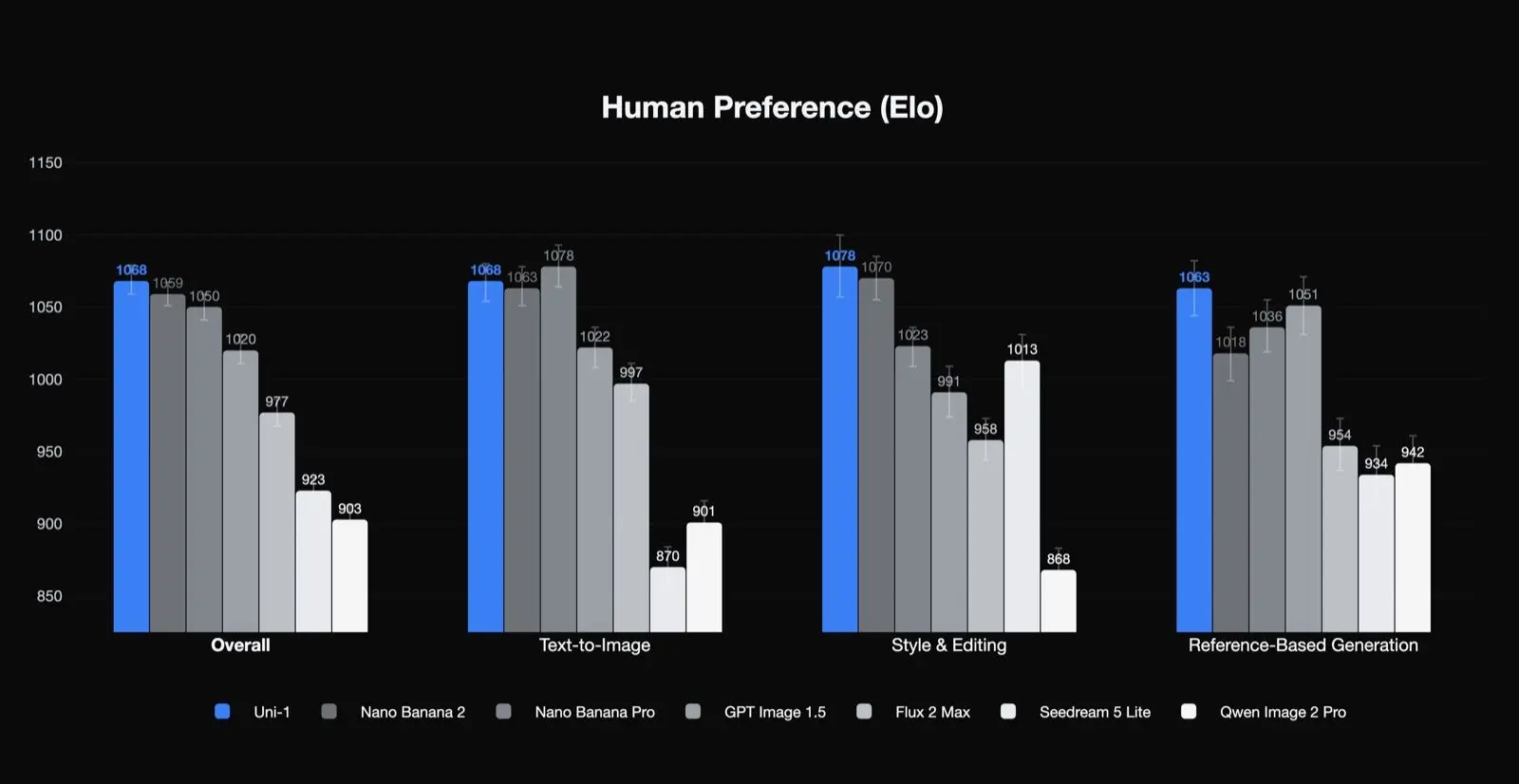
Lumas egne resultater for menneskelige præferencer
Uni-1 rangerer som nummer ét i human-preference Elo for samlet kvalitet, stil og redigering samt referencebaseret generering, og som nummer to i tekst-til-billede. Det er et meningsfuldt resultat, fordi det tyder på, at modellen er særligt stærk til de typer opgaver, som produktionsteams går op i: redigering, konsistens og styret transformation. Det tyder også på, at dens bedste use cases måske ikke kun er almindelig one-shot tekst-til-billede-generering.
