Gemini 2.5 Flash er konstrueret til at levere hurtige svar uden at gå på kompromis med outputkvaliteten. Den understøtter multimodale input, herunder tekst, billeder, lyd og video, hvilket gør den velegnet til mange forskellige anvendelser. Modellen er tilgængelig via platforme som Google AI Studio og Vertex AI og giver udviklere de nødvendige værktøjer til problemfri integration i forskellige systemer.
Grundlæggende oplysninger (Funktioner)
Gemini 2.5 Flash introducerer flere fremtrædende funktioner, der adskiller den inden for Gemini 2.5-familien:
- Hybrid Reasoning: Udviklere kan angive parameteren thinking_budget for præcist at styre, hvor mange tokens modellen afsætter til intern ræsonnering før output.
- Paretofront: Placeret på det optimale pris-ydelsespunkt tilbyder Flash det bedste pris-til-intelligens-forhold blandt 2.5-modellerne.
- Multimodal understøttelse: Behandler tekst, billeder, video og lyd nativt, hvilket muliggør rigere samtale- og analysefunktioner.
- 1 million-token kontekst: En uovertruffen kontekstlængde muliggør dyb analyse og forståelse af lange dokumenter i én enkelt forespørgsel.
Modelversionering
Gemini 2.5 Flash har gennemgået følgende centrale versioner:
- gemini-2.5-flash-lite-preview-09-2025: Forbedret værktøjsbrugervenlighed: Forbedret ydeevne på komplekse, flertrinsopgaver med en stigning på 5% i SWE-Bench Verified-scorer (fra 48.9% til 54%). Forbedret effektivitet: Ved aktivering af ræsonnering opnås output af højere kvalitet med færre tokens, hvilket reducerer latens og omkostninger.
- Preview 04-17: Tidlig adgangsudgivelse med “thinking”-kapabilitet, tilgængelig via gemini-2.5-flash-preview-04-17.
- Stable General Availability (GA): Fra den 17. juni 2025 erstatter det stabile endpoint gemini-2.5-flash previewet og sikrer produktionsklar pålidelighed uden API-ændringer i forhold til previewet fra 20. maj.
- Udfasning af Preview: Preview-endpoints var planlagt til lukning den 15. juli 2025; brugere skal migrere til GA-endpointet før denne dato.
Fra juli 2025 er Gemini 2.5 Flash nu offentligt tilgængelig og stabil (ingen ændringer i forhold til gemini-2.5-flash-preview-05-20 ).Hvis du bruger gemini-2.5-flash-preview-04-17, fortsætter den eksisterende preview-prisfastsættelse indtil den planlagte udfasning af model-endpointet den 15. juli 2025, hvor det lukkes. Du kan migrere til den generelt tilgængelige model "gemini-2.5-flash" .
Hurtigere, billigere, smartere:
- Designmål: lav latens + høj gennemløb + lave omkostninger;
- Generel hastighedsforøgelse i ræsonnering, multimodal behandling og opgaver med lange tekster;
- Tokenforbruget reduceres med 20–30%, hvilket markant reducerer ræsonneringsomkostningerne.
Tekniske specifikationer
Inputkontekstvindue: Op til 1 million tokens, hvilket muliggør omfattende kontekstbevarelse.
Output-tokens: Kan generere op til 8,192 tokens pr. svar.
Understøttede modaliteter: Tekst, billeder, lyd og video.
Integrationsplatforme: Tilgængelig via Google AI Studio og Vertex AI.
Priser: Konkurrencedygtig token-baseret prismodel, der muliggør omkostningseffektiv udrulning.
Tekniske detaljer
Under motorhjelmen er Gemini 2.5 Flash en transformer-baseret stor sprogmodel, trænet på en blanding af web-, kode-, billed- og videodata. Centrale tekniske specifikationer omfatter:
Multimodal træning: Trænet til at afstemme flere modaliteter kan Flash problemfrit blande tekst med billeder, video eller lyd, nyttigt til opgaver som videosammenfatning eller lydtekster.
Dynamisk tænkningsproces: Implementerer en intern ræsonneringssløjfe, hvor modellen planlægger og nedbryder komplekse prompts før det endelige output.
Konfigurerbare tænkningsbudgetter: thinking_budget kan sættes fra 0 (ingen ræsonnering) op til 24,576 tokens, hvilket muliggør afvejninger mellem latens og svarkvalitet.
Værktøjsintegration: Understøtter Grounding with Google Search, Code Execution, URL Context og Function Calling, hvilket muliggør virkelige handlinger direkte fra naturlige sprogprompter.
Benchmark-ydeevne
I strenge evalueringer demonstrerer Gemini 2.5 Flash branchens førende ydeevne:
- LMArena Hard Prompts: Opnåede kun næst efter 2.5 Pro på den udfordrende Hard Prompts-benchmark, hvilket viser stærke evner til flertrinsræsonnering.
