

Alibabas seneste fremskridt inden for kunstig intelligens, Qwen3-koder, markerer en betydelig milepæl i det hastigt udviklende landskab inden for AI-drevet softwareudvikling. Qwen23-Coder, der blev afsløret den 2025. juli 3, er en open source, agentisk kodningsmodel designet til autonomt at håndtere komplekse programmeringsopgaver, lige fra generering af standardkode til fejlfinding på tværs af hele kodebaser. Modellen er bygget på en banebrydende mixture-of-experts (MoE)-arkitektur og kan prale af 480 milliarder parametre med 35 milliarder aktiverede pr. token, og opnår en optimal balance mellem ydeevne og beregningseffektivitet. I denne artikel udforsker vi, hvad der adskiller Qwen3-Coder fra andre, undersøger dens benchmark-ydeevne, udpakker dens tekniske innovationer, guider udviklere gennem optimal brug og overvejer modellens modtagelse og fremtidsudsigter.
Hvad er Qwen3‑Coder?
Qwen3‑Coder er den nyeste agentiske kodningsmodel fra Qwen-familien, officielt annonceret den 22. juli 2025. Dens flagskibsvariant, Qwen3‑Coder‑480B‑A35B‑Instruct, er designet som en "mest agentisk kodemodel til dato" og har 480 milliarder parametre i alt med et Mixture‑of‑Experts (MoE)-design, der aktiverer 35 milliarder parametre pr. token. Den understøtter native kontekstvinduer på op til 256 tokens og skalerer til en million tokens gennem ekstrapoleringsteknikker, hvilket imødekommer behovet for forståelse og generering af kode på repo-skala.
Open source under Apache 2.0
I tråd med Alibabas engagement i community-drevet udvikling er Qwen3-Coder udgivet under Apache 2.0-licensen. Denne open source-tilgængelighed sikrer gennemsigtighed, fremmer tredjepartsbidrag og fremskynder implementeringen i både den akademiske verden og industrien. Forskere og ingeniører kan få adgang til forudtrænede vægte og finjustere modellen til specialiserede domæner, fra fintech til videnskabelig databehandling.
Udvikling fra Qwen2.5
Byggende på succesen med Qwen2.5-Coder, som tilbød modeller fra 0.5B til 32B parametre og opnåede SOTA-resultater på tværs af kodegenereringsbenchmarks, udvider Qwen3-Coder sin forgængers muligheder gennem større, forbedrede datapipelines og nye træningsregimer. Qwen2.5-Coder blev trænet på over 5.5 billioner tokens med omhyggelig datarensning og syntetisk datagenerering; Qwen3-Coder videreudvikler dette ved at indtage 7.5 billioner tokens med et kodeforhold på 70%, og udnytter tidligere modeller til at filtrere og omskrive støjende input for overlegen datakvalitet.
Hvad er de primære innovationer, der adskiller Qwen3-Coder?
Flere vigtige innovationer adskiller Qwen3-Coder fra andre:
- Agentisk opgaveorkestreringI stedet for blot at generere snippets kan Qwen3-Coder autonomt sammenkæde flere operationer – læse dokumentation, kalde værktøjer og validere output – uden menneskelig indgriben.
- Forbedret tænkningsbudgetUdviklere kan konfigurere, hvor meget beregning der skal afsættes til hvert trin i ræsonnementet, hvilket giver mulighed for en brugerdefineret afvejning mellem hastighed og grundighed, hvilket er afgørende for kodesyntese i stor skala.
- Sømløs værktøjsintegrationQwen3-Coders kommandolinjegrænseflade, "Qwen Code", tilpasser funktionskaldsprotokoller og tilpassede prompts for at integrere med populære udviklerværktøjer, hvilket gør det nemt at integrere i eksisterende CI/CD-pipelines og IDE'er.
Hvordan klarer Qwen3‑Coder sig sammenlignet med konkurrenterne?
Benchmark-opgør
Ifølge Alibabas offentliggjorte præstationsmålinger overgår Qwen3-Coder førende indenlandske alternativer – såsom DeepSeeks codex-lignende modeller og Moonshot AI's K2 – og matcher eller overgår kodningskapaciteterne hos de bedste amerikanske tilbud på tværs af flere benchmarks. I tredjepartsevalueringer:
- Aider PolyglotQwen3-Coder-480B opnåede en score på 61.8%, der illustrerer stærk flersproget kodegenerering og ræsonnement.
- MBPP og HumanEvalUafhængige tests rapporterer, at Qwen3-Coder-480B-A35B overgår GPT-4.1 både i funktionel korrekthed og kompleks prompthåndtering, især i flertrinskodningsudfordringer.
