
Qwen3-Max-Preview er Alibabas seneste flagskibs-previewmodel i Qwen3-familien — en model i Mixture-of-Experts (MoE)-stil med over billioner parametre og et ultralangt kontekstvindue på 262k tokens, udgivet som preview til virksomheds-/cloud-brug. Den er rettet mod *dybdegående ræsonnement, forståelse af lange dokumenter, kodning og agentarbejdsgange.
Grundlæggende information og overskrifter
- Navn / Etiket:
qwen3-max-preview(Instruere). - Skala: Over 1 billion parametre (flagskib med billioner af parametre). Dette er den vigtigste markedsførings-/statistiske milepæl for udgivelsen.
- Kontekstvindue: 262,144-symboler (understøtter meget lange input og transskriptioner af flere filer).
- Tilstand(er): Instruktionsafstemt "Instruct"-variant med understøttelse af tænker (bevidst tankekæde) og ikke-tænkende hurtige tilstande i Qwen3-familien.
- tilgængelighed: Forhåndsvisningsadgang via Qwen Chat, Alibaba Cloud Model Studio (OpenAI-kompatible eller DashScope-slutpunkter) og routingudbydere som f.eks. CometAPI.
Tekniske detaljer (arkitektur og tilstande)
- Arkitektur: Qwen3-Max følger Qwen3-designlinjen, der bruger en blanding af tæt + blanding af eksperter (MoE) komponenter i større varianter, plus tekniske valg for at optimere inferenseffektiviteten for meget store parameterantal.
- Tænketilstand vs. ikke-tænketilstand: Qwen3-serien introducerede en tænkemåde (for output i flertrins-tankekædestil) og ikke-tænkende tilstand for hurtigere og mere præcise svar; platformen eksponerer parametre til at slå disse adfærdsmønstre til/fra.
- Kontekstcaching / ydeevnefunktioner: Model Studio-lister kontekstcache understøttelse af store anmodninger for at reducere gentagne inputomkostninger og forbedre gennemløbshastigheden i gentagne kontekster.
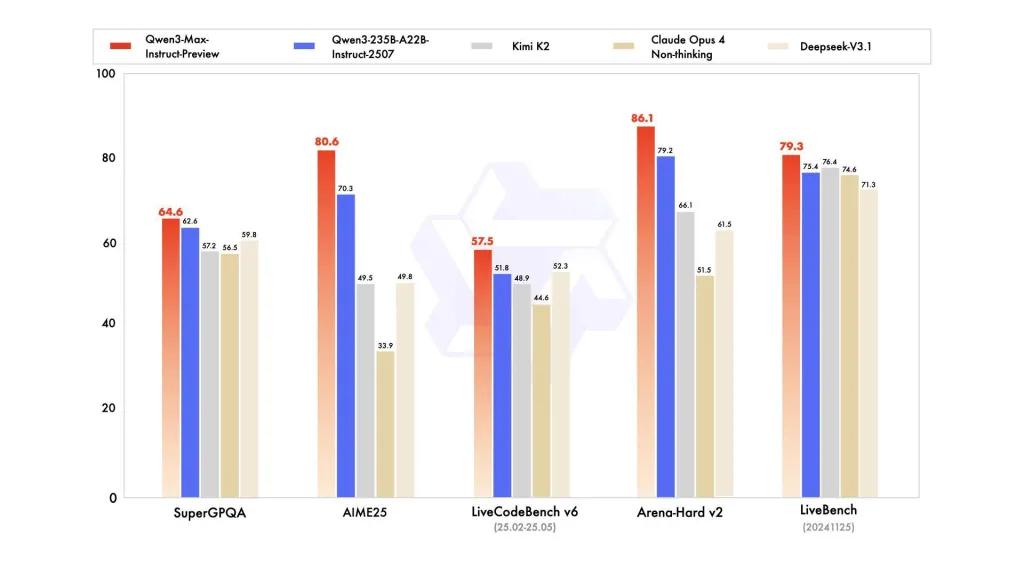
Benchmark ydeevne
Rapporter refererer til SuperGPQA, LiveCodeBench-varianter, AIME25 og andre konkurrence-/benchmark-suiter, hvor Qwen3-Max fremstår konkurrencedygtig eller førende.