RISEBench: ræsonneringsinformeret visuel redigering
Det benchmark, der vækker mest opmærksomhed, er RISEBench, som evaluerer ræsonneringsinformeret visuel redigering på tværs af temporal, kausal, rumlig og logisk ræsonnering. Tredjepartsrapportering om Lumas lancering siger, at Uni-1 scorer 0.51 samlet på RISEBench, foran Googles Nano Banana 2 med 0.50, Nano Banana Pro med 0.49 og OpenAI’s GPT Image 1.5 med 0.46. På rumlig ræsonnering rapporteres Uni-1 til 0.58 mod Nano Banana 2 på 0.47. På logisk ræsonnering rapporteres Uni-1 til 0.32, mere end dobbelt så højt som GPT Image 1.5’s 0.15. Marginerne er ikke enorme samlet set, men de er store i de sværeste ræsonneringskategorier.

ODinW-13 og påstanden om, at “generering forbedrer forståelsen”
Uni-1 klarer sig også stærkt på ODinW-13, et open-vocabulary benchmark for tæt objektgenkendelse. Rapportering om Lumas tekniske data siger, at den fulde model scorer 46.2 mAP, næsten på niveau med Googles Gemini 3 Pro på 46.3. Den samme rapportering siger, at en variant kun til forståelse scorer 43.9 mAP, hvilket antyder, at genereringstræning forbedrer forståelsen med 2.3 point. Det er et bemærkelsesværdigt fund, fordi det understøtter Lumas kernepåstand: billedgenerering og billedforståelse kan være gensidigt forstærkende snarere end konkurrerende mål.
Pris på Uni-1 API
| Inputpris (tekst) | $0.50 |
|---|---|
| Inputpris (billeder) | $1.20 |
| Outputpris (tekst og thinking) | $3.00 |
| Outputpris (billeder) | $45.45 |
På forbrugersiden angiver Lumas prisside Plus til $30/måned, Pro til $90/måned og Ultra til $300/måned, med gratis prøvecredits inkluderet på tværs af abonnementer. Det betyder, at der i praksis er to lag af prissætning at tage højde for: forbrugerabonnementet til platformen og API-prissætningen på modelniveau til produktionsbrug.
Lige nu er CometAPI's Uni-1 API Available Soon, med en lovet rabat ved lancering. CometAPI tilbyder i øjeblikket også fremragende raw image-modeller såsom Midjourney og Nano Banana 2.
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 versus Googles Nano Banana 2
Nano Banana 2 ser stærkere ud, når det gælder bredde i referencehåndtering og økosystemintegration. Google lægger vægt på image search grounding, konversationsbaseret iteration og reference-tunge workflows med op til 14 referencer. Uni-1 er derimod mere eksplicit indrammet omkring ræsonnering, sceneplausibilitet og præcisionsredigering i en samlet modelarkitektur. I praksis ser Google ud til at være optimeret til hastighed, mainstream-produktionsskala og native Google grounding; Luma ser ud til at være optimeret til struktureret visuel ræsonnering og styrbar billedredigering.
I de offentlige sammenligninger omkring Uni-1 er afvejningen tydelig: Nano Banana 2 ser ud til fortsat at være meget stærk til ren tekst-til-billede-kvalitet og hastighed, mens Uni-1 presser hårdere på inden for redigering med tung ræsonnering, referencekontrol og instruktionsfidelitet.
Uni-1 versus OpenAI’s GPT Image
I benchmarkrapportering ligger Uni-1 lidt foran GPT Image 1.5 samlet på RISEBench og mere tydeligt foran på logisk ræsonnering. Sammenlignet med OpenAI’s GPT Image-familie er Uni-1 mere snævert og aggressivt positioneret omkring visuel ræsonnering og kontrolleret redigering. OpenAI’s dokumentation lægger vægt på verdensviden, multimodal forståelse og kontekstuel opmærksomhed; Lumas dokumentation lægger vægt på struktureret intern ræsonnering, referenceforankret kontrol og benchmarket færdighed i visuel redigering. Så selv om begge er multimodale, er Uni-1 den mere åbenlyse “billedspecialiserede ræsonneringsmodel”, mens GPT Image mere fremstår som et generelt multimodalt system, der tilfældigvis genererer billeder ekstremt godt.
Prissammenligning på tværs af de tre
Når det gælder pris, afhænger sammenligningen af outputstørrelse og produkttier, så det er ikke en helt retvisende sammenligning. Uni-1’s offentliggjorte 2048px-ækvivalent er omkring $0.0909 pr. billede. Googles seneste prisside for billedmodeller angiver $0.134 pr. 1K/2K-billede og $0.24 pr. 4K-billede for dets seneste Gemini image preview, mens OpenAI’s GPT Image-prisside angiver outputpriser pr. billede på $0.011 ved lav kvalitet for 1024x1024, $0.042 ved medium kvalitet og $0.167 ved høj kvalitet, med større outputs i høj kvalitet til $0.25. Med andre ord kan OpenAI være meget billigere i den lave ende, Google er aggressiv i hastigheds- og skalaenden, og Uni-1 lander i midten med en stærk pris-ydelsesprofil orienteret mod 2K.