- 480B-parametervarianten opnåede over 85% udførelsessucces på SWE-Bænk Verificeret suite – overgår både DeepSeeks topmodel (78%) og Moonshots K2 (82%) og matcher Claude Sonnet 4 med 86%.
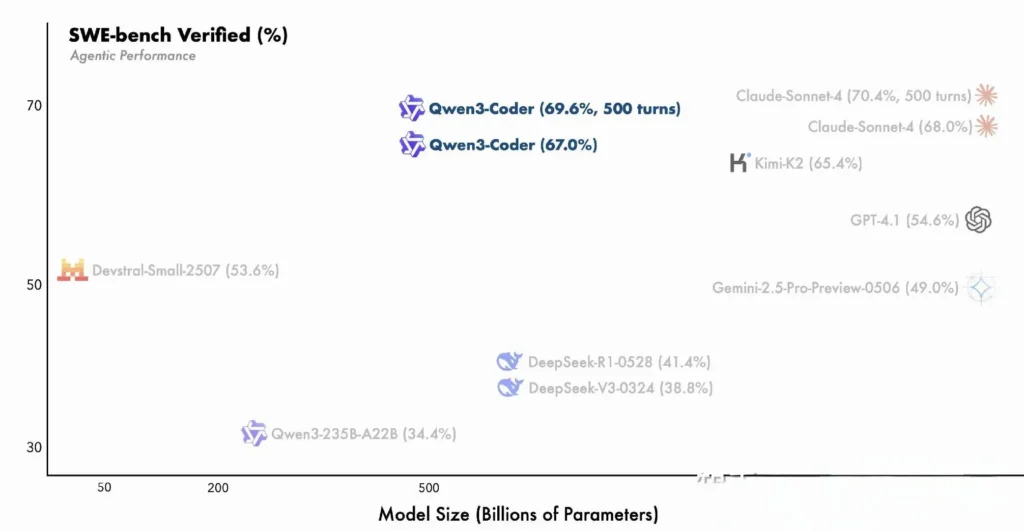
Sammenligning med proprietære modeller
Alibaba hævder, at Qwen3-Coders agentfunktioner stemmer overens med Anthropics Claude og OpenAIs GPT-4 i end-to-end-kodningsworkflows, en bemærkelsesværdig bedrift for en open source-model. Tidlige testere rapporterer, at dens multi-turn-planlægning, dynamiske værktøjskald og automatiserede fejlkorrektion kan håndtere komplekse opgaver - såsom at bygge full-stack webapplikationer eller integrere CI/CD-pipelines - med minimale menneskelige prompts. Disse funktioner styrkes af modellens evne til at selvvalidere gennem kodeudførelse, en funktion, der er mindre udtalt i rent generative LLM'er.
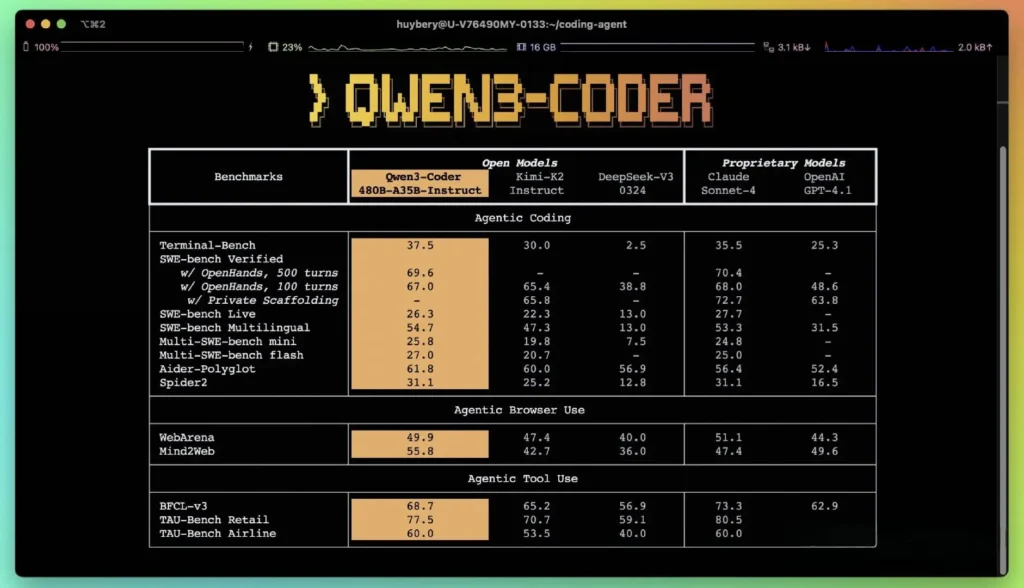
Hvad er de tekniske innovationer bag Qwen3‑Coder?