Begrænsninger og risici (praktiske og sikkerhedsmæssige noter)
- Opacitet for fuld træningsopskrift / vægte: Som en forhåndsvisning kan de fulde trænings-/data-/vægtudgivelses- og reproducerbarhedsmaterialer være begrænsede sammenlignet med tidligere Qwen3-udgivelser med åben vægt. Nogle Qwen3-familiemodeller blev udgivet med åben vægt, men Qwen3-Max leveres som en kontrolleret forhåndsvisning til cloud-adgang. reducerer reproducerbarheden for uafhængige forskere.
- Hallucinationer og fakta: Leverandørrapporter hævder reduktioner i hallucinationer, men brugen i den virkelige verden vil stadig finde faktuelle fejl og overdrevne påstande — standard LLM-forbehold gælder. Uafhængig evaluering er nødvendig før implementering med høj risiko.
- Omkostninger i stor skala: Med et stort kontekstvindue og høj kapacitet, tokenomkostninger kan være betydelig for meget lange prompts eller produktionsgennemstrømning. Brug caching, chunking og budgetkontroller.
- Overvejelser vedrørende regulatoriske forhold og datasuverænitet: Virksomhedsbrugere bør kontrollere Alibaba Clouds regioner, dataophold og overholdelse af regler, før de behandler følsomme oplysninger. (Model Studio-dokumentationen indeholder regionsspecifikke slutpunkter og noter.)
Brug sager
- Dokumentforståelse / opsummering i stor skala: juridiske briefinger, tekniske specifikationer og vidensbaser med flere filer (fordel: 262K token vindue).
- Langkontekst-kodeargumentation og kodeassistance på repository-skala: Forståelse af kode i flere filer, store PR-gennemgange, forslag til refactoring på repository-niveau.
- Kompleks ræsonnement og tankekædeopgaver: matematikkonkurrencer, planlægning i flere trin, agentiske arbejdsgange, hvor "tænkende" spor hjælper sporbarheden.
- Flersproget, virksomhedsbaseret spørgsmål og svar samt struktureret dataudtrækning: understøttelse af store flersprogede korpora og strukturerede outputfunktioner (JSON/tabeller).
Sådan kalder du Qqwen3-max-preview API fra CometAPI
qwen3-max-preview API-priser i CometAPI, 20 % rabat på den officielle pris:
| Indtast tokens | $0.24 |
| Output tokens | $2.42 |
Påkrævede trin
- Log ind på cometapi.com. Hvis du ikke er vores bruger endnu, bedes du registrere dig først
- Få adgangslegitimations-API-nøglen til grænsefladen. Klik på "Tilføj token" ved API-tokenet i det personlige center, få token-nøglen: sk-xxxxx og send.
- Hent url'en til dette websted: https://api.cometapi.com/
Brug metoden
- Vælg "qwen3-max-preview"-slutpunktet for at sende API-anmodningen, og angiv anmodningsteksten. Anmodningsmetoden og anmodningsteksten kan hentes fra vores hjemmesides API-dokumentation. Vores hjemmeside tilbyder også en Apifox-test for din bekvemmelighed.
- Erstatte med din faktiske CometAPI-nøgle fra din konto.
- Indsæt dit spørgsmål eller din anmodning i indholdsfeltet – det er det, modellen vil reagere på.
- . Behandle API-svaret for at få det genererede svar.
API-kald
CometAPI leverer en fuldt kompatibel REST API – til problemfri migrering. Vigtige detaljer til API-dok:
- Kerneparametre:
prompt,max_tokens_to_sample,temperature,stop_sequences - Endpoint:
https://api.cometapi.com/v1/chat/completions - Modelparameter: qwen3-max-forhåndsvisning
- Godkendelse:
Bearer YOUR_CometAPI_API_KEY - Indholdstype:
application/json.
udskifte
CometAPI_API_KEYmed din nøgle; bemærk basis-URL.
Python (anmodninger) — OpenAI-kompatibel
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Tip: brug max_input_tokens, max_output_tokensog Model Studios kontekstcache funktioner ved afsendelse af meget store kontekster for at kontrollere omkostninger og gennemløb.
Se også Qwen3-koder