Filosofiske forskelle
| Model | Approach |
|---|---|
| Uni-1 | Samlet multimodal intelligens |
| GPT Image | LLM + billedgenerering |
| Nano Banana 2 | Optimeret produktionsdiffusion |
Detaljeret sammenligningstabel
| Feature | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Arkitektur | Autoregressiv | Hybrid | Diffusion |
| Multimodal samling | ✅ Native | Delvis | ❌ |
| Ræsonneringsevne | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Billedkvalitet | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Tekstrendering | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Redigeringsworkflows | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Hastighed | Medium | Hurtig | Hurtig |
| Kontrol | Høj | Medium | Medium |
CometAPI tilbyder interaktive raw images til GPT Image 1.5, Nano Banana 2 og den kommende Uni-1 samt API-programmering. Rabatpriser og pay-as-you-go-muligheder gør det til et foretrukket valg for udviklere.
Hvad Uni-1 er bedst til
Uni-1 ser særligt stærk ud til tilfælde, hvor du har brug for reproducerbarhed, karakterkonsistens eller kontrol over flere referencer. Det omfatter brandkampagner, produktmockups, redaktionelle koncepter, storyboards, lokaliseringsvarianter og billedredigeringer, hvor kompositionen skal forblive intakt, men stil eller miljø skal ændres. Lumas egne eksempler hælder kraftigt mod disse use cases, og modellens opdeling i “Create vs Modify” er i praksis et direkte svar på almindelige produktionssmertepunkter.
Hvis dit arbejde mest handler om “lav noget flot ud fra en enkelt prompt”, vil forskellen måske føles mindre dramatisk. Men hvis dit workflow er “lav fem relaterede versioner, behold den samme karakter, bevar indramningen, skift lyset, og gør det reproducerbart næste uge”, begynder Uni-1’s design at give rigtig god mening. Det er en slutning, men den følger naturligt af de kontrolfunktioner, Luma fremhæver.
Best practices for at få bedre resultater med Uni-1
Start med at bruge den korrekte tilstand. Lumas vejledning er enkel: Create, når du vil have en ny scene, Modify, når du vil bevare en eksisterende. Hvis de intentioner blandes, bliver outputtene mere ustabile.
Brug referencelabels professionelt. Luma anbefaler formuleringer som “Use IMAGE1 as a STYLE reference” eller “Use IMAGE2 as LIGHTING.” Modellen klarer sig bedre, når hver reference har en opgave, i stedet for vag “inspiration”.
Lås seedet, når du har fundet noget godt. Luma anbefaler eksplicit at udforske uden seed først og derefter gemme seedet, når du har et stærkt resultat. Derefter skal du ændre én variabel ad gangen. Det er den nemmeste måde at gøre generering til et kontrolleret produktionssystem på.
Vær specifik og konkret. Luma advarer mod vage ord som “beautiful” eller “amazing” og opfordrer i stedet til navngivne æstetikker som “1970s Italian giallo film poster” eller præcise kameraagtige signaler. I praksis slår specifikke prompts som regel poetiske prompts, fordi modellen kan forankre sig i reel struktur.
Brug kæden Create → Modify. Luma fremhæver eksplicit dette som et af sine mest kraftfulde workflows: udforsk i Create, og finpuds derefter i Modify. Det er sweet spot for seriøst produktionsarbejde, fordi det reducerer tilbagesporing og bevarer de gode dele af en komposition, mens detaljerne strammes op.
Endelig vurdering
Uni-1 er Lumas hidtil tydeligste udmelding om, at billedgenerering bevæger sig fra “prompt ind, billede ud” mod ræsonneringsstyret visuel skabelse. Dets offentlige styrker er kontrol, referencehåndtering, reproducerbarhed og en modelarkitektur, der holder sprog og pixels i det samme system.
For skabere og teams, der går op i visuelt output med høj klikrate, konsistente karakterer, præcise redigeringer og klarhed i prissætning for høj opløsning, er Uni-1 i høj grad en model, der er værd at holde øje med. Hvis API-udrulningen lander rent, kan den blive et af de mest interessante alternativer til Googles Nano Banana 2 og OpenAI’s GPT Image 1.5 i 2026.
Planlægger du at begynde at skabe raw images? CometAPI, en alt-i-en aggregeringsplatform for multimodale model-API’er, byder dig velkommen!