Arkitektur for blanding af eksperter (MoE)
Kernen i Qwen3‑Coder ligger et avanceret MoE-design. I modsætning til tætte modeller, der aktiverer alle parametre for hvert token, engagerer MoE-arkitekturer selektivt specialiserede undernetværk (eksperter), der er skræddersyet til bestemte tokentyper eller opgaver. I Qwen3‑Coder er 480 milliarder parametre i alt fordelt på tværs af flere eksperter, med kun 35 milliarder parametre aktive pr. token. Denne tilgang reducerer inferensomkostningerne med over 60 % sammenlignet med tilsvarende tætte modeller, samtidig med at den opretholder høj kvalitet i kodesyntese og fejlfinding.
Tænketilstand og ikke-tænketilstand
Qwen3‑Coder låner fra den bredere Qwen3-families innovationer og integrerer en dobbelttilstandsinferens ramme:
- Tænketilstand afsætter et større "tænkebudget" til komplekse ræsonnementsopgaver i flere trin, såsom algoritmedesign eller refaktorering på tværs af filer.
- Ikke-tænkende tilstand giver hurtige, kontekstdrevne svar, der er egnede til simple kodefuldførelser og API-brugskodestykker.
Denne samlede tilstandsskift eliminerer behovet for at jonglere med separate modeller for chatoptimerede versus ræsonnementoptimerede opgaver, hvilket strømliner udviklernes arbejdsgange.
Forstærkningslæring med automatiseret testcase-syntese
En enestående innovation er Qwen3-Coders native 256K token-kontekstvindue - dobbelt så stor som den typiske kapacitet for førende åbne modeller - og understøttelse af op til en million tokens via ekstrapoleringsmetoder (f.eks. YaRN). Dette gør det muligt for modellen at behandle hele repositories, dokumentationssæt eller projekter med flere filer i en enkelt omgang, hvilket bevarer afhængigheder på tværs af filer og reducerer gentagne prompts. Empiriske tests viser, at udvidelse af kontekstvinduer giver aftagende, men stadig meningsfulde gevinster i langsigtet opgaveydeevne, især i miljødrevne forstærkningslæringsscenarier.
Hvordan kan udviklere få adgang til og bruge Qwen3‑Coder?
Udgivelsesstrategien for Qwen3-Coder lægger vægt på åbenhed og nem implementering:
- Vægte af åben kildekode-modellerAlle model-checkpoints er tilgængelige på GitHub under Apache 2.0, hvilket muliggør fuld gennemsigtighed og fællesskabsdrevne forbedringer.
- **Kommandolinjegrænseflade (Qwen-kode)**CLI er udledt fra Google Gemini Code og understøtter tilpassede prompts, funktionskald og plugin-arkitekturer for problemfri integration med eksisterende byggesystemer og IDE'er.
- Cloud- og on-prem-implementeringerForudkonfigurerede Docker-billeder og Kubernetes Helm-diagrammer muliggør skalerbare implementeringer i cloud-miljøer, mens lokale kvantiseringsopskrifter (2-8 bit dynamisk kvantisering) muliggør effektiv on-prem-inferens, selv på standard-GPU'er.
- API-adgang via CometAPIUdviklere kan også interagere med Qwen3-Coder via hostede endpoints på platforme som f.eks. CometAPI, som tilbyder open source (
qwen3-coder-480b-a35b-instruct) og kommercielle versioner (qwen3-coder-plus; qwen3-coder-plus-2025-07-22)til samme pris. Den kommercielle version er 1M lang. - Knusende ansigtAlibaba har gjort Qwen3-Coder-vægtene og tilhørende biblioteker frit tilgængelige på både Hugging Face og GitHub, pakket under en Apache 2.0-licens, der tillader akademisk og kommerciel brug uden royalties.
API- og SDK-integration via CometAPI
CometAPI er en samlet API-platform, der samler over 500 AI-modeller fra førende udbydere – såsom OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i en enkelt, udviklervenlig grænseflade. Ved at tilbyde ensartet godkendelse, formatering af anmodninger og svarhåndtering forenkler CometAPI dramatisk integrationen af AI-funktioner i dine applikationer. Uanset om du bygger chatbots, billedgeneratorer, musikkomponister eller datadrevne analysepipelines, giver CometAPI dig mulighed for at iterere hurtigere, kontrollere omkostninger og forblive leverandøruafhængig – alt imens du udnytter de seneste gennembrud på tværs af AI-økosystemet.
Udviklere kan interagere med Qwen3-koder gennem en kompatibel OpenAI-lignende API, tilgængelig via CometAPI. CometAPI, som tilbyder open source (qwen3-coder-480b-a35b-instruct) og kommercielle versioner (qwen3-coder-plus; qwen3-coder-plus-2025-07-22)til samme pris. Den kommercielle version er 1M lang. Eksempelkode til Python (ved brug af den OpenAI-kompatible klient) med bedste praksis, der anbefaler samplingsindstillinger på temperatur = 0.7, top_p = 0.8, top_k = 20 og repetition_penalty = 1.05. Outputlængder kan strække sig op til 65,536 tokens, hvilket gør den velegnet til store kodegenereringsopgaver.