- MMLU-score på 0.809: Overgår gennemsnitlig modelydeevne med en 0.809 MMLU-nøjagtighed, hvilket afspejler dens brede domæneviden og ræsonneringsevner.
- Latens og gennemløb: Opnår 271.4 tokens/sec afkodningshastighed med 0.29 s Time-to-First-Token, hvilket gør den ideel til latensfølsomme arbejdsbelastninger.
- Pris-til-ydeevne-leder: Ved $0.26/1 M tokens underbyder Flash mange konkurrenter, samtidig med at den matcher eller overgår dem på centrale benchmarks.
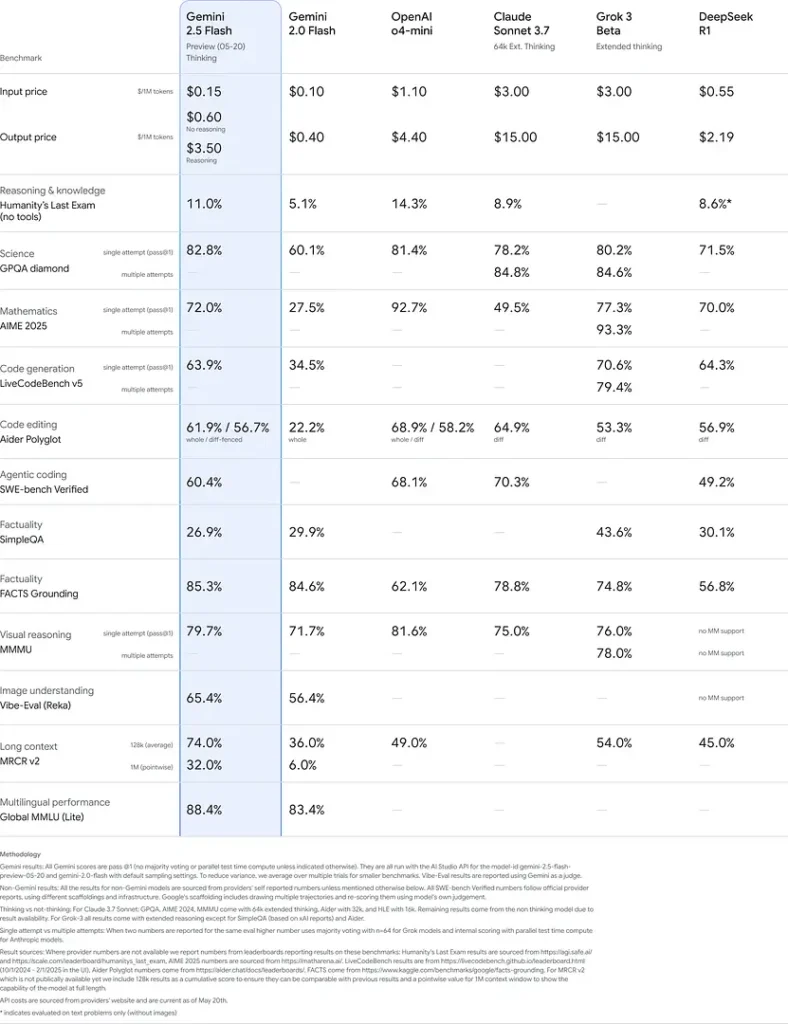
Disse resultater indikerer Gemini 2.5 Flashs konkurrencefordel inden for ræsonnering, videnskabelig forståelse, matematisk problemløsning, kodning, visuel fortolkning og flersprogede kapaciteter:
Begrænsninger
Selvom den er kraftfuld, har Gemini 2.5 Flash visse begrænsninger:
- Sikkerhedsrisici: Modellen kan udvise en “formanende” tone og kan producere plausibelt lydende, men forkerte eller partiske outputs (hallucinationer), især ved edge case-forespørgsler. Grundig menneskelig kontrol er fortsat essentiel.
- Grænser for forespørgsler: API-brug er begrænset af rate limits (10 RPM, 250,000 TPM, 250 RPD på standardniveauer), hvilket kan påvirke batch-behandling eller applikationer med høj volumen.
- Nedre intelligensgrænse: Selvom den er usædvanligt kapabel for en flash-model, er den mindre præcis end 2.5 Pro i de mest krævende agentiske opgaver som avanceret kodning eller multi-agent-koordinering.
- Omkostningsafvejninger: Selvom den tilbyder den bedste pris-ydelse, øger omfattende brug af thinking-tilstanden det samlede tokenforbrug og hæver omkostningerne for prompter, der kræver dyb ræsonnering .