Tekniske detaljer
- Adaptiv ræsonnering:
Gemini 2.5 Flash-Liteunderstøtter tænkning efter behov, så udviklere kun allokerer beregningsressourcer, når dybere ræsonnering er påkrævet. - Integration med værktøjer: Fuld kompatibilitet med Gemini 2.5's native værktøjer, inklusive Grounding with Google Search, Code Execution, URL Context og Function Calling til sømløse multimodale arbejdsgange.
- Model Context Protocol (MCP): Udnytter Googles MCP til at hente webdata i realtid og sikrer, at svar er opdaterede og kontekstuelt relevante.
- Implementeringsmuligheder: Tilgængelig via CometAPI, Gemini API, Vertex AI og Google AI Studio, med en preview-kanal for tidlige brugere til at eksperimentere og give feedback.
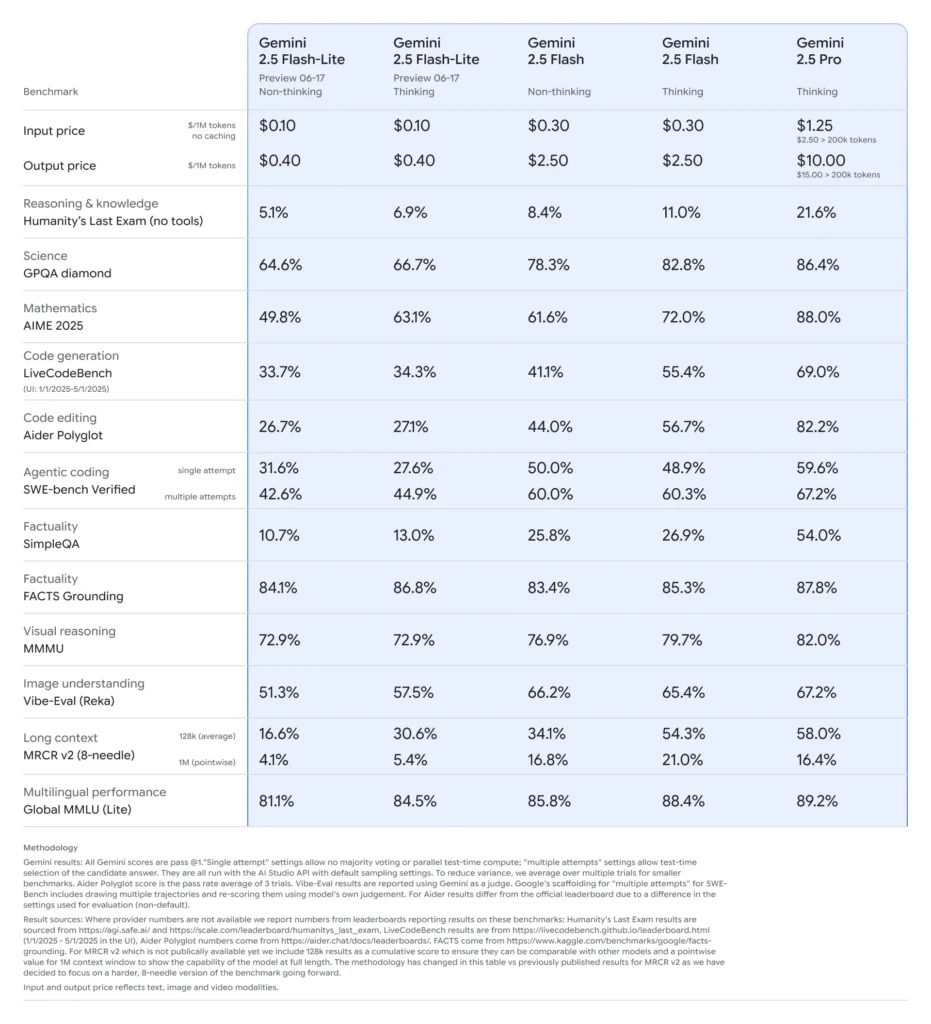
Benchmark-ydeevne for Gemini 2.5 Flash-Lite
- Latens: Opnår op til 50 % lavere medianresponstider sammenlignet med Gemini 2.5 Flash, med typisk latens under 100 ms på standardklassifikations- og opsummeringsbenchmarks.
- Gennemløb: Optimeret til højvolumen-arbejdsbelastninger og kan opretholde titusindvis af forespørgsler pr. minut uden forringelse af ydeevnen.
- Pris-ydelse: Viser en 25 % reduktion i omkostning pr. 1,000 tokens sammenlignet med Flash-varianten, hvilket gør den til et pareto-optimalt valg for omkostningsfølsomme implementeringer.
- Brancheadoption: Tidlige brugere rapporterer problemfri integration i produktionspipelines, med ydeevnemålinger der matcher eller overgår de oprindelige fremskrivninger.
Ideelle anvendelsestilfælde
- Højfrekvente opgaver med lav kompleksitet: Automatiseret tagging, sentimentanalyse og masseoversættelse
- Omkostningsfølsomme pipelines: Dataudtræk fra store dokumentkorpora, periodisk batch-opsummering
- Edge- og mobile scenarier: Når latens er kritisk, men ressourcebudgettet er begrænset
Begrænsninger for Gemini 2.5 Flash-Lite
- Preview-status: Kan undergå API-ændringer før GA; integrationer bør tage højde for mulige versionsændringer.
- Ingen on-the-fly finjustering: Kan ikke uploade brugerdefinerede vægte; basér dig på prompt engineering og systemmeddelelser.
- Reduceret kreativitet: Tuneret til deterministiske opgaver med høj gennemløbskapacitet; mindre egnet til åbne genereringsopgaver eller “kreativ” skrivning.
- Ressourceloft: Skalerer lineært kun op til ~16 vCPU'er; derudover aftager gennemløbsgevinster.
- Multimodale begrænsninger: Understøtter billede-/lydinput men med begrænset fidelitet; ikke ideel til tunge visions- eller lydtransskriptionsopgaver.
- Trade-off for kontekstvindue: Selvom den accepterer op til 1 M tokens, kan praktisk inferens i den skala medføre reduceret gennemløb.