Til at begynde med, udforsk modellernes muligheder i Legeplads og konsulter API guide for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen.
Lynstart på Hugging Face og Alibaba Cloud
Udviklere, der er ivrige efter at eksperimentere med Qwen3‑Coder, kan finde modellen på Hugging Face under repository'et. Qwen/Qwen3-koder-480B-A35B-instruktionerIntegrationen strømlines via transformers bibliotek (version ≥ 4.51.0 for at undgå KeyError: 'qwen3_moe') og OpenAI-kompatible Python-klienter. Et minimalt eksempel:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
input_ids = tokenizer("def fibonacci(n):", return_tensors="pt").input_ids
output = model.generate(input_ids, max_length=200, temperature=0.7, top_p=0.8, top_k=20, repetition_penalty=1.05)
print(tokenizer.decode(output))
Definition af brugerdefinerede værktøjer og agentworkflows
En af Qwen3‑Coders fremragende funktioner er dynamisk værktøjskaldUdviklere kan registrere eksterne værktøjer – linters, formatters, testrunners – og tillade modellen at kalde dem autonomt under en kodningssession. Denne funktion transformerer Qwen3‑Coder fra en passiv kodeassistent til en aktiv kodningsagent, der er i stand til at køre tests, justere kodestil og endda implementere mikrotjenester baseret på samtaleintentioner.
Hvilke potentielle anvendelser og fremtidige retninger muliggør Qwen3‑Coder?
Ved at kombinere open source-frihed med ydeevne i virksomhedsklassen baner Qwen3-Coder vejen for en ny generation af AI-drevne udviklingsværktøjer. Fra automatiserede koderevisioner og sikkerhedskontrol til løbende refactoring-tjenester og AI-drevne dev-ops-assistenter inspirerer modellens alsidighed allerede både startups og interne innovationsteams.
Softwareudviklingsworkflows
Tidlige brugere rapporterer en reduktion på 30-50 procent i den tid, der bruges på standardkodning, afhængighedsstyring og indledende opbygning, hvilket giver ingeniører mulighed for at fokusere på design- og arkitekturopgaver af høj værdi. Kontinuerlige integrationspakker kan udnytte Qwen3-Coder til automatisk at generere tests, detektere regressioner og endda foreslå ydeevneoptimeringer baseret på kodeanalyse i realtid.
Virksomheder spiller
Efterhånden som virksomheder inden for finans, sundhedsvæsen og e-handel integrerer Qwen3-Coder i missionskritiske systemer, vil feedback-loops mellem brugerteams og Alibabas forskning og udvikling fremskynde forbedringer – såsom domænespecifik justering, forbedrede sikkerhedsprotokoller og strammere IDE-plugins. Derudover opfordrer Alibabas open source-strategi til bidrag fra det globale samfund og fremmer et levende økosystem af udvidelser, benchmarks og biblioteker med bedste praksis.
Konklusion
Kort sagt repræsenterer Qwen3-Coder en milepæl inden for open source AI til softwareudvikling: en kraftfuld, agentisk model, der ikke kun skriver kode, men også orkestrerer hele udviklingspipelines med minimal menneskelig overvågning. Ved at gøre teknologien frit tilgængelig og nem at integrere demokratiserer Alibaba adgangen til avancerede AI-værktøjer og lægger grunden til en æra, hvor softwareudvikling bliver mere og mere samarbejdsorienteret, effektiv og intelligent.
Ofte Stillede Spørgsmål
Hvad gør Qwen3‑Coder "agentisk"?
Agentisk AI refererer til modeller, der kan planlægge og udføre flertrinsopgaver autonomt. Qwen3-Coders evne til at aktivere eksterne værktøjer, køre tests og administrere kodebaser uden menneskelig indgriben eksemplificerer dette paradigme.
Er Qwen3‑Coder egnet til produktionsbrug?
Selvom Qwen3-Coder viser stærk ydeevne på benchmarks og tests i den virkelige verden, bør virksomheder udføre domænespecifikke evalueringer og implementere beskyttelsesforanstaltninger (f.eks. pipelines til outputverifikation), før de integrerer det i kritiske produktionsworkflows.
Hvordan gavner Mixture-of-Experts-arkitekturen udviklere?
MoE reducerer inferensomkostninger ved kun at aktivere relevante undernetværk pr. token, hvilket muliggør hurtigere generering og lavere beregningsomkostninger. Denne effektivitet er afgørende for at skalere AI-kodningsassistenter i cloudmiljøer.